Qu’est-ce qu’une base de données orientée graphe ?
5 novembre 2024

Présentation de la base de données orientée graphe
Une base de données orientée graphe est une plateforme spécialisée et à objectif unique pour la création et la manipulation de graphes. Les graphes contiennent des nœuds, des arêtes et des propriétés, qui sont tous utilisés pour représenter et stocker les données d’une manière que les bases de données relationnelles ne sont pas équipées pour le faire.
L’analyse de graphes est un autre terme couramment utilisé, qui désigne le processus d’analyse des données dans un format de graphe utilisant des points de données comme nœuds et des relations comme arêtes. L’analyse de graphes nécessite une base de données qui prend en charge les formats de graphes ; il peut s’agir d’une base de données orientée graphe dédiée ou d’une base de données multimodèle prenant en charge plusieurs modèles de données, y compris des graphiques.
Découvrez comment utiliser le graphique avec un atelier pas à pas
Types de bases de données orientée graphe
Il existe deux modèles populaires de bases de données orientées graphe : les graphes de propriétés et les graphes RDF. Le graphe de propriétés est axé sur l'analyse et l'interrogation, tandis que le graphe RDF met l'accent sur l'intégration des données. Les deux types de graphes sont constitués d'une collection de points (sommets) et des connexions entre ces points (arêtes). Mais il existe également des différences.
Graphiques de propriétés
Les graphes de propriétés sont utilisés pour modéliser les relations entre les données, et ils permettent d'effectuer des requêtes et des analyses de données basées sur ces relations. Un graphe de propriétés comporte des sommets qui peuvent contenir des informations détaillées sur un sujet, et des arêtes qui indiquent la relation entre les sommets. Les sommets et les arêtes peuvent avoir des attributs, appelés propriétés, auxquels ils sont associés.
Dans cet exemple, un ensemble de collègues et leurs relations sont représentés sous la forme d'un graphe de propriétés.

En raison de leur polyvalence, les graphes de propriété sont utilisés dans un large éventail d'industries et de secteurs, tels que la finance, la fabrication, la sécurité publique, le commerce de détail et bien d'autres encore.
Graphes RDF
Les graphes RDF (RDF est l'abréviation de Resource Description Framework) sont conformes à un ensemble de normes du W3C (Worldwide Web Consortium) conçues pour représenter des énoncés et sont les mieux adaptés pour représenter des métadonnées et des données de base complexes. Ils sont souvent utilisés pour les données liées, l'intégration des données et les graphes de connaissances. Ils peuvent représenter des concepts complexes dans un domaine, ou fournir une sémantique riche et une inférence sur les données.
Dans le modèle RDF, une déclaration est représentée par trois éléments : deux sommets reliés par une arête reflétant le sujet, le prédicat et l'objet d'une phrase - c'est ce qu'on appelle un triple RDF. Chaque sommet et chaque arête est identifié par un URI (Unique Resource Identifier) unique. Le modèle RDF fournit un moyen de publier des données dans un format standard avec une sémantique bien définie, permettant l'échange d'informations. Les agences gouvernementales de statistiques, les entreprises pharmaceutiques et les organisations de soins de santé ont largement adopté les graphes RDF.
Fonctionnement des graphiques et des bases de données graphiques
Les graphes et les bases de données orientées graphe fournissent des modèles de graphes pour représenter les relations dans les données. Ils permettent aux utilisateurs d'effectuer des « requêtes transversales » basées sur les connexions et d'appliquer des algorithmes graphiques pour trouver des modèles, des chemins, des communautés, des influenceurs, des points uniques de défaillance et d'autres relations, ce qui permet une analyse plus efficace à l'échelle de quantités massives de données. La puissance des graphes réside dans l'analyse, les informations qu'ils fournissent et leur capacité à relier des sources de données disparates.
Lorsqu'il s'agit d'analyser des graphes, les algorithmes explorent les chemins et la distance entre les sommets, l'importance des sommets et le regroupement des sommets. Par exemple, pour déterminer l'importance, les algorithmes examinent souvent les arêtes entrantes, l'importance des sommets voisins et d'autres indicateurs.
Les algorithmes de graphes, opérations spécialement conçues pour analyser les relations et les comportements entre les données dans des graphes, permettent de comprendre des choses difficiles à voir avec d’autres méthodes. Lorsqu'il s'agit d'analyser des graphes, les algorithmes explorent les chemins et la distance entre les sommets, l'importance des sommets et le regroupement des sommets. Les algorithmes examinent souvent les arêtes entrantes, l'importance des sommets voisins et d'autres indicateurs pour aider à déterminer l'importance. Par exemple, les algorithmes de graphes peuvent identifier quel individu ou élément est le plus connecté aux autres dans les réseaux sociaux ou les processus métier. Ils peuvent identifier les communautés, les anomalies, les modèles communs et les chemins qui relient les individus ou les transactions associées.
Les bases de données orientées graphe stockant explicitement les relations, les requêtes et les algorithmes utilisant la connectivité entre les sommets peuvent être exécutés en quelques secondes plutôt qu'en heures ou en jours. Les utilisateurs n'ont pas besoin d'exécuter d'innombrables jointures et les données peuvent plus facilement être utilisées pour l'analyse et le machine learning afin d'en savoir plus sur le monde qui nous entoure.
Avantages des bases de données orientées graphe
Le format graphique offre une plateforme plus souple pour trouver des connexions distantes ou analyser les données en fonction de facteurs tels que la force ou la qualité de la relation. Les graphes permettent d’explorer et de découvrir des connexions et des modèles dans les réseaux sociaux, l’IoT, le big data, les data warehouse, ainsi que des données de transaction complexes pour plusieurs cas d’utilisation commerciale, notamment la détection de fraude dans le secteur bancaire, la découverte de connexions dans les réseaux sociaux et le client 360. Aujourd'hui, les bases de données orientées graphe sont de plus en plus utilisées dans le cadre de la data science pour établir des connexions dans des relations plus claires.
Comme les bases de données orientées graphe stockent explicitement les relations, les requêtes et les algorithmes utilisant la connectivité entre les sommets peuvent être exécutés en quelques secondes plutôt qu'en heures ou en jours. Les utilisateurs n'ont pas besoin d'exécuter d'innombrables jointures et les données peuvent plus facilement être utilisées pour l'analyse et le machine learning afin d'en savoir plus sur le monde qui nous entoure.
Les bases de données orientées graphe sont un outil extrêmement flexible et puissant. Le format graphe permet de mettre en évidence des relations complexes afin d’obtenir des informations plus poussées, plus facilement. Les bases de données orientées graphe exécutent généralement des requêtes dans des langages tels que le PGQL (Property Graph Query Language). L’exemple ci-dessous montre la même requête en PGQL et SQL.

Comme le montre l’exemple ci-dessus, le code PGQL est plus simple et beaucoup plus efficace. Étant donné que les graphiques mettent l’accent sur les relations entre les données, ils sont idéaux pour plusieurs types d’analyses. En particulier, les bases de données orientées graphe sont parfaites pour :
- Trouver le chemin le plus court entre deux nœuds
- Déterminer les nœuds qui créent le plus d’activité ou d’influence
- Analyser la connectivité pour identifier les points les plus faibles d’un réseau
- Analyser l’état du réseau ou de la communauté en fonction de la distance ou de la densité de connexion dans un groupe
Comment fonctionnent les bases de données orientées graphe et les analyses de graphes
Un exemple simple d’analyse de graphe en action est présenté dans l’image ci-dessous, qui montre une représentation visuelle du jeu de société « Six Degrees of Kevin Bacon ». Ce jeu consiste à créer des liens entre Kevin Bacon et un autre acteur d’après une chaîne de films communs. Cet accent mis sur les relations en fait le moyen idéal pour faire la démonstration de l’analyse de graphes.
Imaginez un ensemble de données avec deux catégories de nœuds : chaque film jamais réalisé et chaque acteur qui a été dans ces films. Ensuite, en nous appuyant sur le graphe, nous exécutons une requête demandant de relier Kevin Bacon à l’icône du Muppet Show Peggy la cochonne. Le résultat serait le suivant :

Dans cet exemple, les nœuds disponibles (sommets) sont à la fois des acteurs et des films et les relations (arêtes) ont le statut « a joué dans ». À partir de ces éléments, la requête renvoie les résultats suivants :
- Kevin Bacon a joué dans La rivière sauvage (The River Wild) avec Meryl Streep.
- Meryl Streep a joué dans Les Désastreuses Aventures des orphelins Baudelaire (A Series of Unfortunate Events) de Lemony Snicket, avec Billy Connolly.
- Billy Connolly a joué dans L’Île au trésor des Muppets (Muppet Treasure Island) avec Peggy la cochonne.
Les bases de données orientées graphe peuvent interroger de nombreuses relations différentes pour cet exemple concernant Kevin Bacon, par exemple :
- « Quelle est la chaîne la plus courte qui relie Kevin Bacon à Peggy la cochonne ? » (analyse du chemin le plus court, telle qu’utilisée dans le jeu Six Degrees ci-dessus)
- « Qui a travaillé avec le plus grand nombre d’acteurs ? » (centralité de degré)
- « Quelle est la distance moyenne entre Kevin Bacon et tous les autres acteurs ? » (centralité de proximité)
Cet exemple est naturellement plus amusant que la plupart des utilisations de l’analyse de graphes. Mais cette approche fonctionne dans presque tous les ensembles de Big Data, soit dans toute situation où un grand nombre d’enregistrements montrent une connectivité naturelle les uns avec les autres. Certaines des finalités les plus répandues de l’utilisation de l’analyse de graphes sont l’analyse des réseaux sociaux, des réseaux de communication, du trafic et la consultation de site web, les données routières réelles, les transactions et les comptes financiers. Pour les cas d'utilisation opérationnels, explorez les capacités des graphiques de propriétés (PDF).
Cas d'utilisation de base de données orientée graphe : blanchiment d'argent
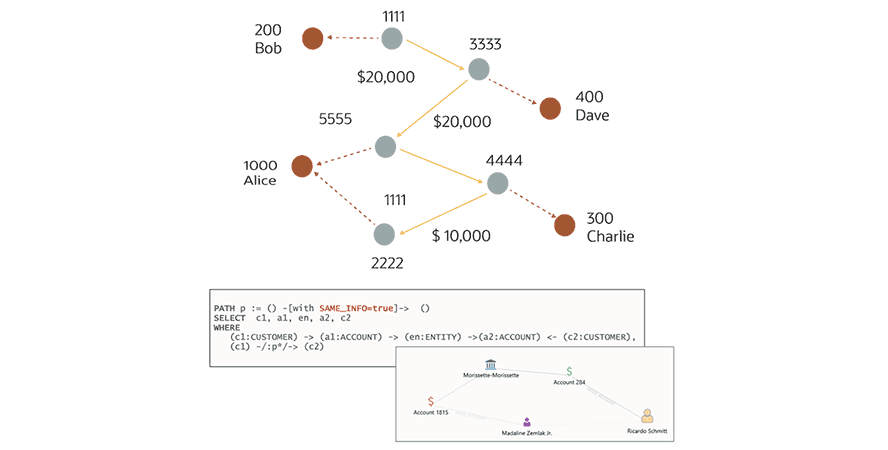
Conceptuellement, le blanchiment d'argent est simple. L'argent sale est transmis pour le combiner avec des fonds légitimes, puis transformé en actifs durs. C'est le type de processus qui a été utilisé dans l'analyse des Panama Papers.
Plus précisément, un transfert d'argent circulaire implique un criminel qui s'envoie à lui-même de grosses sommes d'argent obtenues frauduleusement, mais qui les dissimule par une série longue et complexe de transferts valides entre des comptes « normaux ». Ces comptes « normaux » sont en fait des comptes créés avec des identités synthétiques. Ils partagent généralement certaines informations similaires parce qu'ils sont générés à partir d'identités volées (adresses électroniques, adresses, etc.) et c'est cette information connexe qui fait de l'analyse graphique un outil idéal pour leur faire révéler leurs origines frauduleuses.
Pour simplifier la détection des fraudes, les utilisateurs peuvent créer un graphique à partir de transactions entre des entités et des entités qui partagent certaines informations, notamment les adresses électroniques, les mots de passe, les adresses, etc. Une fois qu'un graphique est créé, l'exécution d'une requête simple permet de rechercher tous les clients ayant des comptes ayant des informations similaires et de déterminer les comptes qui envoient de l'argent les uns aux autresther.
Cas d'utilisation de base de données orientée graphe : fraude à la carte de crédit
Les bases de données orientées graphe sont devenues un outil puissant dans le secteur de la finance comme moyen de détection de la fraude Malgré les progrès de la technologie anti-fraude, grâce notamment à l’utilisation de puces intégrées dans les cartes, la fraude peut encore prendre plusieurs aspects. Les appareils de copiage peuvent voler les données contenues sur des bandes magnétiques, technique couramment employée dans les endroits dépourvus de lecteurs de puces. Une fois que ces données sont stockées, elles peuvent être chargés sur une carte contrefaite pour effectuer des achats ou retirer de l’argent.
En matière de détection des fraudes, l’identification des modèles est souvent la première ligne de défense. Les modèles d’achat attendus sont basés sur l’emplacement, la fréquence, les types de magasins et autres éléments qui correspondent à un profil utilisateur. Lorsqu’une transaction semble totalement anormale, par exemple, si une personne passe le plus clair de son temps à San Francisco et qu’elle fait soudainement des achats tard dans la nuit en Floride, cela peut indiquer un acte frauduleux.
La puissance de calcul nécessaire pour ces opérations est considérablement réduite grâce à l’analyse de graphes. L’analyse de graphes est idéale pour établir des modèles entre les nœuds. Dans ce cas, les catégories de nœuds sont définies en tant que comptes (titulaires de carte), lieux d’achat, catégorie d’achat, transactions et terminaux. Il est facile d’identifier les modèles de comportement habituels. Par exemple, au cours d’un mois donné, une personne peut :
- Acheter de la nourriture pour animaux (catégorie d’achat) dans différentes animaleries (terminaux)
- Régler des repas dans des restaurants le week-end (métadonnées de transaction) de la région (lieux d’achat)
- Acheter du matériel de réparation (catégorie d’achat) dans un magasin local (lieu du compte, lieu d’achat)
La détection des fraudes est généralement gérée grâce au machine learning, mais l’analyse de graphes peut contribuer à créer un processus plus précis et plus efficace. Grâce à la mise en évidence de relations, les résultats sont des éléments de prévision efficaces pour déterminer et signaler les enregistrements frauduleux.
L’avenir des bases de données orientées graphe
Les bases de données orientées graphe et les techniques de graphe ont évolué avec l’augmentation de la puissance de calcul et du Big Data have au cours des dix dernières années. En fait, il est de plus en plus clair qu’elles deviendront un outil standard pour analyser un univers de relations complexes entre les données. Alors que les entreprises et les organisations continuent de développer les capacités du big data et des analyses, la capacité à obtenir des informations de manière de plus en plus complexe rend les bases de données orientées graphe incontournables pour les besoins d’aujourd’hui et les succès de demain.
Oracle facilite l'adoption des technologies graphiques. Oracle Database et Oracle Autonomous Database intègrent une base de données orientée graphe et un moteur d'analyse de graphes afin que les utilisateurs puissent découvrir davantage de renseignements sur leurs données en utilisant la puissance des algorithmes de graphes, des requêtes de correspondance de motifs et de la visualisation. Les graphiques font partie de la base de données convergente d'Oracle, qui prend en charge les exigences liées aux modèles multiples, aux charges de travail multiples et aux locataires multiples, le tout dans un seul moteur de base de données.
Bien que toutes les bases de données de graphes prétendent être très performantes, les offres de graphes d'Oracle sont performantes à la fois en termes de performance des requêtes et d'algorithmes, et sont étroitement intégrées à la base de données Oracle. Cela permet aux développeurs d'ajouter facilement des analyses graphiques aux applications existantes et d'exploiter l'évolutivité, la cohérence, la récupération, le contrôle d'accès et la sécurité fournis par défaut par la base de données.
Essayez dès aujourd'hui un atelier graphique étape par étape
Cas d'utilisation de base de données orientée graphe : analyse des réseaux sociaux
Les bases de données orientées graphe peuvent être utilisées dans de nombreux scénarios différents, mais elles le sont fréquemment pour analyser les réseaux sociaux. En fait, les réseaux sociaux constituent le cas d’utilisation idéal, car ils comprennent un volume important de nœuds (comptes d’utilisateurs) et de connexions multidimensionnelles (engagements dans de nombreuses directions différentes). Une analyse de graphe d’un réseau social peut déterminer :
Cependant, ces informations ne sont d’aucune utilité si elles ont été faussées par des robots. Heureusement, l’analyse de graphes peut fournir un excellent moyen d’identifier et de filtrer les robots.
Citons un cas d’utilisation concret. L’équipe Oracle a utilisé Oracle Marketing Cloud pour évaluer la publicité et la traction sur les réseaux sociaux, en particulier pour identifier les faux comptes de robots qui biaisaient les données. Le comportement le plus courant de ces robots consistait à retweeter des comptes cibles, gonflant ainsi artificiellement leur popularité. Une simple analyse de modèle a mis cela en évidence en utilisant le nombre de retweets et la densité des connexions avec les voisins. Les comptes véritablement populaires ont présenté des relations différentes avec leurs voisins de celles des comptes alimentés par des robots.
Cette image montre des comptes véritablement populaires.
Et cette image illustre le comportement d’un compte géré par un robot.
Le principe consiste à utiliser la puissance de l’analyse de graphes pour identifier un modèle naturel par rapport à un modèle de robot. Il suffit ensuite de filtrer ces comptes, bien qu’il soit également possible de creuser plus profondément pour examiner, par exemple, la relation entre les robots et les comptes retweetés.
Les réseaux sociaux font de leur mieux pour éliminer les comptes de robots, car ils ont un impact sur l’expérience globale de leur base d’utilisateurs. Pour vérifier que ce processus de détection de robots était précis, les comptes signalés ont été vérifiés après un mois. Les résultats furent les suivants :
Le pourcentage extrêmement élevé de comptes sanctionnés (91,2 %) témoigne de la précision de l’identification des modèles et du processus de nettoyage. Cette opération aurait pris beaucoup plus de temps dans une base de données tabulaire standard. Avec l’analyse de graphes, il est possible d’identifier rapidement des modèles complexes.