Oracle Data Miner
Oracle Data MinerはOracle SQL Developerの拡張機能です。データ・サイエンティストやビジネスおよびデータアナリストが、データを閲覧し、迅速に複数の機械学習モデルを作成し、複数のモデルを比較・評価し、モデルを新しいデータに適用し、さらにモデルのデプロイを迅速化できるようにします。
Oracle Data Minerを使用すると、データ・サイエンティスト、市民データ・サイエンティスト、ビジネスアナリスト、およびデータアナリストは、グラフィカルなドラッグ・アンド・ドロップ形式のワークフロー・エディタを使用して、データベース内のデータを直接操作できます。Oracle Data Miner(ODMr)はOracle SQL Developerの拡張機能です。データを調査して機械学習手法を開発する際にユーザーが実施する手段を、グラフィカルな分析的ワークフローとして取得して記録します。ODMrのワークフローは、分析手法の再実行や、チームメンバーとのインサイトの共有に役立ちます。ODMrはSQLおよびPL/SQLスクリプトを生成し、エンタープライズ全体でモデルのデプロイを加速するワークフローAPIを提供します。
機能概要
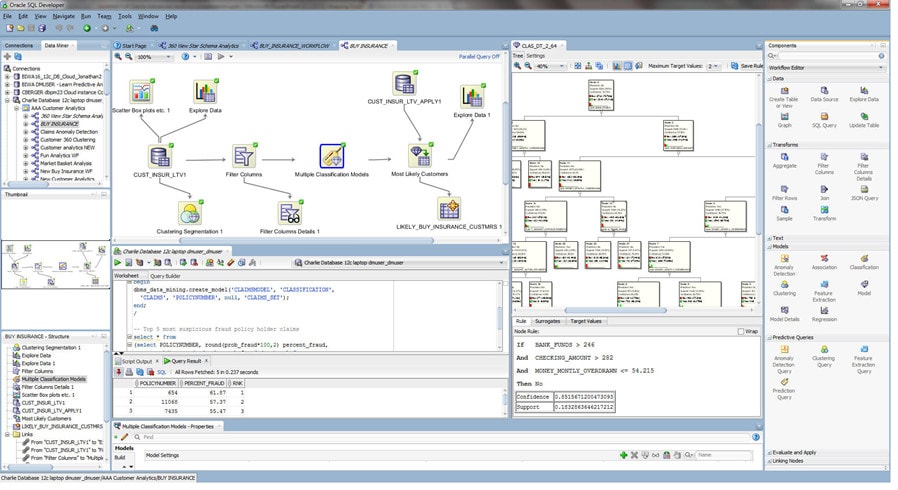
- 機械学習手法を作成、評価、変更、共有、およびデプロイするためのインタラクティブなワークフローツール
- ODMrツールパレットからのノード
- データを可視化するためのノードの内容およびグラフの表示 - ヒストグラム、サマリー統計情報、スキャッタープロット、ボックスプロット
- 変換ノード - 変数のビニングと記録、欠損値の処理、Oracle Machine Learningによる自動データ準備をオーバーライドする、ユーザードメインの専門知識に基づき新たに「設計された特徴」の作成などを行い、一般的なデータ変換およびカスタムのデータ変換をサポート
- 列フィルタノード - 属性の重要度/特徴の選択アルゴリズムを使用して、管理型学習において最も影響力のある属性を特定。また、非管理型学習にカルバック・ライブラー情報量を用いて、おのおのの属性と他の属性との相関関係の強さを特定
- モデル構築ノード - トレーニングおよびテストデータセットのランダムなサンプルの作成、モデルの自動テストおよび評価、モデルビジュアライザ(ディシジョンツリー、クラスタツリー、モデル属性係数など)による混同マトリックス、リフトチャート、受信者動作特性(ROC)曲線、およびモデル統計のコンピューティングなど、一般的な各種ステップを自動化
- テーブルとビューの構造化データ(数値データ型およびVARCHARデータ型)、非構造化データ(CLOB)、トランザクション・データ、集計、空間およびグラフデータを取得して処理
- 任意の機械学習テクニックに複数のアルゴリズムが存在する場合、モデル構築ノードは比較のために自動的に複数の機械学習モデルを構築
- データ並列実行やタスク並列実行など、オープンソースRと統合してユーザー定義のR関数をデータベースサーバーで実行(Oracle Machine Learning for Rを参照)
- Big Data SQLとの連携により、Oracle Database、Spark、Hadoop、および他のデータソースを含む広範なビッグデータソース内のデータにアクセス
主なビジネス上のメリット
- データ移動の排除、ビッグデータのスケーラビリティの実現、セキュリティの維持、モデルの開発からデプロイメントまでの時間の短縮
- Oracle Database環境間を簡単に移動することにより、Oracle Machine Learningモデルおよび関連するデータアセンブリ、変換、準備スクリプトの開発ステージングと本番環境のデプロイメント・シナリオをサポート
- データベース内の機械学習アルゴリズムを備え、データ主導型のプロジェクトを可能にする多様なスキルセットにより従業員を支援
- 使いやすいドラッグ・アンド・ドロップ形式のユーザー・インタフェースにより、「市民データ・サイエンティスト」のためのナレッジ検出とモデル構築を加速
- 共有と自動化のために開発される機械学習手法をワークフローによって記録
- ワークフローからSQLおよびPL/SQLスクリプトを生成し、エンタープライズ全体でモデルのデプロイを自動化して加速
- ワークフローAPIにより、プログラム的なワークフローを呼び出し可能
機能と拡張機能の一覧については、ドキュメント内の製品リリースノートを参照してください。
トレンド