Pivot y Unpivot: Una de las principales características de Oracle Database
Pivot y Unpivot
Presente información en un informe con referencias cruzadas con formato de planilla de cálculo a partir de cualquier tabla relacional usando código SQL sencillo, y almacene datos de una tabla con referencias cruzadas en una tabla relacional.
Ver el Índice de la serie (en inglés)
Pivot
Como usted sabe, las tablas relacionales se presentan en pares de columna y valor. Consideremos el caso de una tabla llamada CUSTOMERS.
SQL> desc customers
Name Null? Type
---------------- -------- ------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
STATE_CODE VARCHAR2(2)
TIMES_PURCHASED NUMBER(3)Cuando se selecciona esa tabla:
select cust_id, state_code, times_purchased
from customers
order by cust_id;los datos de salida se presentan así:
CUST_ID STATE_CODE TIMES_PURCHASED
------- --------- ---------------
1 CT 1
2 NY 10
3 NJ 2
4 NY 4
...
etcétera ...Nótese que los datos están representados como filas de valores: para cada cliente, el registro muestra su estado de residencia y las veces que compró en la tienda. A medida que el cliente compra nuevos artículos en la tienda, se actualiza la columna times_purchased.
Ahora veamos cómo podría obtenerse un informe de la frecuencia de compras por estado, es decir, cuántos clientes compraron algo solo una vez, dos veces, tres veces, etc., de cada estado. En la versión habitual de SQL, se puede incluir la siguiente instrucción:
select state_code, times_purchased, count(1) cnt
from customers
group by state_code, times_purchased;Los datos de salida se presentan así:
ST TIMES_PURCHASED CNT
-- --------------- ------
CT 0 90
CT 1 165
CT 2 179
CT 3 173
CT 4 173
CT 5 152
...
etcétera ...Esa es la información que usted necesita, pero su formato dificulta la lectura. Una manera mejor de presentar los mismos datos puede ser mediante informes con referencias cruzadas, en los que pueden organizarse los datos verticalmente y la lista de estados horizontalmente, como en una planilla de cálculo:
Times_purchased
CT NY NJ ...
etcétera ...
1 0 1 0 ...
2 23 119 37 ...
3 17 45 1 ...
...
etcétera ...Antes de la aparición de Oracle Database 11g, para realizar esa acción debía emplearse algún tipo de función de decodificación para cada valor y escribir cada valor como una columna independiente. Sin embargo, esa técnica no es muy intuitiva.
Afortunadamente, ahora existe una nueva y útil característica, PIVOT, para reordenar datos y presentar los resultados de las consultas como tabla de referencias cruzadas, con el operador pivot. La sintaxis de la consulta es la siguiente:
select * from (
select times_purchased, state_code
from customers t )
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
order by times_purchased
/Los datos de salida se presentan así:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ------ ------ ------ ----- -----
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
...
etcétera ...En el ejemplo se ve la practicidad del operador pivot. Los valores de state_code se presentan en la fila de encabezado, y no en una columna. A continuación se ilustra la misma salida en formato de tabla tradicional:

Figura 1 Representación en tabla tradicional
En un informe con referencias cruzadas, se desea trasponer la columna Times Purchased con la fila de encabezado como se muestra en la Figura 2. La columna se convierte en fila, como si se la rotara 90º en sentido antihorario, y pasa a ser el encabezado. Esa rotación figurada debe tener un punto de giro y en este caso ese punto es la expresión count(state_code).
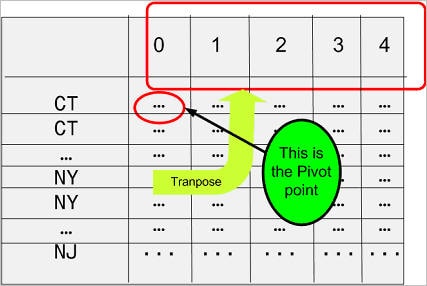
Figura 2 Representación reordenada
A continuación se detalla la expresión que debe incluirse en la consulta:
...
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO') )
...La segunda línea, for state_code ..., limita la consulta a los valores enumerados. Esa línea es necesaria, por lo que desafortunadamente deben conocerse todos los valores posibles de antemano. Esa restricción es más laxa en el formato XML de la consulta, descrito más adelante en este artículo.
Nótense las filas de encabezado en la salida:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- --------- ----- ----- ------ ------Los encabezados de cada columna son los datos de la tabla en sí: los códigos de estado. Si bien esos códigos son bastante conocidos, podría preferirse mostrar los nombres de los estados en lugar de los códigos ("Connecticut" en lugar de "CT"). En tal caso, se debe hacer un pequeño ajuste en la cláusula FOR de la consulta, como se muestra a continuación:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY' as "New York",'CT' "Connecticut",
'NJ' "New Jersey",'FL' "Florida",'MO' as "Missouri")
)
order by 1
/
Puchase Frequency New York Connecticut New Jersey Florida Missouri
----------------- -------- ----------- -------- ------- ---------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
,
etcétera ...La cláusula FOR puede incluir alias para esos valores, que se convertirán en los encabezados de columna.
Unpivot
Así como hay materia y antimateria, para pivot debe existir unpivot, ¿verdad?
Hablando en serio, la necesidad de contar con un operador inverso a pivot es real. Supongamos que usted tiene una planilla de cálculo con el informe de referencias cruzadas que se ve a continuación:
div class="otable otable-scrolling">| Purchase Frequency | New York | Connecticut | New Jersey | Florida | Missouri |
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
| ... | . |
Ahora usted desea cargar los datos en una tabla relacional llamada CUSTOMERS:
SQL> desc customers
Name Null? Type
-------------------------- ----- -------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
STATE_CODE VARCHAR2(2)
TIMES_PURCHASED NUMBER(3)
SQL> desc customers
Name Null? Type
--------------------------- ----- ------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
STATE_CODE VARCHAR2(2)
TIMES_PURCHASED NUMBER(3)Es más sencillo mostrar esta operación con un ejemplo. Primero generemos una tabla de referencias cruzadas con la operación pivot:
1 create table cust_matrix
2 as
3 select * from (
4 select times_purchased as "Puchase Frequency", state_code
5 from customers t
6 )
7 pivot
8 (
9 count(state_code)
10 for state_code in ('NY' as "New York",'CT' "Conn",
'NJ' "New Jersey",'FL' "Florida", 'MO' as "Missouri")
11 )
12* order by 1Puede verificarse cómo se almacenan los datos en la tabla:
SQL> select * from cust_matrix
2 /
Puchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- -------- ------ ------- ---------
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
...
etcétera ...Así se almacenan los datos en la planilla de cálculo: Cada estado es una columna de la tabla ("New York", "Conn", etc.).
SQL> desc cust_matrix
Name Null? Type
------------------ ------- --------
Puchase Frequency NUMBER(3)
New York NUMBER
Conn NUMBER
New Jersey NUMBER
Florida NUMBER
Missouri NUMBERSe deben separar los datos de la tabla para que las filas solo muestren el código de estado y los recuentos para cada estado. Esto se puede hacer con el operador unpivot como se muestra a continuación:
select *
from cust_matrix
unpivot
(
state_counts
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
)
order by "Puchase Frequency", state_code
/
Los datos de salida se presentan así:
Puchase Frequency STATE_CODE STATE_COUNTS
-----------------------------------------
1 Conn 165
1 Florida 0
1 Missouri 0
1 New Jersey 0
1 New York 33048
2 Conn 179
2 Florida 0
2 Missouri 0
...
etcétera ...Nótese que cada nombre de columna se convirtió en un valor en la columna STATE_CODE. ¿Cómo supo Oracle que state_code es un nombre de columna? Porque así se indica en la siguiente cláusula de la consulta:
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
Allí se especifica que los valores "New York", "Conn", etc. corresponden a una nueva columna, state_code, respecto de la cual se desea aplicar la operación unpivot. Observe una parte de los datos originales:
Purchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ------- ----- ------- --------
1 33048 165 0 0 0Al transformarse la columna "New York" en un valor de una fila, ¿en qué columna debería mostrarse el valor 33048? Esa pregunta se responde en la cláusula inmediatamente anterior a la cláusula FOR del operador unpivot en la consulta del ejemplo. Como se especificó state_counts, ese es el nombre de la nueva columna creada en la salida.
Unpivot puede ser la acción opuesta a pivot, pero la primera no necesariamente revierte los efectos de la segunda. Por ejemplo, en el caso que acabamos de mostrar, se creó una nueva tabla, CUST_MATRIX, aplicando la operación pivot a la tabla CUSTOMERS. Luego se aplicó unpivot a la tabla CUST_MATRIX, pero esa operación no recuperó todos los datos de la tabla CUSTOMERS original. El informe con referencias cruzadas se mostró de forma diferente para que se lo pueda cargar en una tabla relacional. Entonces, unpivot no sirve para deshacer lo que hace el operador pivot, hecho que no debe perderse de vista si se va a generar una tabla con esa operación y descartar la original.
Algunos de los interesantes usos de unpivot van más allá de la potente manipulación de datos que se mostró en el ejemplo anterior. El director del programa Oracle ACE en Amis Technologies Lucas Jellema mostró cómo se pueden generar filas de datos específicos con fines de prueba (contenido en inglés). Aquí se transcribirá una forma ligeramente modificada del código original para generar vocales del alfabeto inglés:
select value
from
(
(
select
'a' v1,
'e' v2,
'i' v3,
'o' v4,
'u' v5
from dual
)
unpivot
(
value
for value_type in
(v1,v2,v3,v4,v5)
)
)
/Los datos de salida se presentan así:
V
-
a
e
i
o
uEste modelo puede aplicarse a cualquier tipo de generador de filas. Gracias, Lucas, por mostrarnos este astuto truco.
Tipo XML
En el ejemplo anterior, nótese que fue necesario especificar los códigos de estado válidos para state_code:
for state_code in ('NY','CT','NJ','FL','MO')
Para ello, se deben conocer de antemano los valores presentes en la columna state_code. Si no se conocen los valores disponibles, ¿cómo se crea la consulta?
Existe otra cláusula en la operación pivot, XML, que permite generar la salida reordenada como código XML en el que se puede incluir una cláusula especial, ANY, en lugar de valores literales. Sigue un ejemplo:
select * from (
select times_purchased as "Purchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (any)
)
order by 1
/La salida se presenta en formato CLOB (objeto grande de caracteres), por lo que antes de ejecutar la consulta conviene verificar que se haya asignado a LONGSIZE un valor grande.
SQL> set long 99999
Existen dos claras diferencias (marcadas en negritas) entre esta consulta y la operación pivot original. Primero, se especificó una cláusula, pivot xml, en lugar de usar solo el operador pivot. Así, la salida tiene formato XML. Segundo, la cláusula FOR incluye for state_code in (any) en lugar de una larga lista de valores posibles para state_code. La notación en XML permite usar la palabra clave ANY, de modo de sortear la necesidad de ingresar los valores de state_code. Los datos de salida se presentan así:
Purchase Frequency STATE_CODE_XML
------------------ --------------------------------------------------
1 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">165</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33048</colu
mn></item></PivotSet>
2 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">179</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33151</colu
mn></item></PivotSet>
...
etcétera ...Como puede verse, la columna STATE_CODE_XML es XMLTYPE, y el elemento raíz es <PivotSet>. Cada valor está representado como un par de elementos nombre y valor. Pueden usarse los datos de salida en cualquier analizador de XML para generar salidas más útiles.
Además de la cláusula ANY, es posible incluir una subconsulta. Supongamos que se desea trabajar con algunos estados preferidos, para lo cual es necesario seleccionar solo las columnas correspondientes a esos estados . Los estados preferidos se han ingresado en una nueva tabla llamada preferred_states:
SQL> create table preferred_states
2 (
3 state_code varchar2(2)
4 )
5 /
Table created.
SQL> insert into preferred_states values ('FL')
2> /
1 row created.
SQL> commit;
Commit complete.Ahora la operación pivot tiene la siguiente sintaxis:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (select state_code from preferred_states)
)
order by 1
/La subconsulta de la cláusula FOR puede incluir lo que usted desee. Por ejemplo, si desea seleccionar todos los registros sin restricciones relativas a estados preferidos, puede usar el siguiente código como cláusula FOR:
for state_code in (select distinct state_code from customers)
La subconsulta debe devolver valores diferenciados; de lo contrario la consulta no funcionará. Por eso incluimos la cláusula DISTINCT en el ejemplo.
Conclusión
Pivot suma una funcionalidad muy importante y práctica al lenguaje SQL. En lugar de crear código complicado y poco intuitivo con muchas funciones de decodificación, se puede usar la función pivot para crear un informe con referencias cruzadas a partir de cualquier tabla relacional. Análogamente, es posible convertir cualquier informe con referencias cruzadas para ser almacenado como tabla relacional mediante la operación unpivot. Pivot puede producir datos de salida en formato de texto común o XML. En el segundo caso, no es necesario indicar el dominio de valores entre los que buscará la operación pivot.
Para obtener más información sobre las operaciones pivot y unpivot, consulte Oracle Database 11g SQL Language Reference (Material de referencia sobre el lenguaje de Oracle Database 11g) (en inglés).
Publicado por Arup Nanda.