 文章
服务器与存储管理
文章
服务器与存储管理
如何使用 Oracle Solaris 区域搭建 Hadoop 集群
作者:Orgad Kimchi
如何将 Apache Hadoop 集群与 Oracle Solaris 区域和 Oracle Solaris 11 新增的网络虚拟化功能结合使用,在一个系统上搭建一个 Hadoop 集群。
2013 年 1 月发布(2013 年 2 月更新)
|
下载并安装 Hadoop
配置网络时间协议
创建虚拟网络接口
创建 NameNode 区域
设置 DataNode 区域
设置 SSH
验证 SSH 设置
验证名称解析
从 NameNode 格式化 HDFS 文件系统
启动 Hadoop 集群
运行 MapReduce 作业
总结
另请参见
关于作者
本文首先简要介绍 Hadoop,之后给出了使用一个 NameNode、一个辅助 NameNode 和三个 DataNode 搭建 Hadoop 集群的示例。前提是您应对 Oracle Solaris 区域和网络管理有一个基本的了解。
关于 Hadoop 和 Oracle Solaris 区域
Apache Hadoop 软件是一个框架,允许使用简单编程模型分布式处理多个计算机集群上的大数据集。
以下是使用 Oracle Solaris 区域搭建 Hadoop 集群的好处:
- 利用区域克隆特性快速供应新集群成员
- 区域间极高的网络吞吐容量可加快数据节点复制速度
- 通过 ZFS 内置压缩可优化磁盘 I/O 利用率,从而提高 I/O 性能
- 使用 ZFS 加密保护处于静止状态的数据
为存储数据,Hadoop 使用了 Hadoop 分布式文件系统 (HDFS),它提供高吞吐量的应用数据访问,适合具有大数据集的应用。有关 Hadoop 和 HDFS 的更多信息,请参见 http://hadoop.apache.org/。
Hadoop 集群构建块如下所示:
- NameNode:它是 HDFS 的核心组成部分,存储文件系统元数据,指示从属 DataNode 后台程序执行低级 I/O 任务,还运行 JobTracker 进程。
- 辅助 NameNode:对 NameNode 事务日志执行内部检查。
- DataNode:是将数据存储到 HDFS 文件系统的节点,也称为从属节点,运行 TaskTracker 进程。
在本文所示示例中,将使用 Oracle Solaris 区域、ZFS 和网络虚拟化技术安装所有 Hadoop 集群构建块。图 1 显示了架构:
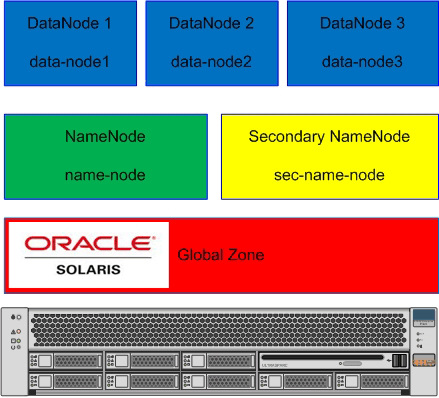
图 1.架构
下载并安装 Hadoop
- 要获取 Hadoop 发行版,请从 Apache 下载镜像之一下载最新稳定版本。
本文采用“2012 年 10 月 12 日发布的 1.0.4”版本。
- 在全局区域上创建
/usr/local目录(如果该目录不存在);稍后将与各区域共享该目录。
root@global_zone:~# mkdir -p /usr/local
- 下载 Hadoop tarball 并将其复制到
/usr/local:
root@global_zone:~# cp /tmp/hadoop-1.0.4.tar.gz /usr/local
- 解压缩 tarball:
root@global_zone:~# cd /usr/local root@global_zone:~# gzip -dc /usr/local/hadoop-1.0.4.tar.gz | tar -xvf -
- 创建 Hadoop 组:
root@global_zone:~# groupadd hadoop
- 添加 Hadoop 用户,并设置用户的 Hadoop 密码:
root@global_zone:~# useradd -g hadoop hadoop root@global_zone:~# passwd hadoop
- 创建 Hadoop 用户主目录:
root@global_zone:~# mkdir -p /export/home/hadoop root@global_zone:~# chown hadoop:hadoop /export/home/hadoop/
- 重命名 Hadoop 二进制文件的位置,并将所有权授予 Hadoop 用户:
root@global_zone:~# mv /usr/local/hadoop-1.0.4 /usr/local/hadoop root@global_zone:~# chown -R hadoop:hadoop /usr/local/hadoop*
- 编辑 Hadoop 配置文件,如表 1 所示:
表 1.Hadoop 配置文件文件名 说明 hadoop-env.sh指定 Hadoop 使用的环境变量设置。 core-site.xml指定所有 Hadoop 后台程序和客户端的相关参数。 hdfs-site.xml指定 HDFS 后台程序和客户端使用的参数。 mapred-site.xml指定 MapReduce 后台程序和客户端使用的参数。 masters包含运行辅助 NameNode 的计算机列表。 slaves包含运行 DataNode 和 TaskTracker 后台程序对的计算机名称列表。
要详细了解这些配置文件如何控制 Hadoop 框架,请参见 http://hadoop.apache.org/docs/r1.0.4/api/org/apache/hadoop/conf/Configuration.html。
- 运行以下命令,切换到
conf目录:
root@global_zone:~# cd /usr/local/hadoop/conf
- 编辑
hadoop-env.sh文件,取消注释并更改 export 代码行,应如下所示:
export JAVA_HOME=/usr/java export HADOOP_LOG_DIR=/var/log/hadoop
- 编辑
masters文件,应如下所示:
sec-name-node
- 编辑
slaves文件,应如下所示:
data-node1 data-node2 data-node3
- 编辑
core-site.xml文件,应如下所示:
<configuration> <property> <name>fs.default.name</name> <value>hdfs://name-node</value> </property> </configuration> - 编辑
hdfs-site.xml文件,应如清单 1 所示:
<configuration> <property> <name>dfs.data.dir</name> <value>/hdfs/data/</value> </property> <property> <name>dfs.name.dir</name> <value>/hdfs/name/</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>清单 1.
hdfs-site.xml文件 - 编辑
mapred-site.xml文件,应如下所示:
<configuration> <property> <name>mapred.job.tracker</name> <value>name-node:8021</value> </property> </configuration>
- 运行以下命令,切换到
配置网络时间协议
应确保使用网络时间协议 (NTP) 同步 Hadoop 区域上的系统时钟。在本示例中,全局区域配置为 NTP 服务器。
注:最好选择可以作为专用时间同步源的 NTP 服务器,这样在关闭计算机进行计划维护时不会对其他服务产生负面影响。
以下示例显示了如何配置 NTP 服务器。
- 编辑 NTP 服务器配置文件,如清单 2 所示:
root@global_zone:~# grep -v ^# /etc/inet/ntp.conf server 127.127.1.0 prefer broadcast 224.0.1.1 ttl 4 enable auth monitor driftfile /var/ntp/ntp.drift statsdir /var/ntp/ntpstats/ filegen peerstats file peerstats type day enable filegen loopstats file loopstats type day enable filegen clockstats file clockstats type day enable keys /etc/inet/ntp.keys trustedkey 0 requestkey 0 controlkey 0 root@global_zone:~# touch /var/ntp/ntp.drift
清单 2.NTP 服务器配置文件
- 启用 NTP 服务器服务:
root@global_zone:~# svcadm enable ntp
- 使用以下命令验证 NTP 服务器是否在线:
root@global_zone:~# svcs -a | grep ntp online 16:04:15 svc:/network/ntp:default
创建虚拟网络接口
比如,与 1 Gb 的物理网络连接相比,同一系统上的 Oracle Solaris 区域可受益于极高的网络 I/O 吞吐容量(高达四倍速度)和极低的延迟。对于 Hadoop 集群,这意味着 DataNode 可大大提高 HDFS 块的复制速度。
有关网络虚拟化基准测试的详细信息,请参见“如何控制应用的网络带宽”。
为不同区域创建一系列虚拟网络接口 (VNIC):
root@global_zone:~# dladm create-vnic -l net0 name_node1 root@global_zone:~# dladm create-vnic -l net0 secondary_name1 root@global_zone:~# dladm create-vnic -l net0 data_node1 root@global_zone:~# dladm create-vnic -l net0 data_node2 root@global_zone:~# dladm create-vnic -l net0 data_node3
创建 NameNode 区域
- 如果 NameNode 和辅助 NameNode 区域还没有文件系统,请执行以下命令:
root@global_zone:~# zfs create -o mountpoint=/zones rpool/zones
- 创建
name-node区域,如清单 3 所示:
root@global_zone:~# zonecfg -z name-node Use 'create' to begin configuring a new zone. Zonecfg:name-node> create create: Using system default template 'SYSdefault' zonecfg:name-node> set autoboot=true zonecfg:name-node> set limitpriv="default,sys_time" zonecfg:name-node> set zonepath=/zones/name-node zonecfg:name-node> add fs zonecfg:name-node:fs> set dir=/usr/local/hadoop zonecfg:name-node:fs> set special=/usr/local/hadoop zonecfg:name-node:fs> set type=lofs zonecfg:name-node:fs> set options=[ro,nodevices] zonecfg:name-node:fs> end zonecfg:name-node> add net zonecfg:name-node:net> set physical=name_node1 zonecfg:name-node:net> end zonecfg:name-node> verify zonecfg:name-node> exit
清单 3.创建
name-node区域 - 创建
sec-name-node区域,如清单 4 所示:
root@global_zone:~# zonecfg -z sec-name-node Use 'create' to begin configuring a new zone. Zonecfg:sec-name-node> create create: Using system default template 'SYSdefault' zonecfg:sec-name-node> set autoboot=true zonecfg:sec-name-node> set limitpriv="default,sys_time" zonecfg:sec-name-node> set zonepath=/zones/sec-name-node zonecfg:sec-name-node> add fs zonecfg:sec-name-node:fs> set dir=/usr/local/hadoop zonecfg:sec-name-node:fs> set special=/usr/local/hadoop zonecfg:sec-name-node:fs> set type=lofs zonecfg:sec-name-node:fs> set options=[ro,nodevices] zonecfg:sec-name-node:fs> end zonecfg:sec-name-node> add net zonecfg:sec-name-node:net> set physical=secondary_name1 zonecfg:sec-name-node:net> end zonecfg:sec-name-node> verify zonecfg:sec-name-node> exit
清单 4.创建
sec-name-node区域
设置 DataNode 区域
在本步骤中,我们可以利用 Oracle Solaris 区域虚拟化技术与 Oracle Solaris 中内置的 ZFS 文件系统的集成。
Hadoop 优秀实践是为每个 DataNode 使用单独的硬盘。因此,每个 DataNode 区域都有自己的硬盘,以便提供更好的 I/O 分配,如图 2 所示。
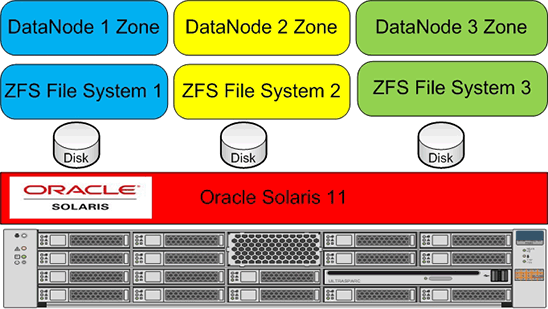
图 2.为每个 DataNode 使用单独的磁盘
表 2 显示了我们将创建的 Hadoop 区域配置汇总:
表 2.区域汇总| 功能 | 区域名称 | ZFS 挂载点 | VNIC 名称 | IP 地址 |
|---|---|---|---|---|
| NameNode | name-node |
/zones/name-node |
name_node1 |
192.168.1.1 |
| 辅助 NameNode | sec-name-node |
/zones/sec-name-node |
secondary_name1 |
192.168.1.2 |
| DataNode | data-node1 |
/zones/data-node1 |
data_node1 |
192.168.1.3 |
| DataNode | data-node2 |
/zones/data-node2 |
data_node2 |
192.168.1.4 |
| DataNode | data-node3 |
/zones/data-node3 |
data_node3 |
192.168.1.5 |
- 使用以下命令获取硬盘名称:
root@global_zone:~# format Searching for disks...done AVAILABLE DISK SELECTIONS: 0. c7t0d0 <LSI-MR9261-8i-2.50-135.97GB> /pci@0,0/pci8086,340a@3/pci1000,9263@0/sd@0,0 1. c7t1d0 <LSI-MR9261-8i-2.50-135.97GB> /pci@0,0/pci8086,340a@3/pci1000,9263@0/sd@1,0 2. c7t2d0 <LSI-MR9261-8i-2.50-135.97GB> /pci@0,0/pci8086,340a@3/pci1000,9263@0/sd@2,0 - 为每个区域创建一个单独的 ZFS 文件系统,以提高磁盘 I/O 性能:
root@global_zone:~# zpool create -O compression=on data-node1-pool c7t0d0 root@global_zone:~# zpool create -O compression=on data-node2-pool c7t1d0 root@global_zone:~# zpool create -O compression=on data-node3-pool c7t2d0 root@global_zone:~# zfs create -o mountpoint=/zones/data-node1 data-node1-pool/data-node1 root@global_zone:~# zfs create -o mountpoint=/zones/data-node2 data-node2-pool/data-node2 root@global_zone:~# zfs create -o mountpoint=/zones/data-node3 data-node3-pool/data-node3
- 更改目录权限,以避免在区域创建过程中出现警告消息:
root@global_zone:~# chmod 700 /zones/data-node1 root@global_zone:~# chmod 700 /zones/data-node2 root@global_zone:~# chmod 700 /zones/data-node3
- 将
zonecfg zonepath属性指向您创建的 ZFS 文件系统,如清单 5 所示。
root@global_zone:~# zonecfg -z data-node1 Use 'create' to begin configuring a new zone. zonecfg:data-node1> create create: Using system default template 'SYSdefault' zonecfg:data-node1> set autoboot=true zonecfg:data-node1> set limitpriv="default,sys_time" zonecfg:data-node1> set zonepath=/zones/data-node1 zonecfg:data-node1> add fs zonecfg:data-node1:fs> set dir=/usr/local/hadoop zonecfg:data-node1:fs> set special=/usr/local/hadoop zonecfg:data-node1:fs> set type=lofs zonecfg:data-node1:fs> set options=[ro,nodevices] zonecfg:data-node1:fs> end zonecfg:data-node1> add net zonecfg:data-node1:net> set physical=data_node1 zonecfg:data-node1:net> end zonecfg:data-node1> verify zonecfg:data-node1> commit zonecfg:data-node1> exit root@global_zone:~# zonecfg -z data-node2 Use 'create' to begin configuring a new zone. zonecfg:data-node2> create create: Using system default template 'SYSdefault' zonecfg:data-node2> set autoboot=true zonecfg:data-node2> set limitpriv="default,sys_time" zonecfg:data-node2> set zonepath=/zones/data-node2 zonecfg:data-node2> add fs zonecfg:data-node2:fs> set dir=/usr/local/hadoop zonecfg:data-node2:fs> set special=/usr/local/hadoop zonecfg:data-node2:fs> set type=lofs zonecfg:data-node2:fs> set options=[ro,nodevices] zonecfg:data-node2:fs> end zonecfg:data-node2> add net zonecfg:data-node2:net> set physical=data_node2 zonecfg:data-node2:net> end zonecfg:data-node2> verify zonecfg:data-node2> commit zonecfg:data-node2> exit root@global_zone:~# zonecfg -z data-node3 Use 'create' to begin configuring a new zone. zonecfg:data-node3> create create: Using system default template 'SYSdefault' zonecfg:data-node3> set autoboot=true zonecfg:data-node3> set limitpriv="default,sys_time" zonecfg:data-node3> set zonepath=/zones/data-node3 zonecfg:data-node3> add fs zonecfg:data-node3:fs> set dir=/usr/local/hadoop zonecfg:data-node3:fs> set special=/usr/local/hadoop zonecfg:data-node3:fs> set type=lofs zonecfg:data-node3:fs> set options=[ro,nodevices] zonecfg:data-node3:fs> end zonecfg:data-node3> add net zonecfg:data-node3:net> set physical=data_node3 zonecfg:data-node3:net> end zonecfg:data-node3> verify zonecfg:data-node3> commit zonecfg:data-node3> exit
清单 5.设置
zonecfg zonepath属性 - 现在安装
name-node区域;稍后我们将克隆此区域,以提高区域的创建速度。
root@global_zone:~# zoneadm -z name-node install The following ZFS file system(s) have been created: rpool/zones/name-node Progress being logged to /var/log/zones/zoneadm.20130106T134835Z.name-node.install Image: Preparing at /zones/name-node/root. - 启动
name-node区域,并查看所创建区域的状态,如清单 6 所示:
root@global_zone:~# zoneadm -z name-node boot root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 1 name-node running /zones/name-node solaris excl - sec-name-node configured /zones/sec-name-node solaris excl - data-node1 configured /zones/data-node1 solaris excl - data-node2 configured /zones/data-node2 solaris excl - data-node3 configured /zones/data-node3 solaris excl root@global_zone:~# zlogin -C name-node
清单 6.启动
name-node区域 - 使用
name-node区域的以下配置提供区域的主机信息:
- 主机名使用
name-node。 - 确保网络接口
name_node1的 IP 地址是 192.168.1.1/24。 - 确保名称服务基于您的网络配置。
在本文中,我们将使用
/etc/hosts作名称解析,因此不会设置 DNS 进行主机名称解析。
- 主机名使用
- 完成区域设置之后,登录到区域。
- Hadoop 开发需要 Java 编程环境。可以使用以下命令安装 Java Development Kit (JDK) 6:
root@name-node:~# pkg install jdk-6
- 验证 Java 安装:
root@name-node:~# which java /usr/bin/java root@name-node:~# java -version java version "1.6.0_35" Java(TM) SE Runtime Environment (build 1.6.0_35-b10) Java HotSpot(TM) Server VM (build 20.10-b01, mixed mode)
- 在
name-node区域内创建一个 Hadoop 用户:
root@name-node:~# groupadd hadoop root@name-node:~# useradd -g hadoop hadoop root@name-node:~# passwd hadoop root@name-node:~# mkdir -p /export/home/hadoop root@name-node:~# chown hadoop:hadoop /export/home/hadoop
- 配置 NTP 客户端,如以下示例所示:
- 安装 NTP 软件包:
root@name-node:~# pkg install ntp
- 编辑 NTP 客户端配置文件:
root@name-node:~# grep -v ^# /etc/inet/ntp.conf server global_zone prefer slewalways yes disable pll
- 启用 NTP 服务:
root@name-node:~# svcadm enable ntp
- 安装 NTP 软件包:
- 在
/etc/hosts中添加 Hadoop 集群成员的主机名和 IP 地址:
root@name-node:~# cat /etc/hosts ::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3
注:如果您使用全局区域作为 NTP 服务器,还必须将其主机名和 IP 地址添加到
/etc/hosts。
设置 SSH
- 在
name-node区域上为 Hadoop 用户设置基于 SSH 密钥的身份验证,以便实现无密码登录辅助 DataNode 和 DataNode:
root@name-node # su - hadoop hadoop@name-node $ ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa hadoop@name-node $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- 更新
$HOME/.profile:
hadoop@name-node $ cat $HOME/.profile # Set JAVA_HOME export JAVA_HOME=/usr/java # Add Hadoop bin/ directory to PATH export PATH=$PATH:/usr/local/hadoop/bin
- 键入以下命令检查 Hadoop 是否运行:
hadoop@name-node $ hadoop version Hadoop 1.0.4 Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1393290 Compiled by hortonfo on Wed Oct 3 05:13:58 UTC 2012 From source with checksum fe2baea87c4c81a2c505767f3f9b71f4
- 创建 Hadoop 日志文件目录:
root@name-node:~# mkdir /var/log/hadoop root@name-node:~# chown hadoop:hadoop /var/log/hadoop
- 在全局区域运行以下命令创建
sec-name-node区域,作为name-node的克隆:
root@global_zone:~# zoneadm -z name-node shutdown root@global_zone:~# zoneadm -z sec-name-node clone name-node
- 启动
sec-name-node区域:
root@global_zone:~# zoneadm -z sec-name-node boot root@global_zone:~# zlogin -C sec-name-node
- 与前面一样,系统配置工具启动,然后执行
sec-name-node区域的最终配置:
- 主机名使用
sec-name-node。 - 网络接口使用
secondary_name1。 - 使用 IP 地址 192.168.1.2/24。
- 确保名称服务设置为
none。
- 主机名使用
- 对
data-node1、data-node2和data-node3执行类似步骤:
- 对
data-node1执行以下操作:
root@global_zone:~# zoneadm -z data-node1 clone name-node root@global_zone:~# zoneadm -z data-node1 boot root@global_zone:~# zlogin -C data-node1
- 主机名使用
data-node1。 - 网络接口使用
data_node1。 - 使用 IP 地址 192.168.1.3/24。
- 确保名称服务设置为
none。
- 主机名使用
- 对
data-node2执行以下操作:
root@global_zone:~# zoneadm -z data-node2 clone name-node root@global_zone:~# zoneadm -z data-node2 boot root@global_zone:~# zlogin -C data-node2
- 主机名使用
data-node2。 - 网络接口使用
data_node2。 - 使用 IP 地址 192.168.1.4/24。
- 确保名称服务设置为
none。
- 主机名使用
- 对
data-node3执行以下操作:
root@global_zone:~# zoneadm -z data-node3 clone name-node root@global_zone:~# zoneadm -z data-node3 boot root@global_zone:~# zlogin -C data-node3
- 主机名使用
data-node3。 - 网络接口使用
data_node3。 - 使用 IP 地址 192.168.1.5/24。
- 确保名称服务设置为
none。
- 主机名使用
- 对
- 启动
name_node区域:
root@global_zone:~# zoneadm -z name-node boot
- 验证所有区域是否启动和运行:
root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 10 sec-name-node running /zones/sec-name-node solaris excl 12 data-node1 running /zones/data-node1 solaris excl 14 data-node2 running /zones/data-node2 solaris excl 16 data-node3 running /zones/data-node3 solaris excl 17 name-node running /zones/name-node solaris excl
验证 SSH 设置
要在不使用 Hadoop 用户密码的情况下验证 SSH 访问,请执行以下操作:
- 从
name_node通过 SSH 登录name-node(即登录到自己):
hadoop@name-node $ ssh name-node The authenticity of host 'name-node (192.168.1.1)' can't be established. RSA key fingerprint is 04:93:a9:e0:b7:8c:d7:8b:51:b8:42:d7:9f:e1:80:ca. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'name-node,192.168.1.1' (RSA) to the list of known hosts.
- 现在尝试登录到
sec-name-node和 DataNode。当您尝试第二次通过 SSH 登录时,应该就不会提示您将主机添加到已知密钥列表了。
验证名称解析
验证所有 Hadoop 区域在 /etc/hosts 中均有以下主机条目:
# cat /etc/hosts ::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3
注:如果您使用全局区域作为 NTP 服务器,还必须将其主机名和 IP 地址添加到 /etc/hosts。
从 NameNode 格式化 HDFS 文件系统
- 运行清单 7 所示命令:
root@name-node:~# mkdir -p /hdfs/name root@name-node:~# chown -R hadoop:hadoop /hdfs/ root@name-node:~# su - hadoop hadoop@name-node:$ /usr/local/hadoop/bin/hadoop namenode -format 13/01/06 20:00:32 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = name-node/192.168.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.0.4 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1393290; compiled by 'hortonfo' on Wed Oct 3 05:13:58 UTC 2012 ************************************************************/
清单 7.格式化 HDFS 文件系统
- 在每个 DataNode(
data-node1、data-node2和data-node3)上,创建一个 Hadoop 数据目录来存储 HDFS 块:
root@data-node1:~# mkdir -p /hdfs/data root@data-node1:~# chown -R hadoop:hadoop /hdfs/ root@data-node2:~# mkdir -p /hdfs/data root@data-node2:~# chown -R hadoop:hadoop /hdfs/ root@data-node3:~# mkdir -p /hdfs/data root@data-node3:~# chown -R hadoop:hadoop /hdfs/
?
启动 Hadoop 集群
表 3 描述了启动脚本。
表 3.启动脚本| 文件名 | 说明 |
|---|---|
start-dfs.sh |
启动 Hadoop DFS 后台程序、NameNode 和 DataNode。此脚本要在 start-mapred.sh 之前使用。 |
stop-dfs.sh |
停止 Hadoop DFS 后台程序。 |
start-mapred.sh |
启动 Hadoop MapReduce 后台程序 JobTracker 和 TaskTracker。 |
stop-mapred.sh |
停止 Hadoop MapReduce 后台程序。 |
- 在
name-node区域,使用以下命令启动 Hadoop DFS 后台程序、NameNode 和 DataNode。
hadoop@name-node:$ start-dfs.sh starting namenode, logging to /var/log/hadoop/hadoop--namenode-name-node.out data-node2: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node2.out data-node1: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node1.out data-node3: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node3.out sec-name-node: starting secondarynamenode, logging to /var/log/hadoop/hadoop-hadoop-secondarynamenode-sec-name-node.out
- 使用以下命令启动 Hadoop Map/Reduce 后台程序、JobTracker 和 TaskTracker:
hadoop@name-node:$ start-mapred.sh starting jobtracker, logging to /var/log/hadoop/hadoop--jobtracker-name-node.out data-node1: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node1.out data-node3: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node3.out data-node2: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node2.out
- 要查看全面的状态报告,执行清单 8 所示命令查看集群状态。该命令将输出有关集群运行状况的基本统计信息,如 NameNode 详细信息、每个 DataNode 的状态以及磁盘容量。
hadoop@name-node:$ hadoop dfsadmin -report Configured Capacity: 171455269888 (159.68 GB) Present Capacity: 169711053357 (158.06 GB) DFS Remaining: 169711028736 (158.06 GB) DFS Used: 24621 (24.04 KB) DFS Used%: 0% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead) ...
清单 8.查看集群状态
您可以在地址为
http://<namenode IP address>:50070/dfshealth.jsp的 NameNode Web 状态页面上找到同样的信息。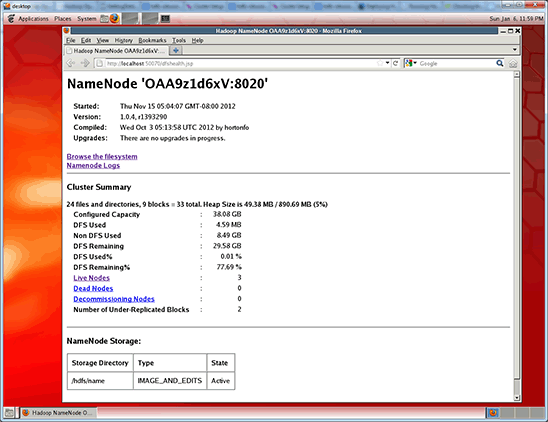
图 3.集群汇总
运行 MapReduce 作业
MapReduce 是一个使用计算机集群针对大规模数据集处理可并行问题的框架。有关 MapReduce 的更多信息,请参见 http://en.wikipedia.org/wiki/MapReduce。
我们将使用 WordCount 示例,该示例读取文本文件并计算用词频率。输入和输出均由文本文件组成,其中每行包含一个单词以及该词使用的次数,使用制表符分隔。有关 WordCount 的更多信息,请参见 http://wiki.apache.org/hadoop/WordCount。
- 对于输入文件,从 Project Gutenberg 下载以下电子书作为使用 UTF-8 编码的纯文本文件,并将该文件存储在选定的临时目录(如
/tmp/data)中:《The Outline of Science》,第 1 卷(共 4 卷),作者:Arthur Thomson。 - 使用以下命令将文件复制到 HDFS:
hadoop@name-node:$ hadoop dfs -copyFromLocal /tmp/data/ /hdfs/data
- 验证文件已位于 HDFS 上:
hadoop@name-node:$ hadoop dfs -ls /hdfs/data Found 1 items -rw-r--r-- 3 hadoop supergroup 661664 2013-01-07 19:45 /hdfs/data/20417-8.txt
- 使用清单 9 所示命令启动 MapReduce 作业:
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.0.4.jar wordcount /hdfs/data /hdfs/data/data-output 13/01/07 15:20:21 INFO input.FileInputFormat: Total input paths to process : 1 13/01/07 15:20:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 13/01/07 15:20:21 WARN snappy.LoadSnappy: Snappy native library not loaded 13/01/07 15:20:22 INFO mapred.JobClient: Running job: job_201301071307_0006 13/01/07 15:20:23 INFO mapred.JobClient: map 0% reduce 0% 13/01/07 15:20:38 INFO mapred.JobClient: map 100% reduce 0% 13/01/07 15:20:50 INFO mapred.JobClient: map 100% reduce 100% 13/01/07 15:20:55 INFO mapred.JobClient: Job complete: job_201301071307_0006 13/01/07 15:20:55 INFO mapred.JobClient: Counters: 26 13/01/07 15:20:55 INFO mapred.JobClient: Job Counters
清单 9.启动 MapReduce 作业
- 验证输出数据:
hadoop@name-node:$ hadoop dfs -ls /hdfs/data/data-output Found 3 items -rw-r--r-- 3 hadoop supergroup 0 2013-01-07 15:20 /hdfs/data/data-output/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2013-01-07 15:20 /hdfs/data/data-output/_logs -rw-r--r-- 3 hadoop supergroup 196288 2013-01-07 15:20 /hdfs/data/data-output/part-r-00000
- 输出数据可能包含敏感信息,因此请使用 ZFS 加密保护输出数据:
- 创建加密 ZFS 数据集:
root@name-node:~# zfs create -o encryption=on rpool/export/output Enter passphrase for 'rpool/export/output': Enter again:
- 更改所有权:
root@name-node:~# chown hadoop:hadoop /export/output/
- 将输出文件从 Hadoop HDFS 复制到 ZFS:
root@name-node:~# su - hadoop Oracle Corporation SunOS 5.11 11.1 September 2012 hadoop@name-node:$ hadoop dfs -getmerge /hdfs/data/data-output /export/output/
- 创建加密 ZFS 数据集:
- 分析输出文本文件。每行包含一个单词以及该词使用的次数,使用制表符分隔。
hadoop@name-node:$ head /export/output/data-output "A 2 "Alpha 1 "Alpha," 1 "An 2 "And 1 "BOILING" 2 "Batesian" 1 "Beta 2
- 通过卸载 ZFS 数据集保护输出文本文件,然后使用以下命令卸载加密数据集的封装密钥:
root@name-node:~# zfs key -u rpool/export/output
如果命令成功,该数据集不可访问,并将卸载。
如果要挂载该 ZFS 文件系统,需要提供密码短语:
root@name-node:~# zfs mount rpool/export/output Enter passphrase for 'rpool/export/output':
通过使用密码短语,可确保只有知道密码短语的人才能查看输出文件。有关 ZFS 加密的更多信息,请参见“如何管理 ZFS 数据加密”。
总结
在本文中,我们了解了如何利用 Oracle Solaris 区域、ZFS 以及网络虚拟化技术构建一个多节点 Hadoop 集群。
另请参见
关于作者
Orgad Kimchi 是 Oracle(之前任职于 Sun Microsystems)ISV 工程小组的首席软件工程师。5 年来,他一直专注于虚拟化和云计算技术。
| 修订版 1.4,2013 年 11 月 25 日 |
![]()
![]()