Character Conversions from Browser to Database
By John O'Conner,
January 2006
In route to their final storage destination on the World Wide Web, characters move through various layers of programming interfaces and can cross software and hardware boundaries. This article provides helpful hints and best practices for accurately transporting character data from browser to database and back again.
Contents
Most operating systems, application development languages, and platforms have come a very long way in internationalization. Some things are easy, like entering your name into a Swing text field. Keyboards, input methods, and host software collaborate to create the correct characters whether your name is John, José, or 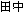 (Tanaka). Unfortunately, although entering non-ASCII text in a browser can be as easy as entering it into a Swing component, accurately transmitting it over the web can be complicated. As no industry standard governs how application data should be encoded in either
(Tanaka). Unfortunately, although entering non-ASCII text in a browser can be as easy as entering it into a Swing component, accurately transmitting it over the web can be complicated. As no industry standard governs how application data should be encoded in either GET or POST commands, the trip through various layers of programming interfaces can transform character data into meaningless gibberish. Furthermore, web server and database administrators often know very little about character-encoding transformations that affect data fidelity as text moves from browser to database.
Browser Display and Form Submission
Modern browsers can display most text correctly as long as the HTML page provides sufficient hints for the browser to select and use appropriate fonts and encodings to interpret the characters. The following image shows a possible display when you do not provide any character encoding information to the browser. In this case, characters are received via the HTML page without data loss but are subsequently interpreted incorrectly.
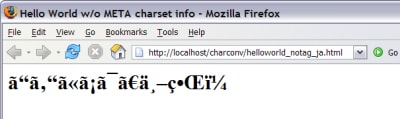
Figure 1. No Character-Encoding Information to Browser
In the next image, the browser (Firefox 1.07) mistakenly interprets the file content as ISO 8859-1 encoded text, which is incorrect. Although most browsers allow a user to change or override these settings for any particular document, this expectation is unreasonable for typical users.
Figure 2. Incorrect Character Encoding Information
The text is actually UTF-8 (a Unicode encoding) text. After placing this information in the HTML code as a <meta> tag, the browser correctly displays the Japanese greeting for "Hello, World!"
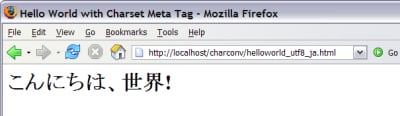
Figure 3. Correct Character-Encoding Information to Browser
The correctly described HTML file is shown below. Notice that the <meta> tag contains a content attribute that tells the browser that the file has type text/html with charset=UTF-8. The keyword charset is used within the content attribute to communicate the HTML file's character encoding. Use language tags wherever possible so that browsers can find and utilize language-specific glyphs when appropriate. For example, both Chinese and Japanese use many of the same characters. Because glyphs differ significantly for some characters in these and other languages, language tags help browsers find the most appropriate fonts for presentation.

Japanese Language Tag
If you generate pages with JavaServer Pages (JSP) technology, you still must indicate the character encoding of the generated HTML page. You can do this with either the JSP page directive or with the HTML <meta> tag. The JSP page tag should be the first element of your JSP file and should contain a contentType attribute with the charset setting. The pageEncoding attribute is used by the JSP compiler to help it know the encoding of the JSP page itself.
<%@page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8"%>
...
Now your pages are correctly encoded, and they communicate that information to the browser. Great, but nothing has been transmitted from the browser yet. As already shown, browsers learn a page's encoding information from charset information stored in the HTTP header or in the HTML <meta> tag. They use this same information when encoding form data for GET or POST commands they send back to a server. If an accept-charset attribute exists in the HTML form tag, browsers will use that setting instead. Again, browsers encode form data in the same encoding as the page or the form itself.
The following JSP shows a page that indicates that its contents are encoded as ISO-8859-1, a commonly used character encoding that handles languages and scripts used in many countries of Western Europe and the Americas. The page generates an HTML form that asks for a user's name. On submission, the same page processes the incoming GET command and prints a greeting to the user indicated in the NAME parameter.
<% @page pageEncoding="ISO-8859-1" contentType="text/html; charset=ISO-8859-1" %>
<html lang="en">
<head>
<title>Say Hello!</title>
</head>
<body>
<%
String name = request.getParameter("NAME");
if (name == null || name.length() == 0) {
name = "World";
}
%>
<form action="sayhello.jsp" method='GET'>
<label for='NAME'>Name</label><input type="text" id="NAME" name="NAME"/>
<button type="submit">Submit</button>
</form>
</body>
</html>
Type in John and click the Submit button. The browser creates and uses the following URL to send information to the server:
http://localhost/sayhello.jsp?NAME=John
Fine so far. Now, type in José and click the Submit button. The resulting URL is shown again below:
http://localhost/charconv/sayhello.jsp?NAME=Jos%E9
Although the resulting NAME parameter looks a little different, it is correct. The %E9 string is a URL-encoded character: the hexadecimal integer value of the character's codepoint in the ISO 8859-1 charset. Servers that expect GET and POST data in the 8859-1 charset have no problem decoding this URL-encoded entity.
In brief, URL-encoding is a web standard for URLs that requires all non-ASCII characters and specific ASCII characters to be encoded as hexadecimal strings in the form %HH. Unfortunately, that same standard does not prescribe which charset to use when encoding the data.
What happens when the page's charset does not contain a character entered into the form? Imagine that a user in Japan, Korea, or China enters their name into the same JSP page shown above. The characters most likely do not appear in the ISO 8859-1 encoding. Encoding them to ISO 8859-1 will present a significant problem to the browser, and each browser handles this problem differently.
Given the Japanese name ![]() (Tanaka), the Firefox version 1.07 browser produces the following
(Tanaka), the Firefox version 1.07 browser produces the following GET URL:
http://localhost/charconv/sayhello.jsp?NAME=%26%2330000%3B%26%2320013%3B
This URL is odd at first glance, but you can decipher its meaning quickly. First, the Firefox browser knows that it can't represent ![]() in the 8859-1 charset
it doesn't even try. Instead, it encodes the characters as numeric character references. Other browsers may behave differently, opting to generate question marks or even to prevent their input entirely. In this case, however, each character is encoded into
in the 8859-1 charset
it doesn't even try. Instead, it encodes the characters as numeric character references. Other browsers may behave differently, opting to generate question marks or even to prevent their input entirely. In this case, however, each character is encoded into &#D; form, where D represents the character's decimal codepoint value in the Unicode character set. The ![]() character has value 30000.
character has value 30000. ![]() has value 20013. Creating numeric character references, we produce the following parameter string:
has value 20013. Creating numeric character references, we produce the following parameter string:
NAME=田中
Now the URL-encoding takes place, to convert the special characters &, #, and ; characters into their %HH equivalents.
NAME=%26%2330000%3B%26%2320013%3B
If your JSP page retrieves this parameter and simply returns it to the browser, there is no apparent data loss. Although the page's character encoding is still 8859-1, the browser understands numeric character references too, and it will do its best to display the Japanese appropriately. However, there is still a problem lurking here. Although server-side code that processes GET and POST commands typically understand URL-encoded strings, they rarely understand numeric character references. Most servlet code that reads the previous NAME parameter will decode the string to find 田中 and will not know that this represents anything other than the literal characters. In other words, the real characters for won't be discovered unless you've intentionally planned for this situation. Don't send numeric character references instead of actual codepoint or encoding values. Doing so would allow potential data loss as the character continues through the application.
To remedy this problem, always select an HTML page encoding that can handle all characters that you intend to process. If you expect to have multilingual users and hope to process multiple scripts, use a character encoding that represents those scripts. UTF-8 is a Unicode character encoding, and it can correctly represent all characters in active use throughout the world. Using UTF-8 in the page instead of 8859-1, the browser produces a different URL.
http://localhost/charconv/sayhello.jsp?NAME=%E7%94%B0%E4%B8%AD
This is a correctly encoded NAME parameter that uses the UTF-8 charset. UTF-8 encodes ![]() with 3 bytes per character. Since each byte has a value outside the ASCII range, the browser URL-encodes the values, producing the
with 3 bytes per character. Since each byte has a value outside the ASCII range, the browser URL-encodes the values, producing the %HH form for each byte as shown above. A server that expects UTF-8 form data will be able to handle the parameter correctly.
Web Server Processing
Although current browsers take hints from the page or form encoding and send form data back to the server in the same encoding, most web servers remain blissfully unaware of the character-encoding choice. They typically assume that the encoding is ISO-8859-1. Even if an application goes through the trouble to URL-encode a GET parameter in UTF-8 , the server (let's say Tomcat 5.5.9 or Sun Java System Application Server 8.1) will assume encoding 8859-1. The result is that text data becomes mangled almost immediately as it travels through the various tiers of even a simple web-based application.
When you change the previous JSP technology code to use the UTF-8 charset, the new code appears as follows.
<%@page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>
<html>
<head>
<title>Say Hello!</title>
</head>
<body>
<%
String name = request.getParameter("NAME");
if (name == null || name.length() == 0) {
name = "World";
}
%>
<form action="sayhello.jsp" method='GET'>
<label for='NAME'>Name</label><input type="text" id="NAME" name="NAME"/>
<button type="submit">Submit</button>
</form>
</body>
</html>
Now type in "José" and submit. The GET URL will look like this.
http://localhost/sayhello.jsp?NAME=Jos%C3%A9
The %C3%A9 is the URL-encoded UTF-8 representation of José. No problem. The browser takes its hint from the contentType setting where UTF-8 is specified as the character encoding. The browser displays the following text.
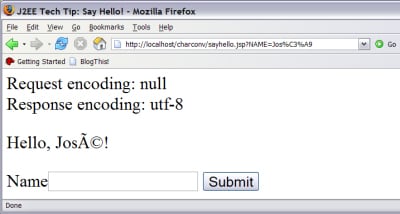
Figure 4. UTF-8 Character Encoding
Notice the response text: Hello, José! That's not right. What happened? Although the browser is correctly sending the GET data, the web server incorrectly assumed character-encoding 8859-1 as it read the NAME parameter Jos%C3%A9 from the URL. From its perspective, the %C3 entity represents the encoded value 0xC3 (Ã) in ISO-8859-1. %A9 is 0xA9 (©) in ISO-8859-1. Hmmph
but the content type was explicitly set in the JSP tag!
There is no published standard that prescribes how to communicate charset choice for GET and POST data. How should it be resolved? Some servers do try to address this. Setting URIEncoding="UTF-8" in Tomcat's connector settings within the server.xml file communicates the character-encoding choice to the web server, and the Tomcat server correctly reads the URL GET parameters correctly. It then sends out "Hello, José!" or ![]() as expected. On Sun Java System Application Server 8.1, you can include
as expected. On Sun Java System Application Server 8.1, you can include <parameter-encoding default-charset="UTF-8"/> in the sun-web.xml file. The correct interpretation of the URL is shown in the following image.
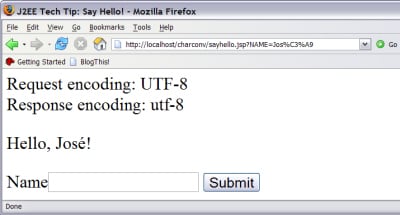
Figure 5. URL Interpretation
What if you want to POST non-ASCII data? All is well since you set that URIEncoding flag, right? Wrong. Tomcat doesn't use the URIEncoding flag for POSTed form data. So, what does it use? ISO-8859-1.
So now, you're back to where you started, and the simple application still greets Mr. ç°ä, instead of Mr. ![]() . Not good. Sun's application server, however, does correctly interpret both
. Not good. Sun's application server, however, does correctly interpret both GET and POST data after setting the parameter-encoding tag as shown earlier, so this coding works well for users on that system.
Unfortunately, these solutions are completely server dependent, and you can't always control where your applications will be deployed. Fortunately, server-independent solutions exist.
Perhaps the most basic server-independent solution is to set a context parameter indicating the character encoding choice for all forms in the application. Then your application can read the context parameter and can set the request character encoding before reading any request parameters. You can set the request encoding in either a Java Servlet or in JSP syntax.
Setting the context parameter is done in the WEB-INF/web.xml file.
<context-param>
<param-name>PARAMETER_ENCODING</param-name>
<param-value>UTF-8</param-value>
</context-param>
Add the following code just before reading any parameters in the previous JSP file.
String paramEncoding = application.getInitParameter("PARAMETER_ENCODING");
request.setCharacterEncoding(paramEncoding);
From a control servlet, you can read the parameter during servlet initiation and set the encoding before processing the parameters:
public class MsgHandler extends HttpServlet {
private String encoding;
public void init() throws ServletException {
ServletConfig config = getServletConfig();
encoding = config.getInitParameter("PARAMETER_ENCODING");
}
protected void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
if (encoding != null) {
request.setCharacterEncoding(encoding);
}
...
}
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
processRequest(request, response);
}
}
Now whether you GET or POST form data, your processing JSP or servlet code can correctly read parameters because you've explicitly told the web server which character encoding to use when processing the request.
Database Settings
Assuming your data has survived so far through the data-mangling gauntlet of browser encoding and web server processing, the database represents the last transformation hurdle for character data. To safely place data into the database and retrieve it unscathed, you must configure the database system to store data in a character encoding that can represent all the characters supported by the browser and your middle-tier business logic. Since UTF-8 has been used so far, it makes sense to continue that choice in the database. Otherwise, data will be irreversibly lost when you try to store text that contains characters that don't exist in the database's character encoding choice.
The following image shows such data loss (when the database character encoding is not a superset of the browser and middle-tier charset). In this situation, the browser and middle tier use UTF-8, but the database is configured for ASCII.
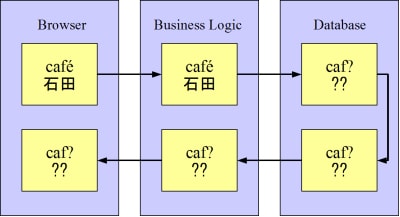
Figure 6. Database Configured for ASCII
Once you update your database character set to UTF-8, however, data migrates from the browser to the database and back again with complete fidelity.
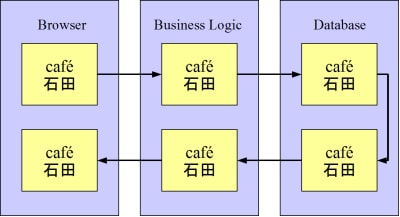
Figure 7. Database Configured for UTF-8
Most modern database systems support Unicode. Two popular relational database products, Oracle and MySQL, both provide full UTF-8 and UTF-16 encoding support in their most recent versions. If you have the opportunity to set up your application's database schema, seriously consider UTF-8 as your database character encoding. If you're in the situation that your database uses a different, more limited character encoding, and you experience data loss as described, you should consider migrating the encoding to UTF-8. Consult your database vendor for detailed instructions about performing the migration.
Summary
The trip from browser to database has several points of potential data loss. Text data often transforms through three or more charset encodings, and each transformation can cause irreversible data loss. To avoid this problem, follow these rules:
- Always provide character encoding information in your HTML or JSP pages by using a HTML
<meta>tag or a JSP @page tag. This information tells the browser how to interpret your page's text. - Use an HTML character encoding that can handle all your multilingual and writing script needs. UTF-8 is a good choice for many situations because it can represent a wide variety of scripts.
- Tell the web server what character encoding to use when processing request parameters. Do this with a servlet initialization parameter or context parameter.
- Use a database character encoding that is a superset of any encoding you use in your application. Again, an encoding such as UTF-8 or UTF-16 is a good choice.
For More Information
For more information, please see the following materials: