사전 구축된 데이터 분석용 머신러닝
Oracle Fusion Analytics는 구체적인 비즈니스 프로세스에 즉시 적용 가능한 머신러닝(ML) 기능을 제공합니다. 또한 사용자는 동일한 Fusion Analytics 플랫폼 서비스를 활용하여 독자적인 ML 기반 사용 사례를 구축하거나, 단 몇 번의 클릭만으로 간단히 적용 가능한 셀프 서비스 ML 및 예측 분석 기능을 통해 비즈니스 사용자, 데이터 분석가, 데이터 과학자를 지원할 수 있습니다.
특정 비즈니스 프로세스용으로 사전 구축된 머신러닝
Oracle Fusion Analytics는 사용자가 자신만의 인사이트 및 결과를 얻을 수 있도록 지원하는, 즉시 사용 가능한 특정 비즈니스 프로세스용 머신러닝 라이브러리를 지속적으로 확장해 나가고 있습니다. 개중 몇 가지 샘플은 다음과 같습니다.
고객의 대금 연체 또는 송장의 지연 결제 위험을 예측할 수 있습니다. 수금 우선순위를 설정하고 현금 흐름을 개선하는 데 기여합니다.
채용, 해고, 승진에 부정적인 영향을 미치는 성별 및 인종별 지표를 파악하고 모니터링할 수 있습니다.
데이터 과학자를 위한 머신러닝 플랫폼
Oracle Fusion Analytics에는 데이터 과학자가 데이터가 저장된 데이터베이스 내에서 바로 머신러닝을 실행할 수 있는 엔터프라이즈급 머신러닝 플랫폼이 포함되어 있습니다. Machine Learning in Oracle Database로 명명된 해당 플랫폼은 자동화된 노코드 머신러닝을 제공하기 위한 30개 이상의 ML 알고리즘을 제공합니다. 또한 Machine Learning in Oracle Database는 SQL, R, Python 등 데이터 과학 분야에서 널리 사용되는 프로그래밍 언어들과 호환되는 자연스러운 인터페이스를 제공합니다.
나아가 가장 주목할 만한 사실은 Fusion Analytics가 시민 데이터 과학자 및 분석가들이 중앙 저장소에서 해당 모델들에 액세스하고, 자체 데이터세트를 간단히 적용하여 예측을 수행할 수 있는 셀프 서비스 도구를 제공한다는 것입니다.
셀프 서비스 ML
Fusion Analytics의 근간인 Oracle Analytics Cloud의 다양한 기능을 사용하면 누구든 간단히 머신러닝 및 예측 분석을 적용하여 이상 요인을 신속히 감지하고 결과를 예측할 수 있습니다.
설명 가능한 머신러닝을 통한 인사이트 확보
Explain 기능을 사용하면 단 몇 번의 클릭만으로 모든 데이터세트를 조사하여 주목할 만한 비즈니스 동인 및 데이터 이상 징후를 신속히 파악할 수 있습니다. 이후 자동 시각화 기능을 사용하여 심층적인 신규 분석에 바로 착수할 수 있습니다.

고급 분석
단 몇 번의 클릭만으로 사전 구축된 고급 분석 도구들을 간단히 적용 가능합니다.
- 예측: 사전 구축된 사전 예측(predictive forecasting) 모델을 사용하여 과거 및 현재 데이터를 기반으로 향후 일정 기간 내의 가능성을 계산하여 예측합니다.
- 추세선: 데이터 중 특정 추세를 강조 표시합니다.
- 클러스터: 다른 그룹에 속한 개체들보다 높은 상호 일관성 및 근접성을 나타내는 객체들의 그룹을 찾을 수 있습니다.
- 이상값: 평균 예상값에서 가장 멀리 떨어져 있는 이상값 및 변칙을 찾아냅니다.
- 텍스트 분석(예: 감정 분석): 설문조사, 질문서 등에 실린 답변의 어조(예: 부정, 긍정, 중립)를 파악합니다.
- 친화성 분석(예: 장바구니 분석): 함께 자주 나타나는 항목들을 판별하여 데이터 간의 관계를 파악할 수 있습니다.
- 그래프 분석: 사람과 트랜잭션이 연결된 방식, 네트워크의 허브 간 최단 거리 등의 데이터 관계를 시각적으로 보여줍니다.
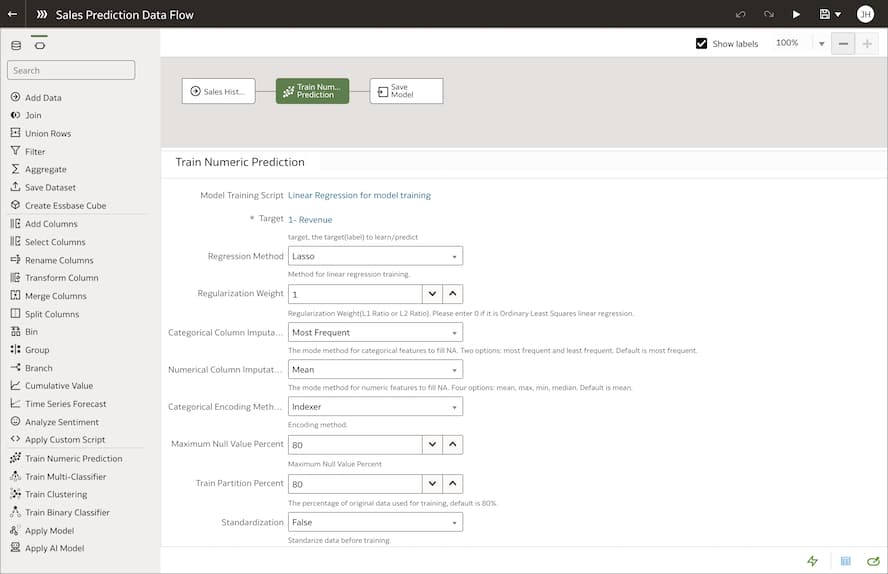
셀프 서비스 예측 모델링 기능
Oracle Fusion Analytics에는 별도의 코딩 없이도 목표값을 예측하거나 레코드의 등급을 식별할 수 있는 예측 모델의 구축 및 학습에 기여하는 다양한 머신러닝 알고리즘이 포함되어 있습니다. 사용 가능한 알고리즘 유형으로는 분류 및 회귀 트리(CART), 로지스틱 회귀, K-평균 등이 있습니다. 예측 모델의 학습이 완료되면 누구나 모든 데이터세트에 해당 모델을 적용할 수 있습니다.