 文章
服务器与存储管理
文章
服务器与存储管理
如何用 Oracle Solaris ZFS 优化企业存储
作者:Cindy Swearingen
如何减少企业存储空间,同时将重要数据托管在速度最快的存储上,将其他数据存档在标准存储上。
2014 年 7 月发布
简介
在云数据存储需求爆炸式增长的时代,Oracle Solaris ZFS 提供了一些集成特性以减少存储空间。ZFS 还提供了灵活的分层存储模型,您可以将重要数据托管在速度最快的存储设备上,同时将不太重要的数据压缩和存档到标准存储设备。
|
在 Oracle Solaris 11 中,Oracle Solaris ZFS 提供了以下方法来优化您的存储要求:
- ZFS 压缩,通常可将企业级系统上的存储空间减少至原来的约 1/3。启用 LZJB 压缩(默认的 ZFS 压缩算法)提供了良好的压缩比,不会影响系统性能。
- ZFS 重复数据删除。在 ZFS 文件系统上启用重复数据删除 (
dedup) 属性后,将数据块写入磁盘时将删除重复的数据块。启用重复数据删除将占用系统和内存资源,因此必须确定您的数据是否可重复数据删除,以及系统是否有足够资源支持重复数据删除过程。 - 灵活的 ZFS 池化存储。考虑将 ZFS 存储池中最重要的数据和活动数据放在最快的磁盘上。同时考虑将 ZFS 存储池中不太重要的数据存档到启用压缩的标准存储设备上。
启用 ZFS 数据压缩
使用以下过程启用默认的 ZFS 压缩算法 (LZJB),这通常会减少企业级系统上的存储空间(如图 1 所示),不会影响系统性能。

图 1. 使用 ZFS 压缩减少存储空间
- 确定数据是否可压缩:
- 为示例数据文件新建一个文件系统:
# zfs create tank/data
- 将示例数据文件复制到新文件系统中:
# cp file.1 /tank/data/file.1
- 显示新文件系统的大小:
# zfs list tank/data
- 创建另一个启用了压缩的新文件系统:
# zfs create -o compression=on tank/newdata
- 将相同的示例数据文件复制到启用了压缩的新文件系统,并显示第一个新文件系统的大小:
# cp /tank/data/file.1 /tank/newdata/file.1 # zfs list tank/data
- 显示已启用压缩的文件系统的大小:
# zfs list tank/newdata
- 比较
zfs list输出中这两个文件系统的所示大小:
压缩后数据的大小应为原始文件大小的 1/3-1/2。如果示例数据不可压缩,启用 ZFS 压缩并不适合您的数据。
- 为示例数据文件新建一个文件系统:
- 如果数据可压缩,则在新文件系统上启用压缩并将数据复制到新文件系统,或者在现有文件系统上启用压缩:
# zfs create -o compression=on tank/newdata
请记住,如果在现有文件系统上启用压缩,只会压缩新数据。
启用 ZFS 数据重复数据删除
如果 ZFS 文件系统已启用 dedup 属性,在将数据块写入磁盘时将删除重复的数据块。结果是磁盘上只存储独一无二的数据,文件之间共享共同的组成部分,如图 2 所示。

图 2. 启用重复数据删除时如何删除重复数据块的示例
重复数据删除可以节省磁盘空间使用和成本。但在启用重复数据删除之前,必须确保您的数据可重复数据删除,且系统满足内存要求。
如果您的数据不支持重复数据删除,启用重复数据删除不仅毫无意义,还会浪费 CPU 资源。ZFS 重复数据删除是带内操作,这意味着重复数据删除只发生在将数据写入磁盘时,同时影响 CPU 和内存资源。
重复数据删除表 (DDT) 会占用内存,最终会溢出以至于占用磁盘空间。此时,ZFS 将不得不为尝试进行重复数据删除的每个数据块执行额外的读写操作。这将导致性能下降。
数据池很大但物理内存很小的系统执行重复数据删除的性能不好。如果系统不满足内存要求,有些操作(如删除启用了重复数据删除的大型文件系统)会严重降低系统性能。
此外,考虑在文件系统上启用压缩是否将提供一种更好的办法来减少磁盘空间占用。
- 运行
zdb命令确定文件系统上的数据是否支持重复数据删除。
如果估计的重复数据删除率大于 2,您可能会看到空间节省。在清单 1 所示的示例中,重复数据删除率小于 2,因此不建议启用重复数据删除。
# zdb -S tank Simulated DDT histogram: bucket allocated referenced ______ ______________________________ ______________________________ refcnt blocks LSIZE PSIZE DSIZE blocks LSIZE PSIZE DSIZE ------ ------ ----- ----- ----- ------ ----- ----- ----- 1 1.00M 126G 126G 126G 1.00M 126G 126G 126G 2 11.8K 573M 573M 573M 23.9K 1.12G 1.12G 1.12G 4 370 418K 418K 418K 1.79K 1.93M 1.93M 1.93M 8 127 194K 194K 194K 1.25K 2.39M 2.39M 2.39M 16 43 22.5K 22.5K 22.5K 879 456K 456K 456K 32 12 6K 6K 6K 515 258K 258K 258K 64 4 2K 2K 2K 318 159K 159K 159K 128 1 512 512 512 200 100K 100K 100K Total 1.02M 127G 127G 127G 1.03M 127G 127G 127G dedup = 1.00, compress = 1.00, copies = 1.00, dedup * compress / copies = 1.00清单 1
- 确定系统是否有足够内存支持重复数据删除操作。
每个核内 DDT 块约为 320 字节。因此要将分配块数乘以 320。下面的示例使用清单 1 中的数据:
核内 DDT 大小 (1.02M) x 320 = 需要 326.4 MB 内存。
- 启用
dedup属性。
确保只在具有可重复数据删除数据的文件系统上启用
dedup。# zfs set dedup=on mypool/myfs
使用 ZFS 池化存储优化数据放置
ZFS 提供了一些用于配置灵活的分层存储池的选项,以优化您的企业存储,如图 3 所示。
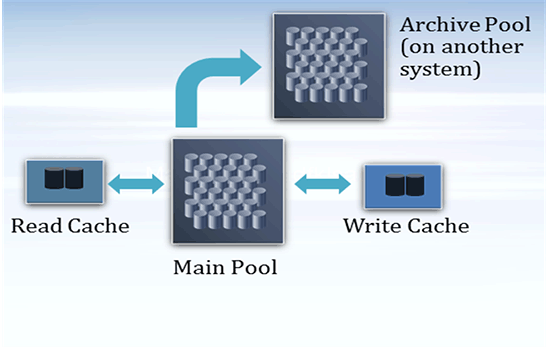
图 3. 分层存储池示例
使用以下过程配置分层存储池:
- 通过将最重要的数据和活动数据放到最快的存储设备上,优化数据放置。
镜像池可为大多数负载提供最佳性能。例如,以下语法创建一个镜像 ZFS 存储池 tank,它有两个镜像组件(每个有两个硬盘),以及一个备用磁盘:
# zpool create tank mirror disk1 disk2 mirror disk3 disk4 spare disk5
- 将存档数据放到另一系统上一个池中的标准存储设备上。
RAIDZ 池对于存档数据是一个很好的选择。例如,以下语法创建一个 RAIDZ-2 池
rzpool,它有一个 RAIDZ-2 组件,由五个磁盘和一个备用磁盘组成。将快照流发送到新池时,我们还在接收文件系统上启用压缩:# zpool create rzpool raidz2 disk1 disk2 disk3 disk4 disk5 spare disk6 # zfs snapshot -r tank/old_data@date # zfs send -Rv tank/old_data@date | ssh sys-B zfs receive -o compression=on rzpool/oldtankdata # zfs destroy -r tank/old_data@date
注:您必须配置成在另一个系统上使用
ssh。 - 通过将写或读负载的活动数据放入高性能固态磁盘 (SSD) 可优化数据性能,例如:
- 将 SSD 作为缓存设备添加,可减轻读取负载:
# zpool add tank cache ssd-1 ssd-2
- 将 SSD 作为日志设备添加,可减轻同步写入负载:
# zpool add nfspool log mirror ssd-1 ssd-2
- 将 SSD 作为缓存设备添加,可减轻读取负载:
总结
本文介绍了在 Oracle Solaris 11 中使用 ZFS 减少存储空间和优化数据存储的多种灵活方式。您可考虑采用适合您的应用数据负载及存储和系统资源的最佳方式。
另请参见
- 下载 Oracle Solaris 11
- 访问 Oracle Solaris 11 产品文档
- 访问所有 Oracle Solaris 11 方法文章
- 通过 Oracle Solaris 11 培训和支持了解更多信息
- 阅读官方 Oracle Solaris 博客
- 阅读 The Observatory 和 OTN Garage 博客,获得 Oracle Solaris 提示和技巧
- 在 Facebook 和 Twitter 上关注 Oracle Solaris
关于作者
Cindy Swearingen 是 Oracle Solaris 产品经理,擅长 ZFS 和存储特性。
| 修订版 1.0,2014 年 7 月 14 日 |