 文章
企业管理
文章
企业管理
Oracle Database 11g: 作者:Arup Nanda |

压缩
数据压缩支持在 Oracle Database 中并非什么新功能,但 11g 通过 Advanced Compression 和混合列压缩将此概念提升到新的高度。
Advanced Compression
压缩对于 Oracle 并非新功能;自从 Oracle9i Database 以来,一直围绕着 COMPRESS BASIC 形式。
压缩始终是非常占用 CPU 的过程,并且需要花费一定时间。通常,如果压缩数据,则数据必须解压缩后才能使用。虽然此要求在数据仓库环境(SQL 通常在大量的行上运行,漫长的响应时间通常是可以容忍的)中是可以接受的,但在 OLTP 环境中可能无法接受。
现在,在 Oracle Database 11g 中(但仅限您获得了 Advanced Compression 选件许可的情况下),您可以进行如下操作:
create table my_compressed_table ( col1 number(20), col2 varchar2(300), ... ) compress for all operations
“compress for all operations”子句在所有 DML 活动(如 INSERT、UPDATE 等)上执行压缩。压缩在所有 DML 活动上发生,而不像前几个版本那样,只在直接路径插入上发生。 这会降低 DML 的速度吗?不一定。这正是该新特性的最大优点。向表中插入行时不会发生压缩。相反,在插入行时,这些行将被解压缩,然后以常规方式插入。当以解压缩方式插入(或更新)一定数量的行时,将执行压缩算法并压缩块中所有解压缩的行。换句话说,将压缩块,而不是行。在 RDBMS 代码内部定义压缩发生的阈值。
压缩机制
请看一个 ACCOUNTS 表,它包含以下记录:


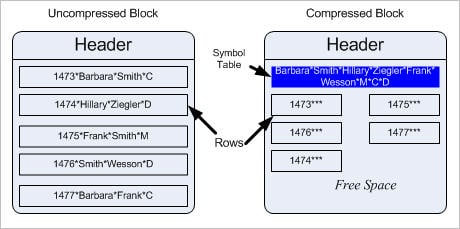
由于压缩作为触发事件发生,而不是在插入行时发生,因此在正常的 DML 进程中压缩对性能没有任何影响。压缩被触发后,对 CPU 的需求肯定会变得很高,但在其他任何时间 CPU 影响都为零,因此压缩也适用于 OLTP 应用程序,这是 Oracle Database 11g 中压缩的平衡点。
除了减少空间占用外,压缩数据还将缩短网络传输时间、减少备份空间,并使在 QA 和测试中维护生产数据库的完整副本变得切实可行。
混合列压缩(仅限 Oracle 数据库云服务器上的第 2 版)
在 11g 第 2 版中(但仅限在 Oracle 数据库云服务器 v2 中进行了预先安装),压缩技术已通过混合列压缩 (HCC) 形式进行了扩展。
首先,为何需要扩展压缩功能?原因很简单:可能无法用一种方法搜索数据库的所有数据。例如,纯粹出于法律原因,某些数据(如公司电子邮件)需要位于数据库中;此类数据必须始终能够访问,即使实际上很少需要访问。此类数据需要进行存储,而存储就要为磁盘、运行磁盘的电力、冷却设备以及占地面积投入资金。那么为何要对极少访问的数据使用昂贵的存储?
这种情况下便可采用 HCC。通常,压缩的工作原理是将重复值替换为一些更小的符号,从而减少占用的整体空间。例如,假定未压缩数据行如下所示(列之间由“|”分隔):
Row1: Quite_a_large_value1|Quite_a_long_value1|Another_quite_long_value1 Row2: Quite_a_large_value2|Quite_a_long_value1|Another_quite_long_value1 Row3: Quite_a_large_value1|Quite_a_long_value2|Another_quite_long_value1 Row4: Quite_a_large_value1|Quite_a_long_value1|Another_quite_long_value2
三行的总大小为 264 字节。请注意,这三行中实际上只有六个不同值,它们被多次使用。
Quite_a_large_value1 Quite_a_large_value2 Quite_a_long_value1 Quite_a_long_value2 Another_quite_long_value1 Another_quite_long_value2
压缩这个块时,会为每个不同的值分配一个特殊值,将实际值替换为相应的特殊值。例如,以下是分配的特殊值:
原始值 | 替换为符号 |
Quite_a_large_value1 | A1 |
Quite_a_large_value2 | A2 |
Quite_a_long_value1 | B1 |
Quite_a_long_value2 | B2 |
Another_quite_long_value1 | C1 |
Another_quite_long_value2 | C2 |
这三行现在应如下所示:
Row1: A1|B1|C1
Row1: A2|B1|C1
Row1: A1|B2|C1
Row1: A1|B1|C2
总大小:从 264 字节急剧减少到 32 字节,大约减少了 88%。(当然,减少百分比取决于数据,尤其是不同值的数量,但原理是相同的。)唯一符号(A1、A2 等)与其所表示的值(“Quite_a_large_value1”等)之间的关系以一种被称作符号目录的结构存储在块头中。每个块头必须存储该块中使用的符号。当然,由于相同值将在块中重复,因此将存在重复项。
如果您查看真实数据,您会注意到,值通常在列中重复,而非在行中重复。例如,一个名为 FIRST_NAME 的列将具有 John、Jack 等值,而另一个名为 CITY_NAME 的列将具有 New York 或 Los Angeles 之类的值。您不会在 first_name 列中看到 New York。由于值在列中(而非在行中)更频繁地重复,因此您可以为每列仅创建一个符号目录。由于符号目录会占用空间,因此,较之每个块必须具有一个符号目录的传统压缩,符号目录数量的显著减少将会减少整体空间。
混合列压缩便使用此方法。这会实现大量压缩,但会影响 DML 性能。因此,最好将其用于不涉及 DML 操作的查询的表。
以下是按这种压缩方式进行查询创建的表示例
create table trans_comp nologging compress for query low as select * from trans;
“compress”子句对表进行压缩。“for query”子句以混合列方式压缩表。“low”子句不会如此积极地压缩表。因此将占用更多空间,但压缩和解压缩不会占用同样多的 CPU。通过将“low”子句替换为“high”,可实现更高的压缩比。此类型的 HCC 称为仓库压缩,因为它适用于存储大量频繁查询的数据的数据仓库。
如果极少访问某个表,那么可使用“for archive”子句以更高比率来压缩该表:
create table trans_comp nologging compress for archive low as select * from trans;
这将进一步减少占用的空间(但是以 CPU 为代价)。与“for query”子句的设置一样,“for archive”也有两个值:high 和 low。这称为存档压缩,其中的数据不常访问。以下是一组代表性数据的压缩比示例。当然,数据不同,压缩比差别会很大。
压缩类型 | 压缩后表大小 |
未压缩 | 100.00% |
Query Low | 14.70% |
Query High | 8.82% |
Archive Low | 6.62% |
Archive High | 4.41% |
通过混合列压缩,您可以压缩受 DML 影响不大但出于法律或其他原因不能删除其数据的表。现在,您可以存储这些表,但占用很少的存储,并且使用更少的 CPU。请再次注意,此特性仅在 Oracle Exadata Storage Server 第 2 版中可用。有关更多信息,请参阅此白皮书。
参见系列目录