Modelo de datos
El modelado de datos es el proceso de representar los datos de forma que los usuarios puedan comprenderlos fácilmente y encontrar respuestas a sus preguntas. El modelado de datos requiere un enfoque centralizado para garantizar métricas empresariales coherentes, así como un enfoque de autoservicio para que los usuarios combinen datos para respaldar sus investigaciones.
Creación de modelos de datos
El modelado de datos es esencial tanto para proporcionar datos en una forma que esté lista para responder a la mayoría de las preguntas empresariales previstas como para garantizar una visión coherente de todos los números de la empresa. Los modelos de datos también omiten la complejidad de la forma física en que se almacenan los datos y, en su lugar, presentan a los usuarios vistas de los datos que tienen sentido para ellos. Por ejemplo, los usuarios de finanzas no tienen que entender los lenguajes de consulta SQL o MDX, sino que pueden consultar fácilmente un sistema de gestión de bases de datos relacionales (RDBMS) o un cubo Essbase utilizando términos financieros reconocibles de su propio léxico.
El modelo de datos es un único lugar para definir cálculos empresariales. Independientemente de cómo o dónde se utilicen esos cálculos, el valor será coherente y confiable. Por ejemplo, la métrica coste de contratación tendría los sistemas fuente aplicables correctamente asignados y el cálculo definido de forma centralizada. De este modo, cualquier proceso de visualización o elaboración de informes que utilice esa métrica indicará siempre la misma cifra.
Modelo semántico controlado
Desarrolla y proporciona modelos semánticos controlados y de confianza para garantizar una vista coherente de los datos fundamentales para la empresa. Asigna datos complejos a términos empresariales familiares y coherentes. Diseña consultas optimizadas y ajustadas para la ejecución.
El modelo semántico se compone de tres capas: empezando por la capa física, que alimenta la capa lógica, que a su vez alimenta la capa de presentación. La capa física mapea los sistemas de origen de datos físicos de la organización y suele estar configurada y gestionada por TI. La capa lógica se utiliza para desarrollar cálculos de negocio, jerarquías y asignaciones de varias fuentes de datos en áreas de informes lógicas. Por ejemplo, el sistema ERP y el almacén de datos se pueden asignar juntos para áreas de informes financieros. La capa de presentación es la forma en que se presentan a los usuarios los atributos y métricas de que disponen para crear sus historias analíticas. Aunque todos los datos se calculan de forma coherente, la visión particular de un usuario de esos datos se filtra en función de su acceso y autorización de seguridad.
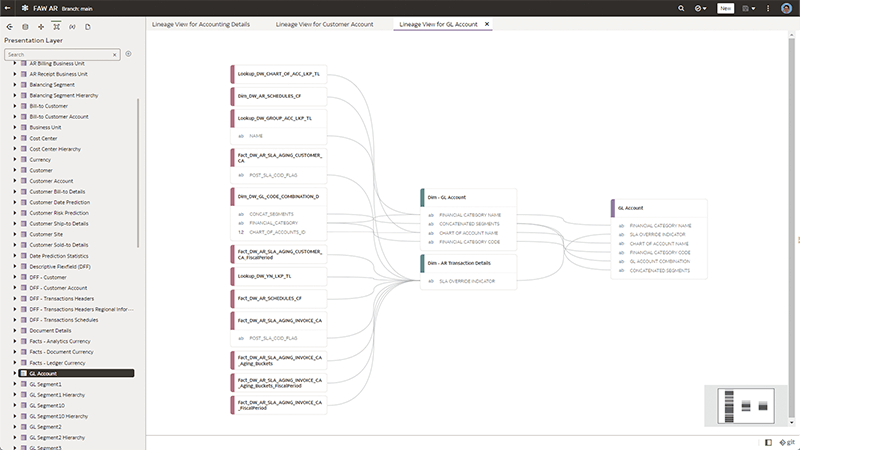
El modelo semántico también es visible para herramientas de visualización de terceros (por ejemplo, Tableau, Power BI o aplicaciones personalizadas) como fuente JDBC. Esto garantiza que, si algunos grupos empresariales eligen herramientas de visualización diferentes, las métricas empresariales solo tengan que definirse una vez y sigan siendo coherentes en todas las plataformas de elaboración de informes de la empresa.
Más información sobre la capa semántica
Modelado de datos de autoservicio
Los usuarios pueden unir directamente dos o más tablas y controlar la relación, por ejemplo, de uniones internas o externas, a través del autoservicio. Comparte fácilmente modelos de datos de autoservicio con tus compañeros.
Acompaña una demostración de conjunto de datos de varias tablas (2:57)

Aumento de datos y recomendaciones
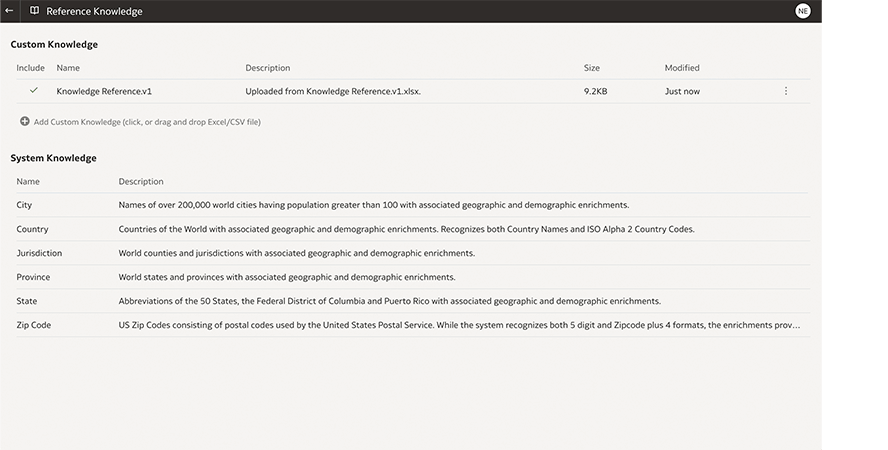
Los juegos de datos se pueden aumentar con datos, atributos o transformaciones adicionales. Los conocimientos de referencia incorporados incluyen:
- Enriquecimientos del sistema de posicionamiento global:
Latitud y longitud de referencia para ciudades o códigos postales. - Enriquecimientos basados en referencias:
Designe el género utilizando el nombre de pila de la persona como atributo que define la decisión de género. - Concatenaciones de columnas:
enlace el nombre y el apellido de una persona en una columna. - Extracciones de piezas:
separa el número de casa del nombre de la calle en una dirección. - Extracciones semánticas:
extrae información de un tipo semántico reconocido, como un dominio de una dirección de correo electrónico. - Extracciones de parte de fecha:
extrae el día de la semana a partir de una fecha que utilice un formato de mes/día/año (o día/mes/año) para que los datos sean más útiles en las visualizaciones. - Ocultación total y parcial:
la máscara ha detectado campos confidenciales, como números de tarjeta de crédito o de seguridad social. - Recomendaciones comunes:
suprime las columnas que contienen campos confidenciales detectados. - Enriquecimientos de conocimientos personalizados:
utiliza inclusiones personalizadas que el administrador haya añadido a Oracle Analytics.
Lenguaje de marcado de modelador semántico (SMML)
Los desarrolladores de modelos de datos pueden crear, editar y ajustar modelos semánticos mediante la herramienta gráfica basada en web; sin embargo, otro enfoque es modificar modelos mediante programación mediante el lenguaje de marcado del modelador semántico (SMML). SMML es un lenguaje de marcado basado en JSON que describe los objetos del modelo semántico en tiempo de diseño. Cada archivo SMML representa un objeto en el modelo semántico. Puedes utilizar archivos SMML para la migración de metadatos, la generación y manipulación de metadatos programáticos, la aplicación de parches de metadatos y otras funciones. Esto significa que los desarrolladores pueden editar el código del modelo semántico directamente o aplicar cambios a través de otros procesos programáticos simplemente realizando cambios textuales directamente en la definición de SMML.

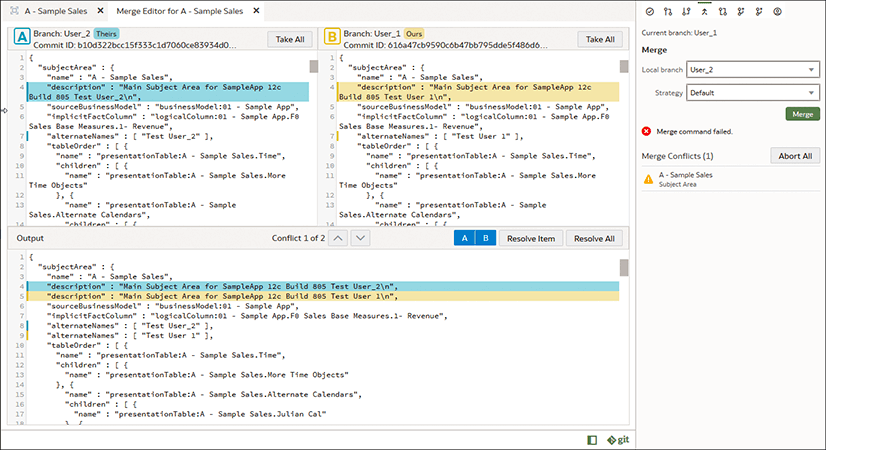
Desarrollo de modelos multiusuario e integración de Git
El modelador semántico se integra con cualquier repositorio compatible con Git, como GitHub, GitLab o Git en Oracle Visual Builder, para proporcionar un entorno de desarrollo y control de código fuente colaborativo y multiusuario sin interrupciones. La integración de Git para el desarrollo multiusuario admite operaciones de ramificación, fusión, pull y push, y permite una visibilidad total del ciclo de vida de desarrollo del modelo semántico.