リレーショナル・データベースとSQLの基本に関するシリーズ記事のパート1
今日のOracle Databaseインスタンスの操作に熟達したプロフェッショナルに、パフォーマンス問題に関するもっとも大きな不満点を尋ねてみると、たいていは"SQLの専門知識が不足している"、"SQL文の書き方がまずい"、あるいは"データベース・プログラマーがほとんどトレーニングを受けていない"という答えが返ってくるでしょう。リレーショナル・データベースが日常業務で必須になり、それにつれてStructured Query Language(SQL)の知識も重要なものになりました。しかし、逆説的ではありますが、良いSQLプログラミング技法の学習は、たとえばJavaなどのデータベースに依存しないプログラミング言語によって記述された使いやすく魅力的なインタフェースの作成よりも後回しにされます。自分で選択した(もしくは人に指定された)インタフェース言語の学習に非常に多くの時間を費やし、SQLの学習にはほとんど(あるいはまったく)時間をかけないプログラマーもいます。
このSQLの基礎に関するシリーズ記事は、リレーショナル・データベースの概念やSQLコーディング構文について学習したことのない方や完全に習得していない方を対象にしています。SQLの学習者、ワークグループ内のメンバーへのSQL教育担当者、データベース・アクセス用のコードを記述するプログラマーの管理者など、あらゆる読者が対象です。この第1回の記事ではまず、すべてのプログラマー(またはDBA、設計者、管理者)が初めてSQL文一式を記述する際に知っておくべき基本的な構築ブロックについて説明します。
リレーショナル・データベースでのデータの構造化方法
データベースでのデータの構造化方法を視覚化できることは、そのデータを迅速かつ容易に取得するための鍵になります。ATMから現金を引き出すときにはかならず、データを読み取って操作しています。商品をオンラインで購入するときにはかならず、データを変更しています。銀行取引や買い物、その他の多様なビジネス・アクティビティのいずれかを実行するときには、リレーショナル・データベースとやり取りしている可能性が高いのです。
リレーショナル・データベースは、表と呼ばれる2次元マトリックスにデータを格納します。表は一般的に、複数の列と行で構成されます(ここで「一般的に」と言ったのは、行がなく1つの列だけを含む表を作成することも可能だからです。ただし、これはまれな状況です。この例外については、このシリーズ記事で後ほど取り上げます)。リレーショナル・データベースでは、リレーショナル・データベース管理システム(RDBMS)ソフトウェアが利用されます。RDBMSは、特定の情報が見つかる正確なファイルやドライブのストレージ・デバイス内の位置を知らなくても、ユーザーがデータの読取りや操作を実行できるようにするタスクの管理を支援します(Oracle Databaseも、多数あるRDBMSの1つです)。ユーザーは、どの表に探している情報が含まれているかを把握しているだけでよいのです。RDBMSはユーザーが記述するSQL構文とSQLキーワードを頼りに、表や、その表の行/列に含まれるデータにアクセスします。
リレーショナル・データベースでのデータの表現方法
通常、リレーショナル・データベース内の各表には、ある単一の型のデータに関する情報が含まれ、そのスキーマ内にある他の表と区別するための一意の名前が付けられます。一般的に、スキーマとは、類似したビジネス機能を扱うオブジェクトのグループ(表など)のことです。たとえば、3つの表があり、各表にそれぞれ従業員、部門、給与明細に関するデータが含まれる場合、これらの表はHRという名前のスキーマ内にまとめて配置できるでしょう。このHRスキーマ内には、EMPLOYEEという名前の表は1つしか格納できません(この記事では概要を説明する目的により、Oracle Database 11gのエディションやエディションベースの再定義といった同じ名前を持つ複数の表の共存をサポートする機能については、説明を省略します)。ここで、EMPLOYEE表の情報が、図1のような構造と内容になっているとします。
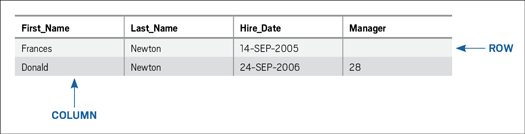
図1:EMPLOYEE表
表は少なくとも1つの列で構成されます。列とは、特定のデータ型の値の集合です。スキーマ内の表の名前と同様に、列の名前は表内で一意です。また、その列に含まれるデータの型を明確に識別するものである必要があります。たとえば、まず初めに簡潔に表現された上記のEMPLOYEE表には、従業員の名(FIRST_NAME)、姓(LAST_NAME)、雇用日(HIRE_DATE)、マネージャー(MANAGER)の各列があります。図1では、従業員のLAST_NAME列のNewtonは、その表内のある1つのデータ要素です。また、HIRE_DATE列の14-SEP-2005は別の1つのデータ要素です。
さらに、ある表のそれぞれの行は、1つのデータ・セットを表します。たとえば、EMPLOYEE表の中で、FIRST_NAME列がFrances、LAST_NAME列がNewtonである行が、1つの固有のデータ・セットとなります。ある列とある行が交差するそれぞれの部分が、1つの値を表します。ただし、一部の値は存在しないことに注意してください。図1では、MANAGERの行/列の交差部に、値が含まれていないものがあります。この場合の値はNULLと呼ばれます。NULL値は、空欄でも空白でも0(ゼロ)でもありません。値がないことを示すものです。
良いリレーションの鍵
ある行が特定のデータ・セットを一意に表すためには、その表内の行/列の交差部全体に対して、その行が一意である必要があります。たとえば、EMPLOYEE表を使用する企業が2005年9月14日にFrances Newtonという別の従業員を雇用することになり、しかもEMPLOYEE表のこの従業員の行にMANAGER値がまだ関連付けられない場合は、元々のFrances Newtonのエントリは一意ではなくなります。このように同一のデータが同時に発生することを、重複と言います。表への重複エントリの追加は許可すべきではありません(この理由については今後の記事で詳しく取り上げます)。そのため、このEMPLOYEE表には、名前と雇用詳細情報が同じである複数の従業員を雇用したとしても、すべての行の一意性を保証するための列が必要です。
ここで、主キーの登場です。主キーとは、ある表内のすべての行の一意性を保証する列のことです。主キーをEMPLOYEE表に追加すると、2人のFrances Newtonsは同じではなくなります。一方のEMPLOYEE_IDの値が37、もう一方のEMPLOYEE_IDの値が73になるからです。図2に、先ほどのEMPLOYEE表にEMPLOYEE_IDという主キーを追加した表を示します。
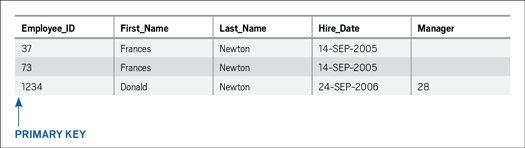
図2:主キーであるEMPLOYEE_ID
EMPLOYEE_IDの値は、各行内のそれ以外の行/列交差部の値と特に関係がないように見えます。言いかえれば、EMPLOYEE_IDの値は従業員データ自体とは関係ありません。この種のキーは多くの場合、システムにより自動生成される連番です。また、表内の他のデータ要素とは関係がないために、合成キーまたはサロゲート・キーとも呼ばれます。そのようなキーを使用すれば、各行の一意性を維持しやすくなります。このキーは更新されることはなく、したがって不変であるためです。主キーの値が変更される事態は避けることが賢明です。変更されれば、結果的に管理がほぼ不可能なほど複雑になります。
1つの表に設定できる主キーは1つだけで、その主キーは1つまたは複数の列で構成されます。複数の列で構成されるキーのことを、コンポジット・キーまたは連結キーと言います。主キーが不要である、もしくは不適切である場合もあります。しかし、ほとんどの場合は、すべての表に主キーを作成することを強くお勧めします(ただし、Oracle Databaseではすべての表に主キーを設定する必要はありません)。
外部リレーションにおいて慎重に考慮すべき事項
これまでは、1つの表でのデータの構造化方法を中心に説明しました。しかし、リレーショナル・データベースではさらに表が結び付けられ(関連付けられ)、複数の表にわたって情報が構造化されます。
リレーショナル・データベースにおける重要なコネクタは外部キーです。外部キーとは、ある表の特定の列または列のセットを識別し、かつ別の表の特定の列または列のセットを参照するキーのことです。複数の表にわたる外部キーによるリレーションを使用すれば、情報が関連付けられるのに加えて、情報が構造化された状態を維持できます。
たとえば、各従業員の詳細情報とともに各従業員の部門名をEMPLOYEE表に格納する場合によく見られるのが、複数の従業員リストにわたって同じ部門名が繰り返されることです。この場合、部門名を変更すると、その後、その部門に所属するすべての従業員に関するすべての行について、部門名を更新する必要があります。
しかし、図3のようにデータをEMPLOYEEとDEPARTMENTという2つの表に分割していれば、外部キーを使用してデータを構造化することで、2つの表のリレーションシップが同時に確立されます。そのため、更新箇所を最小限に抑えて、可能な範囲内で最大のデータ整合性を確保できます。図3のデータ分割結果を見てみましょう。

図3:外部キーによるリレーションシップの確立したEMPLOYEE表とDEPARTMENT表
図3では、DEPARTMENT_IDはEMPLOYEE表における外部キー列で、EMPLOYEE表とDEPARTMENT表をリンクしています。このDEPARTMENT_ID列でEMPLOYEE表内を検索することで、特定の部門に所属するすべての従業員について、従業員詳細情報をすべて把握できます。DEPARTMENT_IDの値は、部門固有情報を管理するDEPARTMENT表の1つの行に対応します。
少ない方が良く、少ないことが基準
リレーショナル・データベースの理解の鍵となるのが、データの正規化および表のリレーションシップについて知ることです。正規化の目的は、冗長性を排除して、その後のデータの操作による問題の発生を防ぐことです。データの重複を最小限に抑えるためにデータベース設計者が取り組むべき方法のルールが、さまざまな正規形として策定されています。表、列、主キー、外部キーの設計はそれらの正規化ルールに従います。そして、このプロセスのことを、正規化と言います。
正規化には多くのルールがあります。もっとも広く受け入れられているルールは、第1~第5正規形とボイス・コッド正規形です。著者の経験上、多くのプログラマー、アナリスト、設計者は、第3正規形までで正規化を終了しますが、経験豊かなデータベース設計者はその後の正規化も行う場合があるようです。
第1に行うべきこと:第1正規形の表では、すべての繰返しグループを新しい表に移動しなければなりません。図4の例を見てみましょう。この例では、オフィス所在地に関する複数の列がEMPLOYEE表に追加されています。
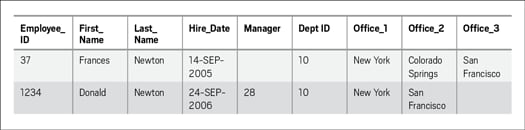
図4:オフィス所在地に関する列を含むEMPLOYEE表—第1正規形に違反
この表には、オフィス所在地の値を格納した列が複数あります。この値は、頻繁に出張するので物理的に複数のオフィス所在地で仕事する必要のある従業員向けの値です。オフィス所在地の値は、OFFICE_1、OFFICE_2、OFFICE_3という3つの列により表現されています。それでは、ある従業員が他の所在地で仕事することが必要になった場合にどうなるでしょうか。
問題の発生を防ぎ、さらに別の列(OFFICE_4)を追加しなくて済むように、データベース設計者は図5のように、このオフィス所在地データをEMPLOYEE_OFFICE_LOCATIONという個別の表に移動します。
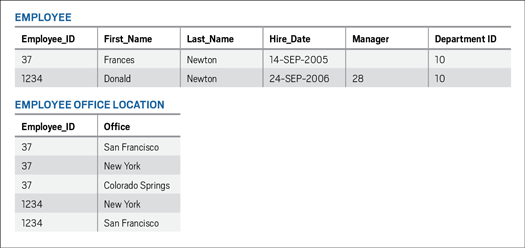
図5:第1正規形のEMPLOYEE表とEMPLOYEE_OFFICE_LOCATION表
第2正規形とコンポジット・キー:第2正規形は、コンポジット主キーを含む表に関係する特殊な正規形です。コンポジット主キーには、2つ以上の列が含まれます。
第2正規形では、すべての非キー列が主キー全体に依存する必要があります。言いかえれば、コンポジット主キーを含む表に追加するすべての非キー列について、主キーの一部のみに依存することはできません。
図6に、EMPLOYEE_OFFICE_LOCATION表を示します。この表では、主キーはEMPLOYEE_ID列とOFFICE列の組合せです。そのため、この表に追加するすべての列が、この両方の主キー列に依存している必要があります。しかし、OFFICE_PHONE_NUMBER列はOFFICE列にしか依存しておらず、EMPLOYEE_ID列には何の関係もありません。

図6:第2正規形に違反
図6のEMPLOYEE_OFFICE_LOCATION表は第2正規形に違反しています。この表が第2正規形に従うには、別の表を作成して、OFFICE_PHONE_NUMBERデータをその新しい表に移動する必要があります。
キーは単なるキー:第3正規形は第2正規形を拡張した形式です。第3正規形では、非キー列のすべてが主キーに関する詳細情報または事実である必要があります。図7は、第3正規形に違反しています。
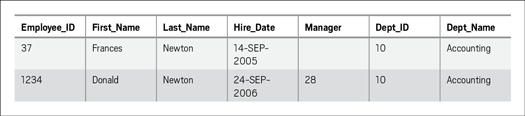
図7:第3正規形に違反
このEMPLOYEE表にDEPT_NAME列を追加したことで、DEPT_NAMEがEMPLOYEE_IDの値ではなくDEPT_IDの値に依存するため、第3正規形に違反しています。第3正規形のルールに従うためには、別の表を作成して、この部門名の値をその新しい表に移動し、EMPLOYEE表からその新しい表への外部キー参照を追加する必要があります(図3に示した解決策が第3正規形を表しています。DEPARTMENT_IDはEMPLOYEE表における外部キー列です)。
SQLの適用箇所
SQLを使用すれば、リレーショナル・データベースでの新しいデータの作成、古いデータの削除、既存のデータの変更、データの取得を実行できます。たとえば、次の文では新しいEMPLOYEE表が作成されます。
次のステップ
リレーショナル・データベースの設計と概念に関する詳細の確認
Oracle Database概要 11g リリース2 (11.2)
Oracle® Database SQL 言語リファレンス11g リリース1(11.1)
その他の記事 SQLの基礎
CREATE TABLE employee
(employee_id NUMBER,
first_name VARCHAR2(30),
last_name VARCHAR2(30),
hire_date DATE,
salary NUMBER(9,2),
manager NUMBER); この文によって、各列(別名データ属性)の名前と、各列のデータ型および長さをそれぞれ指定した表が作成されます。たとえば、次のCREATE TABLE文の行を見てください。
employee_id NUMBER この行により、データ型がNUMBERであるEMPLOYEE_IDという表の列(データ属性)が作成されます。したがって、このEMPLOYEE_ID列は、数値データのみを格納するように定義されます。
SQL SELECT文を使用すれば、データの取得(すなわち問合せ)が可能です。たとえば、次のSQL文は、この記事のEMPLOYEE表からFIRST_NAME列、LAST_NAME列、HIRE_DATE列のすべての値を取得します。
SELECT first_name, last_name, hire_date
FROM employee; 見てのとおり、この構文はかなり単純です
結論
この記事では、リレーショナル・データベースの構造について概要を説明しました。表、列、行について説明し、データの例や、リレーショナル・データベース内でのデータの表現方法について示しました。このSQLの基礎に関するシリーズの次回の記事では、引き続きデータ正規化について説明し、さらにSQL実行環境について概要を紹介します。
