 文章
面向服务的架构
文章
面向服务的架构
| |||
|




数据完整性
作者:Lucas Jellema
介绍在各种环境中实施数据完整性的基本知识
2013 年 4 月
下载
Oracle Database
Oracle SOA Suite
信息系统中保存和使用的数据必须满足一些要求才具有实用性。数据应准确表达其来源。数据应可靠。数据应具有内部一致性。数据应遵循基于现实世界逻辑建立的规则。数据的这种准确性、内部质量和可靠性常被称作数据完整性。
保障数据的完整性是一项挑战,当多个用户同时访问和操作数据时(显然这种情况很常见),会增加复杂性。管理多个独立数据存储中的数据而非单个数据库中的数据时,这种挑战达到了新的高度。
本文介绍数据完整性实施的一些基本知识。然后讨论如何在单一 [Oracle] 数据库的多用户环境中实现这种完整性。文章然后将该讨论延伸到多数据存储环境,这些数据存储共同为客户提供统一的数据服务,并一起负责数据完整性。不仅针对每个存储内的内部封装完整性,还针对这些存储的整体完整性。
数据完整性约束
数据完整性由被称作数据完整性约束的特定业务规则来保护。现实世界中适用于事件、动作、操作和情况的规则被转换成约束,应用于信息系统中处理的数据。数据完整性意味着系统中记录的数据不违反这些约束。
通常将约束划分成一些复杂性和范围递增的类别。例如:
范围 | 示例 | |
属性 | Salary 属性的值必须为 1000 到 5000 之间的整数 |  |
字节组(记录) | 对于 Job(属性值)等于 SALESMAN 的员工,Salary 属性的值不应超过 2500。Salary 和 Commission 属性的总和不能高于 10000 | 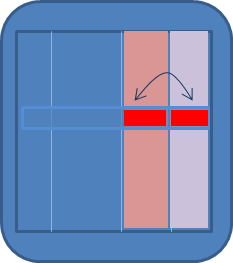 |
实体(表) | 某个属性在(部分)记录表中具有唯一性 从事相同职位的所有员工的最高工资与平均工资之间的差距不得超过平均工资的 30% 作为其他员工经理的员工,其 Job 属性应为 MANAGER 或者与其每个下属的 Job 属性值相同
| 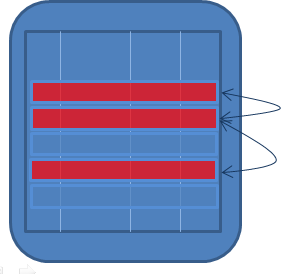 |
| 实体间(跨表) | 引用完整性(外键):所有用于 Department 属性的值都必须存在于 Departments 表中某条记录的 DepartmentId 属性中。 | 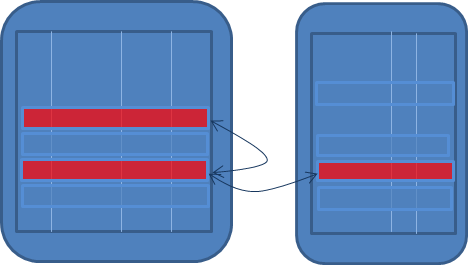 |
注意,在多个独立数据存储一起呈现一个公共数据服务接口的环境中,属性、字节组和实体范围约束封装在每个数据存储中;这些约束不会跨数据存储的边界(当然,除非每个数据存储包含同一数据集合的部分数据)。不过,实体间约束可能涉及不同数据存储中的实体(数据集)。稍后我们将进一步讨论这种情况。
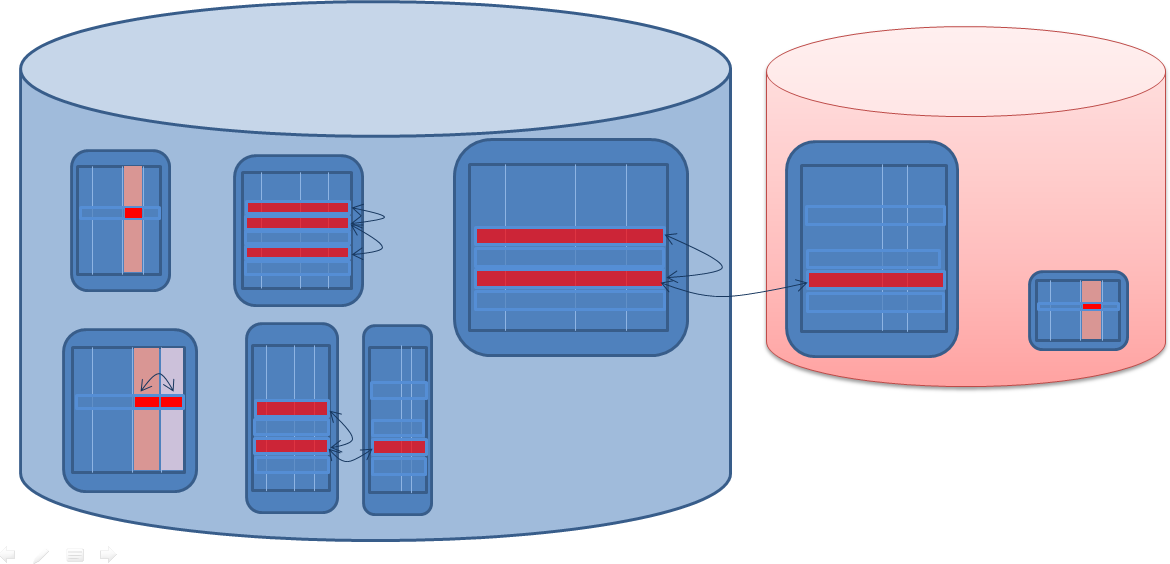
图 5
有些规则适用于更改本身,并不适用于数据的状态。例如:“2 月或 3 月不能更新工资。”或者:“一次工资增幅不能超过 25%。”数据授权规则也适用于更改,不适用于状态。它们可能像这样表述:“只有经理 [被授予经理角色的用户] 可以更新 salary 属性的值”或“只有与要创建的员工所在部门相关联的经理才能创建新员工记录”。
这些规则不描述数据的完整性(现状如此),也不能用于验证静态数据集合。这些规则只控制事务的有效性,并且应在发生更改时强制实施。
数据质量
数据完整性是关于数据集合的内部、系统级一致性。没有数据完整性,数据的质量就很值得怀疑。不过,数据完整性跟数据质量肯定不是一回事。即使系统中记录的数据遵循所有完整性约束,这些数据也可能不是现实世界的正确标书,因此达不到最佳质量。人名、街名可能会出现拼写错误。还可能出现无意的重复 — 多条记录表示同一现实世界实例,如人、对象……或事件。无意重复如果遇上记录彼此不一致,情况将更加复杂。
数据可能会因为不再相关或者(更糟的是)不再准确而过时。世界会发生变化 — 人们人会变更地址、买卖产业、换工作、生老病死。如果假设代表现实世界的系统中没有反映出这些变化,记录的数据就会变得不那么准确了 — 即使它的完整性可能完好无缺。
健壮性级别
各个数据约束的重要性可能并不一样。有些可能要求执行非常严格,有些则不一定。当然,日常生活中也同样如此。例如,在社会环境中,有许多规则规范着人们的行为。有些是法律强制实施的;有些则是习俗使然,还有些介于二者之间。再比如:有时,出于对雇主的怨恨,员工可能极其严格地遵循正式规则,意图拖延,推三阻四。
显然,对于必须以何种严格级别来实施规则,可能存在明显区别。这也适用于数据约束。区别来自于几个考虑因素,包括约束理由(法律、健康、KPI、QA)、实施成本以及严格实施的开销。
- “必须总是这种情况”。
- “必须永远这样”。
- “就应该这样”。
- “理想情况下,应该这样”。
- “最好像这样做”。
针对市场研究环境的简单约束可能是“一个客户不应多次参与一项特定的问卷调查”。它是一个意向 — 但很可能不值得花大力气去实施。针对古典摇滚电台的约束可能是:“一首歌一周最多只能播放一次”。同样,这也是定义一个意向,违反此约束可能不值得炒某人的鱿鱼。
谈到数据约束的实施,很显然,在需要 100% 确定性实施某些约束与“几乎总是实施,有时可能有点小意外”之间,工作量存在着明显差异。
还有另外一种选择:是否能够永远不违反约束 — 可能对数据的使用者可见 — 或者定期扫描数据并确保从长期来看不存在无效数据,这样做是否足够?
在第一种情况下,在系统中最终确定任何更改之前,必须先执行约束验证。这意味着约束验证是同步执行的,直接影响进行更改的一方所感知的系统响应时间,并且(我们稍后将看到)还会锁定资源,这可能会影响系统可扩展性。在这种情况下,任何尝试向系统提交更改的一方将立即知道这些更改是否可接受并被成功记录。
在第二种情况下,约束验证相对实际更改本身是异步执行的。后台进程扫描已经记录的数据并测试有效性,即完整性。发现违反行为时,将启动(可能需要人工干预)某个进程来处理意外情况。根据违规的严重性,可以删除记录、将其标记为无效、添加到“待纠正”列表或以其他方式进行处理。
注意,在此情况下,可以采取分两步走的过程:先暂时提交更改,仅当执行完脱机检查之后,这些更改才会真正生效。在提交时间与后台验证进程的这一确认时间戳之间,这些更改对系统使用者尚不可见。
如果没有这个分两步走的过程,在数据提交和后台验证之间的时间内使用者从系统读取的可能是无效数据。根据可能未满足的约束性质的不同,这可能根本就不是个问题。
本文将重点介绍实时、联机同步约束实施以实现连续的数据完整性的情况。
事务
通常,我们不会在雕塑家的作品尚未完工之前批评这件作品的质量,不会在厨师烹饪的时候就抱怨食物的味道,也不会在记者尚未提交发表时就抱怨文章中的拼写错误。当道路尚处于施工中就评价它是否平整同样没有意义。
同样的道理也适用于数据完整性约束。只有当用户或系统正在对数据进行的更改完成时,才应该实施这些约束。约束不必适用于该过程的每个阶段。只有当工作完成并“已提交发布”,才需要完全实施和遵循约束。当我们谈到 IT 环境中的数据时,术语“commit(提交)”用于描述提交发布的过程。包括所有更改的工作单元称为“事务”。在事务准备期间(提交更改之前),可以暂时违反约束。在此期间,事务中数据的状态在事务外面不可见。在事务外面看不到无效数据,使用者无法从系统检索到不符合完整性约束的数据。

图 6
术语“回滚”用于描述撤销事务中生成的所有更改的操作。当厨师中断烹饪过程、将所有锅碗瓢盆(至少其中装的东西)扔进垃圾箱,作家将文章揉成一团或者雕塑家毁掉未完成的雕塑,这时再去品尝味道、检查拼写或评价艺术质量就毫无意义了 — 工作已经取消,不再有什么关系了。同样的道理也适用于回滚事务:就像事务从未存在过一样。在事务期间可能进行过的所有更改都被反转,事务本身什么也没有留下。
会话
会话是使用者与系统交互的上下文环境,不管是检索数据还是执行数据操作事务。使用者可以对应于一个最终用户(的确经常如此),但该使用者也可能是一个自动代理(如批处理程序)、外部服务使用者或自动化业务流程。目前,系统通常同时处理许多会话 — 从几十个到几千个甚至上千万个(这种情况出现在 Twitter、Facebook 和 Google Mail 等全球系统中)。
会话跟事务一样都是私有的:会话彼此不交互。一个会话中的动作在另一个会话中不可见,也不影响其他会话。只有当一个会话中的事务提交,其他会话才能体验到该事务的效果。不过要注意,会话可能会声明资源(通过锁定),因此可能会影响其他会话,阻止这些会话在当时声明同一资源。资源的例子包括各条记录、整个数据集合或自定义令牌。
会话的概念(甚至该术语本身)用于不同级别。Web 浏览器中的用户在会话中执行动作。这种浏览器会话自用户到达某个网站或访问某个 Web 应用程序时开始,持续到该站点被放弃、用户退出该应用程序或该浏览器关闭之时。访问 Web 服务的代理可以在包括多次交互的会话中这么做。与数据存储进行交互的批处理过程可以在一个或多个事务中执行许多操作,所有这些操作通过与该数据存储的同一连接在同一会话上下文环境中发生。

图 7
与会话的概念相关的是连接(与应用程序或数据存储等系统的连接)和身份(使用基于凭证的身份验证发起会话的代理的身份)这两个术语。
约束实施剖析
实施约束、实现完整性目标最简单的方式是完全拒绝允许任何数据操作。只有通过更改才能将现有状况从完整性完好状态变成完整性缺失状态。可以通过阻止更改来保持现状。
显然,这种策略并不可行,但它清楚地说明了一点:更改触发实施。我们不必不断地检查所有约束 — 只需在数据发生更改时进行检查。而且不必针对所有数据操作检查每一条约束:更改客户姓名不大可能导致违反产品价格约束。而且,假设对客户姓名设置了一条属性约束,则更改一个客户的姓名无需检查所有未动过的客户姓名来验证是否继续遵守该约束。我们可以关注更改过姓名的客户记录。
这一点奠定了实现约束实施的基础:
- 仅当数据发生更改时实施。
- 实施数据更改类型可能违反的约束。
- 对发生数据更改后有违反约束危险的记录实施约束。
我们已经知道,只有作为事务提交的一部分,实施才有必要。在此之前,当事务尚在编写过程中而数据仍处于不确定状态时,可以违反约束。在提交前的任何时刻遵守约束是无意义的:只在提交时才算数。注意,更改在验证到提交之间的时间段不应突然失效。在多会话环境中,这不是小事。有关这种情况的详细信息,请参见下一节“釜底抽薪”。
如果知道哪些数据操作事件可能导致违反某条约束,并且知道事务包含哪些数据操作,就可以将后者映射到前者,确定在事务提交时验证哪些约束。
实施高效、强健的数据约束验证机制需要仔细分析约束:对哪些实体(具体来说,对于更新则是哪些属性)的哪些数据操作(创建、更新、删除)可能会违反约束。此外,在事务运行时,该机制需要能够确定:哪些实体经历了哪些更改(创建、更新、删除),对更新而言,哪些属性被修改过。综合这些因素,可以告诉我们需要对哪些记录验证哪些约束。
下表包含了一个针对一些不同类型的约束进行约束数据操作分析的例子:
| 范围 | 约束 | 数据事件分析 | |
| 属性 | Salary 属性的值必须为 1000 到 5000 之间的整数 | - 创建 - 更新 Salary 属性 | |
| 字节组(记录) | 对于 Job(属性值)等于 SALESMAN 的员工,Salary 属性的值不应超过 2500。 Salary 和 Commission 属性的总和不能高于 10000 | - 创建 - 更新 Salary 或 Job 属性 - 创建 - 更新 Salary 或 Commission 属性 | |
| 实体(表) | 在特定工作中员工姓名应是唯一的。 从事相同职位的所有员工的最高工资与平均工资之间的差距不得超过平均工资的 30% 作为其他员工经理的员工,其 Job 属性应为 MANAGER 或者与其每个下属的 Job 属性值相同 | - 创建 - 创建 - 创建 | |
| 实体间(跨表) | 引用完整性(外键):所有用于 Department 属性的值都必须存在于 Departments 表中某条记录的 DepartmentId 属性中。 | - 创建 (Employee) - 删除 (Department) - 更新 Department 引用 (Employee) - 更新 DepartmentId 属性 (Department) | |
掌握了约束事件分析和如何确定待处理事务包含哪些数据操作,约束验证机制就可以完成工作。事务完成并由拥有会话的用户或代理提交确认时,将启动约束验证机制。它将在该会话的上下文环境中执行验证,在此环境下,所有待处理的更改以及所有先前从其他会话提交的更改均可见。在其他会话中可能待处理的任何未提交更改将不可见,因为它们尚未提交(且可能永远不会),它们与事务的约束验证无关。

图 8:约束实施器
约束实施器的一个可能算法可能是:
- 确定哪些实体和属性因为当前事务中的哪个操作而发生更改。
- 确定哪些约束可能被这些更改违反且因此应予以实施。
- 根据事务的范围,确定必须对哪些记录执行此实施。
- 对所有约束和记录进行迭代;验证记录的约束;确保对于刚检查的约束(不能过久,为此引入了一个锁定机制),此时在其他会话中不能存在可能影响记录有效性的提交。
- 报告结果:要么所有验证成功且事务通过检查,要么一项或多项验证失败。事务不能继续。报告违反约束。
釜底抽薪 — 多会话环境中的约束验证
在多会话环境中,其他会话中提交的更改可能会使已经对所有约束验证成功的数据操作从完全有效转变成违反约束。这可能会导致无效数据被提交。
图 9 显示了一个简单示例。示例中定义了一个实体,它只有一条约束,即 NAME 属性必须唯一,因此对于集合中的每条记录,该属性必须具有不同的值。最开始是满足这一条件的。现在有两个活动会话。这两个会话都创建一条新记录,其 Name 属性设置为值 JOHNSON。
用户提交事务时,将启动对该会话的约束实施。由于在此会话范围内,只有一条记录 NAME='JOHNSON',所以对于此唯一性约束,该更改通过验证。与此同时,在第二个会话中也提交(或者更确切地说,提交确认)了此事务。约束实施器对第二个会话执行与对第一个会话相同的操作。它也没有发现创建 NAME='JOHNSON' 的记录有什么错误 — 因为在第二个会话的范围内目前没有这样的记录。第二个事务也通过验证,可以继续。

图 9:多会话环境
因此,两条记录均成功提交。但是,这明显违反了唯一性约束,这正是我们要防止出现的结果。注意,之所以发生这种违规,可能是因为第一个会话中的创建在第二个会话中不可见(因为当会话 2 中进行验证时,会话 1 的提交尚未完成)。图 10 显示了具体情况:黄色椭圆表示会话 2 中的验证不包括会话 1 的更改,橙色椭圆表示验证不包括会话 1 中事务的影响。

图 10:违反唯一性约束
我们似乎在面对第 22 条军规:会话 2 中的验证不能在会话 1 的更改提交之前包括会话 1 的更改,但不能忽视这些如此明显与会话 2 中的操作冲突的更改。这一挑战的解决办法是使用独占锁定。一个会话可以使用此类锁定防止其他会话进行可能导致上例中所示无效结果的更改。
这些锁定的使用方式可能非常粗放,从而导致其他会话无法安全地执行许多操作。例如,对于本示例中的 Name 唯一性约束,可以使用锁定,一旦执行 Name 的 create 或 update 操作,就阻止其他会话中出现任何 update 或 create 操作。这种方法注定会造成许多挫折,尽管完全没有必要如此。可以代之以一种更精细的方法,不使用锁定来阻止数据操作,而是使用锁定声明执行约束验证的独占权。在前面讨论的示例中,该锁定的使用方式如图 11 所示。

图 11:锁
当会话 1 开始唯一性约束验证时,它会尝试获取对该约束的系统级锁定。因为当前没有其他会话持有该锁,所以系统会授予此锁定,会话 1 可以继续。与前面一样,它发现新 JOHNSON 记录没有问题。
与此同时,会话 2 也开始了事务的验证阶段。它也必须验证 Name 属性是否符合唯一性约束。它尝试获取该约束的 PSN_UK23 锁,但失败。我们知道是因为什么:此锁定目前被会话 1 持有,该会话正在进行自己的验证。会话 2 可以等待该锁定变成可用状态,或者也可以停止处理并返回异常。如果选择等待,只要会话 1 释放该锁定,它就可以继续。当会话 1 提交时就会发生这种情况。此时,会话 2 可以开始验证事务是否符合唯一性约束。此时,该验证将包括会话 1 产生的更改,包括 NAME='JOHNSON' 的新记录。这意味着会话 2 针对唯一性约束的验证将失败,事务将被拒绝,并可能回滚。
注意,可以通过更精细的方式定义这个锁定:我们可以不为约束 PSN_UK23 采取锁定,而是对该约束以及 Name 属性的新值(在本例中为 {PSN_UK23, JOHNSON})采取锁定。这意味着,即使会话 1 正在慢慢处理针对 JOHNSON 值的 PSN_UK23,针对 Name 的其他值的约束验证仍然可以继续并获得锁定。
我们将在本文后面进一步看到,Oracle Database 采用这种精细的锁定方法作为实施其声明性约束的内部方式。
全局事务和分布式事务
到现在为止,我们的讨论尚未针对一个特定的环境。必须应用数据约束的数据存储可以是关系数据库、内存中数据网格、内容管理系统、文件系统、基于云的存储或任何其他数据管理机制。不过,我们的确曾假定涉及的是处理数据、事务、会话和约束实施的单一数据存储。但实际情况并不总是这样。因此,必须在本案例中增加一层复杂度:多个数据存储及跨数据存储的事务。如果数据可以保存在多个数据存储中,则可以单独描述每个数据存储的数据完整性,让使用者依次与这些存储中的每一个交互。不过,这样太简捷了一些。

图 12:跨多个数据存储
特别是在面向服务的环境中,不能指望使用者了解多个数据存储。在分离的世界中,使用封装的服务实现,我们可能希望提供实体服务和组合业务服务来公开可能跨多个数据存储的操作。
用户或代理尝试执行的事务是一个逻辑单元。事务要么全部成功,要么全部失败。不应部分提交事务 — 一个数据存储发生更改,而其他数据存储不发生更改。
因此引入了全局事务的概念,有时也称作分布式事务。全局事务是一个事务,一个一致的逻辑单元,应作为一个整体提交或不提交。全局事务跨两个或更多个事务资源,如数据存储。这些资源中的每一个都能够管理自己的事务以及这些事务的数据完整性。
全球事务面临的挑战在于将其中每个资源的事务机制扩展到更高的层次,使它们参与联合事务,所有资源共同协调取得成功(提交)或失败(回滚)。这种协调通常涉及两个阶段(因此产生术语“两阶段提交”或 2PC):每个事务资源启动一个会话,应用所有更改,执行所有约束验证。然后,该资源向事务协调器报告其成功(或失败)。注意,在第 1 阶段结束时,每个事务资源将对已更改的记录和已针对这些记录验证的约束保持锁定,以确保整个事务不会被其他(分布式或本地)事务翻盘。

图 13:第 1 阶段
如果所有资源都报告成功,则全局事务所有参与方通过验证,可以开始第二个阶段。每个事务资源完成提交,发布更改并释放所有锁定。注意,只要有一个事务资源报告失败(例如,因为违反约束),将放弃全局事务并指示每个资源回滚所有更改。
分布式约束
实体间约束涉及两个或更多个数据集合。很有可能并非所有这些数据集合都属于同一数据存储。因此,对这些约束的验证可能跨越数据存储的边界。
图 14:第 2 阶段
从概念角度来看,以及在实施过程中,使用跨多个数据存储的全局事务的要求并不是个小事。尽管在许多环境 — 包括 Java/JEE、Oracle SOA Suite 和 Oracle Service Bus — 中对分布式事务提供了强健的支持,增加的复杂度也不是轻易就能吸收的。

图 15
这引发了一场有趣的、有时还很激烈的关于如何处理这种情况的讨论:在哪里实施此类分布式约束以及如何实现分布式锁定以防止事务彼此干扰。有些人甚至质疑跨事务资源约束的有效性 — 辩称独立数据存储并非真正独立,如果在它们之间定义了约束的话。
除了这种理论上的辩论,还有实现约束实施所需工作量和所涉及技术的能力问题。一个数据存储中的约束实施器是否甚至能够访问另一个数据存储中的数据?它是否能够请求对其他数据存储中约束的锁定,并以适当的方式释放该锁定?
本节将讨论跨数据存储服务的实现(使用 Oracle SOA Suite),此服务不仅使用全局、分布式事务,还管理跨数据存储约束。简而言之,这种情况的通用算法应如下所示:
- 代理或最终用户提交确认事务。
- 发起全局事务。
- 在此全局事务的上下文环境中,为每个涉及的数据源启动事务;代理或最终用户提交的数据操作将被路由到应处理它们的数据源。
- 每个数据源执行 2PC 周期的第 1 阶段:应用更改、对更改的记录和要验证的数据约束采取锁定、以正常(本地)方式实施约束。
- 回头向事务管理器报告第 1 阶段的结果;要么成功应用所有更改并成功实施所有约束,要么一个也不应用和实施。在后面这种情况中,将放弃全局事务,并指示所有数据源回滚其本地事务 — 恢复所有更改并释放所有锁定。
- 确定全局事务中的操作可能会违反哪些分布式约束,并确定必须针对哪些记录执行实施这些分布式约束。
- 对所有这些分布式约束进行迭代;获取对约束的锁定(基于所涉及的记录,可能结合了特定的值);使用所有涉及的数据源中的数据验证该约束 — 这些数据现在处于当前事务结束时的最终状态;注意,分布式约束的验证需要发生在当前全局事务的上下文环境中,以便查看该事务的所有影响 — 不能对此验证使用单独的会话。
- 如果成功实施所有触发的分布式约束,则全局事务可以继续。(否则,将放弃全局事务,并指示所有数据源也放弃事务;并报告违反约束。)
- 全局事务中涉及的每个数据源将执行本地提交,并释放对更改的记录或实施的约束的所有锁定;最终还将释放所有全局资源锁。
这种算法还产生了一个必须解决的有趣问题:分布式约束所要求的锁定在哪里?需要此锁定来防止多个并发事务同时对同一约束执行验证,这些事务每个在自己的上下文中,范围内只有自己的更改,在一起存在导致无效情况的风险。该锁定确保只一个事务可以实施约束,包括它自己的未提交更改。如果所有事务都是全局事务,某个锁定提供程序服务提供的一个全局锁定就足够了。不过,通常情况下除了全局事务,还有针对每个单独数据源的本地事务。在这些情况下,需要本地锁定。我们将稍稍进一步详细讨论这一点。
分布式引用完整性
现在我们看一个简单分布式约束例子,以及上面介绍的通用算法如何作用于此约束。数据源 A 包含 Employee 记录的数据集合,数据源 B 有 Department 记录的数据集合,还有一个分布式约束 EMP_DEPT_REF1,表述如下:“每条 Employee 记录必须通过其 DepartmentId 属性引用数据源 B 中集合中的一条 Department 记录。”
![[FILENAME]](/ocom/groups/public/@otn/documents/digitalasset/1929201.png)
图 16:简单分布式约束
对此分布式约束进行一次快速的数据事件分析,可以得知应对这些数据事件实施此约束:
- 创建员工(在数据源 A 中)。
- 更新员工 — 属性 DepartmentId(在数据源 A 中)。
- 删除部门(在数据源 B 中)。
我们将假设不能更新用于从 Employee 引用的 Department 记录的 identity 属性。以上意味着数据源 A 和数据源 B 中的数据操作事件都可以触发实施分布式引用约束 EMP_DEPT_REF1。这两个数据源都需要了解此事实。且这两个数据源都需要有某种方式来使此实施发生 — 以某种方式在某个位置。
图 17 显示创建新员工的情况下的提交周期:

图 17:提交周期
正式的步骤可以描述为:
- 代理或最终用户提交确认事务。
- 将待处理数据(新员工记录)写入数据源 A。
- 在本示例中,“create employee”事件触发一个数据约束:EMP_DEPT_REF1。现在应由此事务在新员工记录的 DepartmentId 属性所指示的部门上下文环境中获取对该约束的锁定。必须同时在数据源 A 和数据源 B 中(或在跨这两个数据源的某个全局级别)获取这种锁定。
- 如果约束成功实施,则事务可以继续。完成本地提交并释放对该约束的锁定(全局和/或同时在数据源 A 和数据源 B 中)。
图 18 显示未同时针对两个数据源获取对分布式约束的锁定时可能发生的一种情况:

图 18
如果数据源 A 中创建新员工的事务所获得的锁定并不涵盖数据源 B,则可能发生以下情况:在一个事务中发生创建员工时,另一个事务正在删除新 Employee 所引用的 Department。如果数据源 B 中的并发事务能够在 EMP_DEPT_REF1 上获得自己的锁定,它将继续,检查是否有任何员工引用该 Department。但没有发现尚未提交的新员工,然后该事务将删除新 Employee 认为它引用的 Department(因为在第一个事务中,删除尚不可见,约束实施也成功了)。
分布式约束实施和全局事务示例
再次假设两个独立数据源 A 和 B 的情况,它们分别具有数据集合 Employees 和 Departments。我们进一步假设为这些集合定义了以下数据约束:
Employees:
- Salary < 5000 (EMP_ATT_1)。
- 每个 Department 最多有一个 Employee 的 Job 等于 MANAGER (EMP_ENT_1)。
- 对于 Job(属性值)等于 SALESMAN 的员工,Salary 属性的值不应超过 2500。(EMP_TPL_1)。
Departments:
- Department 的 Name 必须是唯一的 (DEPT_ENT_1)。
- 任何 Departments 均不应位于 Boston (DEPT_ATT_1)。
分布式:
- Employee 记录(数据源 A 中)中用于指示 Department 的 DepartmentId 应实际精确对应于一个 Department(数据源 B 中)的 Id 值 (EMP_DEPT_REF1)。
我们进一步假设一个全局事务,它通过多个数据操作同时作用于两个数据源:
- 创建一个新员工,其 DepartmentId 等于 42。
- 更新员工:Job 更改为 MANAGER,而 salary 更改为 4000。
- 删除一条员工记录。
- 将 Department 的名称更改为 Child Affairs。
- 删除一个部门 — 其标识符值为 567。
现在我们需要事务协调和约束实施方面的工作,执行前面介绍过的步骤:
- 代理或最终用户提交确认事务。

图 19
- 发起全局事务。
- 在此全局事务上下文环境中,针对每个涉及的数据源启动事务。将代理或最终用户提交的数据操作路由到应处理它们的数据源:将对员工记录的一个 create、一个 update 和一个 delete 操作路由到蓝色数据源,将对部门记录的一个 update 和一个 delete 操作路由到红色数据源。
- 每个数据源执行 2PC 周期的第 1 阶段,应用更改、对更改的记录和要验证的数据约束采取锁定、以正常(本地)方式实施约束:

图 20
- 向事务管理器报告第 1 阶段的结果。假设成功应用所有更改且成功实施所有约束。
- 全局事务(无论是启动还是协调)确定全局事务中的操作可能会违反哪些分布式约束,并确定必须针对哪些记录执行实施这些分布式约束。很明显,对于 Department 42(新的 Employee 记录中引用的部门)和 Department 567(全局事务中删除的部门),分布式约束 EMP_DEPT_REF1 冒着被此全局事务违反的风险。
- 对所有这些分布式约束实例进行迭代;分别结合使用 DepartmentIdentifier 42 和 567 以获取针对约束 EM_DEPT_REF1 的锁定(从尚未识别的全局锁定协调器),并使用发布到这两个数据源的数据对约束进行验证。它不能使用单独的会话进行验证,而应使用将更改发送到各数据源的会话。(注意:需要保留已成功实施的数据约束上的所有本地锁定,直至准备提交全局事务。)

图 21
- 注:根据分布式约束的实施和是否能够本地访问数据源(无需通过全局事务协调器),仅对分布式约束保持全局锁定可能是不够的。可能需要在一个或多个涉及的数据源中显式获取对这些分布式约束的锁定。图 22 显示了一个针对约束 EMP_DEPT_REF1 的锁定的例子。注意,在一个或多个本地事务中的此类本地锁可能实际上是当全局锁定管理器不可用时实现全局锁的一种方式。
只要此全局事务对部门 42 和 567 的约束 EMP_DEPT_REF1 保持锁定,没有其他事务可以提交可能违反这两个部门的约束的更改。这是因为这些其他事务也必须针对其更改实施该约束,但不能这样做,因为它们不能获取实施所需的锁定。这是一件好事。实际上,这正是我们所追求的:一种防止一个事务中正在进行约束验证时被其他事务釜底抽薪的方式。当我们正在验证或已经验证可以在部门 42 中创建新员工时,所有人应无法删除该部门。 - 如果成功实施部门 42 和 567 的触发分布式约束实例 EMP_DEPT_REF1,全局事务可以继续。
- 全局事务通知数据源它们可以执行本地提交,因此终结更改,并释放对更改的记录和实施的约束的所有锁定。最后,还释放所有全局资源锁定。

图 22
总结
IT 系统的业务价值由多种因素决定,其中一个就是系统产生的数据的质量。其质量依赖于系统中数据准确表示现实世界的程度。我们可以采取的一种提高数据质量的措施是对从业务规则派生的数据实施约束。更具体地说,需要确保在系统中操作数据的事务只有在满足所有约束时才能完成。但要注意,有时在每个事务期间立即实施所有约束的成本过高(在性能开销、实现工作量或技术可行性方面),异步、脱机验证是更好的替代方案。
本文介绍了四种类型的约束,范围从一个属性到一条记录,再到甚至可能位于多个独立数据源中的多个数据集合中的多条记录。根据数据源中可用技术的不同,每种类型的约束以不同方式触发,并以不同方式实施。
本文还解释了为什么强健、同步(或实时)的约束实施需要锁定机制来防止并发会话与事务之间的过度干扰。这种锁定机制可以是细粒度的,只锁定约束和尽可能最小的数据范围。
跨多个数据源的分布式约束和分布式事务需要稍微更复杂的程序来验证事务。对每个数据源应用更改并执行每数据源约束实施之后,需要实施分布式约束 — 也是使用约束锁定来防止会话干扰。只有当所有本地验证成功并且实施分布式约束时,才能提交所有本地事务。
致谢
作者希望感谢 ACE Alumnus 总监 Toon Koppelaars 对本文的认真审阅以及他提出的许多宝贵的改进意见。
资源
以下资源为本文提供了灵感和补充信息。- 数据质量,Wikipedia。
Oracle Database 中的数据完整性
- Applied Mathematics for Database Professionals(第 11 章),作者:Lex de Haan 和 Toon Koppelaars(Apress,2007 年出版)。
- 触发器的问题,作者:Tom Kyte(Oracle Magazine,2008 年 9 月)。
- 关于事务级别,作者:Tom Kyte(Oracle Magazine,2005 年 11 月)。
- 关于外部表查询和数据一致性,作者:Tom Kyte(Oracle Magazine,2012 年 11 月)。
SOA Suite 11g、数据库适配器和 BPEL、全局事务
- Oracle SOA 11g 组合中的全局事务和本地事务,作者:Sandeep Phukan(博客:The Real Ranch!!!,2011 年 10 月)。
- JTA 事务 — 本地事务和全局事务。Oracle BPEL 应用程序示例,作者:Arun Ayyappan(博客:Integration Spot by Arun,2011 年 3 月)。
- ORA-02089 — 不允许 COMMIT,作者:Arik Lalo(博客:Oracle Fusion Middleware,2012 年 4 月)。
- 在 11g 中使用 JMS 或 AQ 和 BPEL 的全局事务,作者:Erik Wramner(博客:Erik Wramner Tips and Tricks,2011 年 11 月)。
- 第 9 章:用于数据库的 Oracle JCA 适配器,适用于各种技术适配器的 Oracle 融合中间件用户指南 11g 第 1 版 (11.1.1.6.3)。
关于作者
Lucas Jellema 自 1994 年起就活跃于 IT 领域(在 Oracle)。作为专注于 Oracle 融合中间件的 Oracle ACE 总监,Lucas 担任了多个领域的顾问、培训师和讲师,包括 Oracle Database(SQL 和 PLSQL)、面向服务的架构、ADF 和 Java。他是《Oracle SOA Suite 11g Handbook》一书的作者,并经常在 JavaOne、Oracle 全球大会、ODTUG Kaleidoscope、Devoxx、OBUG 和其他会议上作演讲。
联系 Lucas Jellema
![]()
![]()
![]()