Software Architecture for High Availability in the Cloud
by Brian Jimerson
Engineering enterprise applications to ensure the highest level of availability and fault tolerance in the cloud.
Published June 2012
Introduction
Designing for fault tolerance in enterprise applications that will run on traditional infrastructures is a familiar process, and there are proven best practices to ensure high availability. However, cloud-based architectures tend to fail in a quite different way than traditional, machine-based architectures.
Recent events suggest that most cloud-based applications are not designed for traditional data center architectures, and when inevitable failures occur, these applications are unable to survive infrastructure outages. This article takes a look at some of the paradigm shifts in designing fault tolerance from machine-based architectures to cloud-based architectures, and how enterprise applications need to be engineered to ensure the highest level of availability and fault tolerance in the cloud.
Background
The term cloud computing can mean many different things in today's technologies. Cloud computing encompasses everything from consumer-oriented media and file synchronization to traditional desktop replacement to an enterprise's entire IT infrastructure. For this article, cloud computing will refer to the delivery of compute, storage, application platforms, and software as a set of services to support an organization's business applications.
This delivery of IT as a service has several well known benefits, with significant potential for a true revolution in enterprise IT. Instead of requiring IT departments to allocate and manage physical or virtual machines to support business applications and resources, cloud computing allows IT to be delivered through an abstract set of services, enabled by the sharing of resources and economies of scale. This has several benefits. Some of the key advantages are:
- User self service and provisioning
- Rapid time to market
- Reduced operational maintenance and administration
- Focus on delivering innovation through software
- Reduction of capital investment in hardware and software
- Pay as you go models for lines of business
There are several levels of abstraction of application infrastructure, ranging from compute and storage abstraction all the way to abstracting all layers of applications. The three most common levels of abstraction are:
- Infrastructure as a Service (IaaS) - Hardware for compute, storage, network, and similar functions is delivered as a service. Examples of IaaS date back to mainframes.
- Platform as a Service (PaaS) - Application platform components, such as application runtimes, databases, and messaging infrastructure, are delivered as a service. Oracle Exalogic, Oracle Exadata, and Oracle SuperCluster are prime examples of products that can be used to create an enterprise-ready PaaS. The Oracle Cloud public cloud offering also provides Platform services with the Java Cloud Service and the Database Cloud Service.
- Software as a Service (SaaS) - Core business applications, such as email, CRM, HCM, and office ERP applications, are delivered as a service. Examples of enterprise SaaS include Oracle Fusion HCM Cloud Service, Oracle Fusion CRM Cloud Service, Oracle RightNow CX Cloud Service, and Oracle Taleo Cloud Service.
The levels of abstraction for these service models are shown in Figure 1.

Figure 1 -Levels of abstraction in cloud computing service models
There are also several types of cloud deployment models, differentiated by the cloud infrastructure's provider and physical location. The three most common cloud deployment models are:
- Public Cloud - Public cloud computing resources are made available to the general public by the provider. Typically, providers leverage their existing infrastructure to provide cloud resources at a scale to support the general public.
- Private Cloud - Private cloud computing resources are only available to a finite group of consumers, typically an organization. The cloud infrastructure may be running in an organization's physical data center, or in a third-party co-location facility.
- Hybrid Cloud - A hybrid cloud is a mixture of public and private cloud resources. For example, an organization may use its private cloud for day-to-day operations, and then scale out to a public cloud for peak resource requirements.
Figure 2 depicts the relationship between public, private, and hybrid clouds.
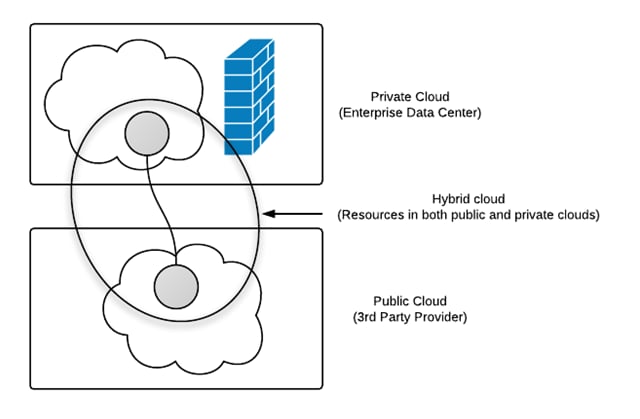
Figure 2 – Cloud Deployment Model
Machine vs. Cloud Architecture Failures
Failures in traditional, machine-based (physical and virtual) architectures tend be hardware and operating system oriented, and most high-availability engineering is focused on providing redundant hardware and operating systems to provide fault tolerance. For example, clustered application servers, master/slave database replication, redundant network cards, and RAID disk arrays are techniques to provide redundancy to possible points of failure in the systems.
Note that in this context, machine-based architectures refer to systems that are built on physical or virtual machines in a traditional data center or co-location facility. These architectures can be thought of as a vertical set of hardware and software systems, where each vertical slice is a redundant piece of hardware or server. So, if one of the vertical slices (application/machine instances) fails for some reason, the other nodes or slices can still handle execution of the application. Figure 3 depicts this logical architecture.

Figure 3 Machine-based application architecture
This type of architecture is perfectly appropriate for traditional data centers and application infrastructure. Most failures that occur in these architectures are typically either hardware-based or resource-based, and they are usually isolated to one of the nodes in the cluster. Providing redundancy of the physical and virtual nodes addresses the issue of one of the nodes being unavailable because of some sort of failure. For example, in this scenario, if network interface for Application Node 2 fails, Application Nodes 1 and 3 can continue to serve requests from the load balancer.
One of the big technical shifts in cloud computing for enterprises is the way that clouds are designed to provide services. Traditional data centers provide runtime facilities, like application servers and databases, in discrete, atomic units. These discrete, atomic units are then put together in a logical cluster, where each unit or node is aware of other members of the cluster.
Cloud architectures, in contrast, are much different. Cloud architectures are intended to abstract away things like storage, data persistence, and runtime dependencies. They're also designed to support a large degree of multi-tenancy and scalability.
In order to meet these challenges, cloud-based architectures tend to be more of a set of horizontal layers of logical services, woven together to form a fabric of components comprising the application. These horizontal layers are not instances of hardware; rather they are zones of services provided by the cloud infrastructure. These layers may be UI layers, business logic layers, NoSQL data layers, RDBMS data layers, and so on. The contrasted logical cloud architecture is shown in Figure 4.

Figure 4 – Cloud-based application architecture
This fabric of horizontal services is what provides the near-infinite scalability, on-demand services, performance, and cost-effectiveness of cloud-based applications. However, it also dramatically changes the types of failures that will occur in applications. Instead of nodes of vertical sets of hardware failing, failures in cloud-based architectures will usually involve one or more of the horizontal fabrics. No amount of redundant hardware design will help to insure survival in these kinds of failures. Instead, a different approach to fault tolerant design needs to be adopted in cloud architectures.
Cloud Design Considerations
Given the most likely types of failures in cloud architectures, the rest of this article focuses on design considerations that can fundamentally affect fault tolerance and high availability in cloud computing.
Multiple zones
In cloud computing, Zones refer to groups of cloud computing resources that are physically isolated from one another. This provides redundant cloud computing facilities to which applications can be deployed. One of the most effective and straightforward ways to design for fault tolerance in the cloud is to use multiple zones for applications. Failures in the cloud are often involve a complete set of services in a given zone; for example the database service in the east zone might fail completely and be unavailable to consumers. If a service is distributed among several zones, consumers of that service can fail over to other zones.
This approach adds complexity to the application and configuration, but it addresses one of the common types of failures in cloud computing. To achieve this approach, service consumers must be able to dynamically reach different cloud service endpoints.
Distributed data management platforms
Distributed data management platforms, such as Oracle Coherence, have gained in popularity with the adoption of cloud-based architectures. A distributed data management system is a highly scalable, low latency, distributed and replicated data system. These systems are designed to provide access to data at in-memory speeds, can auto-shard and replicate data globally, and provide massive scale through peer-to-peer clustering.
There are a number of use cases in cloud architectures that can benefit greatly from Oracle Coherence:
Global data replication
One of the challenges with having geographically distributed zones is that data must be made available to all of the zones. Making database calls to a geographically distant zone would typically be very slow and costly. A typical approach is to replicate data between zones. However, this leads to out-of-sync data, and typically requires continuous replication of a large amount of data.
To address this issue, products such as Oracle Coherence use a technique known as sharding. Through sharding, a data set is broken into small pieces and distributed across a large cluster in such a manner that an entire data set can be reconstructed even if there is failure of individual nodes. This means that only very small chunks of data are replicated across zones at any time, while full data sets are always available in the local zone.
Event driven applications
Many modern, cloud-based applications require event driven notifications be delivered to clients, whether the clients are end user applications, or other external applications. For example, a social network application may require that an end user is notified when one of his or her friends posts a message. A typical approach to support this requirement involves polling a server-side resource for updates on a schedule from the client.
This polling operation is very taxing on the server-side resource, however, as it has to constantly respond to each individual client, even if there are no updates. Oracle Coherence provides a feature, called a continuous query, that can be used to address this need. A client can register a query with Coherence, and when the results of the query change, Coherence can notify the client. This reduces the polling load that would normally be put on the server-side resource.
Client caching and offline access
One of the trademarks of modern, cloud-based applications is the number of end-user channels that must be supported. For example, many business applications now support web browsers, tablets and other mobile devices, and even thick clients at the same time. Many of these end-user devices are frequently in offline mode, or use a low-bandwidth network connection. This means that the application design must account for limited or slow access to cloud resources.
Products such as Oracle Coherence can be used to address these limitations. Since Coherence uses a peer-to-peer, sharded clustering mechanism, a Coherence node can be installed on the client device to provide a local cache of application data. The client can still have access to application data through a local cache, and the cache can be updated when the client is online or has a higher bandwidth connection.
Graceful Degradation
Distributed, cloud-based applications should assume that some part of their system may be unavailable. This unavailability should not render the whole system useless. Functional requirements should account for these service outages and identify points of interaction where failures may occur. The result of a failure should be accounted for and still allow the rest of the system to function. This concept is known as graceful degradation.
As an example, consider an application that allows users to view and purchase music online through various clients, including mobile devices and PCs. The user of this system could perform the following functions on all devices:
- Search for artists
- View album and artist information collected from third-party sites
- Preview music tracks
- View artist social network activity
- Purchase music tracks
Now let's assume that for some reason, album and artist information becomes unavailable. This may be due to limited bandwidth of a mobile device, or one or more of the services being down. This situation should not render the whole system useless, or worse yet, display an error to the user. Instead, the requirements should account for each of these possible failures. In this case a message might be displayed saying that the service is temporarily unavailable. However, the user should still be able to preview and purchase tracks.
Asynchronous Messaging
Asynchronous messaging is a well known design principle in traditional applications. It promotes loose coupling between system components and interactions, and ensures that long running processes don't impact a user's experience.
These same principles are even more important in cloud-based applications. As we've discussed, cloud applications are highly distributed, both logically and geographically. They also typically have to support a large number of different clients. Using asynchronous messaging between these distributed components, when appropriate, helps ensure that these components aren't unnecessarily dependent on the availability of other components, tight coupling of endpoints, latency in networks, or other factors.
When asynchronous messaging is used, a product like Oracle WebLogic 12c should be leveraged. Messaging in WebLogic is durable and backed by persistent message stores, allowing messages to be restored and re-delivered in the event of a a failure. This also lessens the burden of message delivery addressing from applications, which can be managed centrally within WebLogic.
Atomic and Idempotent Services
The services comprised in cloud applications should always be designed to be atomic and idempotent. By definition, atomic services are services whose functionality can't be logically split into smaller services; in other words, their scope of responsibility is already as small as possible. Idempotent services are services that are guaranteed to be safe to be invoked multiple times, without affecting their outcome; a client can feel confident in calling an idempotent service several times without unintended consequences.
Atomicity and idempotence are very complementary qualities that help to ensure recovery from the absence of services. Clients can safely invoke atomic, idempotent services several times until a satisfactory result is obtained; they can invoke multiple instances of an atomic, idempotent service safely; and they can recover functionally if one of these services is completely unavailable.
As an example of an atomic and idempotent service, let's consider a credit card processing service used by an application. To be atomic, the service should only perform the processing of a payment, and should require only the data needed to do so. It should not perform additional tasks, such as updating a billing address that was changed by the user. Being atomic ensures that the minimum amount of functionality is lost if the service is unavailable.
To be idempotent, the service should be capable of multiple invocations. If the same data is passed, the service should not re-charge the credit card. Being idempotent ensures that when service availability is restored, no unintended consequences are realized if the service is invoked in another zone.
Conclusion
Fault tolerance and high availability are necessary attributes of all enterprise applications; any system downtime can mean a loss of revenue and stakeholder confidence.
Given the importance of fault tolerance in the success of applications, it should be one of the highest priorities given to implementations. However, architects and engineers who are used to traditional data center architectures need to shift their focus from hardware and operating system redundancies to software-oriented aspects for high availability attributes.
IT-as-a-Service offers the promise of a sharp focus on software and innovation, and on reducing or eliminating the potential impact of problems with the underlying computing platform. However, the failure to focus on a software application's fault tolerance can have devastating effects. This aspect of cloud computing warrants greater attention if the full potential of cloud architectures is to be realized.
Brian Jimerson is a Senior Technical Architect for Cleveland, Ohio-based Avantia, Inc., a custom solutions provider and an Oracle Gold Partner. Brian specializes in middleware and web infrastructure solutions, enterprise integration patterns and practices, and enterprise methodologies.