 Artigos
Desempenho e Disponibilidade de Banco de dados
Artigos
Desempenho e Disponibilidade de Banco de dados
Oracle Database em High Availability usando Microsoft Windows Clusters Server (MSCS) e Oracle Fail Safe
Por Carlos H. Y. Furushima
Postado em Fevereiro 2015
Revisado por Marcelo Pivovar - Solution Architect
Objetivos:
- Apresentar conceitos do Microsoft Windows Clusters Server
- Apresentar a arquitetura do Oracle Fail Safe
- Apresentar a integração entre Microsoft Windows Cluster x Oracle Fail Safe
- Descrever a implementação completa da solução Microsoft Windows Cluster com Oracle Fail Safe
Um Cluster consiste em diversos componentes computacionais ligados fisicamente (Hardware - Cabos, Switch, Node, etc.) e logicamente (Software - Microsoft Windows Clusters Server, Oracle Clusterware, IBM HACMP, IBM PowerHA, HP Serviceguard, etc.), que resulta em um sistema distribuído de computadores independentes e interligados, onde basicamente seu objetivo é:
- Alta Disponibilidade (Tolerar falhas)
- Balanceamento de Carga
- Computação de Alto Desempenho
O Microsoft Windows Clusters Server (MSCS) juntamente com uma infraestrutura de hardware forma um ambiente computacional em cluster, tem o objetivo de alta disponibilidade (High Availability), ou seja, a essência de sua existência é tolerar falhas físicas e/ou lógicas.
O que é Cluster de Alta Disponibilidade?
O Cluster de Alta Disponibilidade é normalmente construído com a intenção de fornecer um ambiente seguro contra falhas (fail safe) utilizando-se da redundância de componentes (sejam de hardware, software, serviços ou rede de interconexão). Em outras palavras, fornece um ambiente computacional onde a falha de um ou mais componentes não irá afetar significativamente a disponibilidade do ambiente de computação ou aplicações que estejam em uso. (Definição retirada do artigo cientifico "UM CLUSTER DE COMPUTADORES DE USO GERAL" escrito pelo professor doutor em física computacional José Luís Zem)
A disponibilidade dos serviços e tolerância a falhas é o objetivo a ser atingido em cluster de alta disponibilidade, uma vez que, esse tipo de cluster consiste em dois ou mais computadores conectados em rede juntamente com um software de clusterização (Microsoft Windows Clusters Server - MSCS), que faz um papel de heartbeat (monitor de disponibilidade) entre os nodes do cluster (computadores conectados em rede).
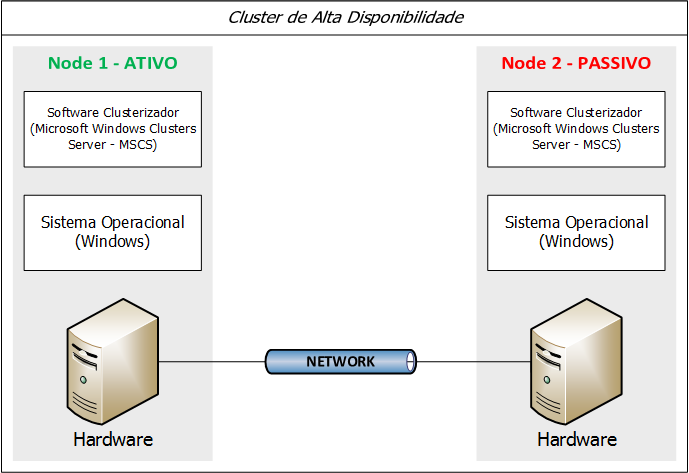
Microsoft Windows Cluster Server (MSCS) e Oracle Fail Safe
Segundo as documentações oficiais da Microsoft, o Microsoft Windows Cluster Server (MSCS) é uma solução de cluster usado juntamente com o sistema operacional Windows, essa implementação permite ao client-users de qualquer aplicação que esteja protegido por esta solução, pouca ou nenhuma percepção de interrupção do serviço prestado, em caso falha (física ou logica).
O Microsoft Windows Cluster Server (MSCS) é composto por dois principais componentes:
- Software Clusterizador (clustering software): Algoritmos de baixo nível que prove a alta disponibilidade das aplicações residente sobre a solução.
- Cluster Administrator: Interface gráfica para administração do cluster.
Nas documentações oficiais da Oracle, a solução de cluster da Microsoft (Titulada como Microsoft Cluster System) é definida sobre duas perspectiva:
- Microsoft cluster hardware (componentes computacionais ligados fisicamente): Dois ou mais sistemas computacionais independentes (titulados como nodes), que estão conectados por meio de uma infra-estrutura de rede e a um storage de armazenamento persistente.
- Microsoft Cluster Server - MSCS (componentes computacionais ligados logicamente): Software que permite a configuração, monitoração e controle dos componentes físicos e lógicos (titulados como "recurso" dentro do cluster).
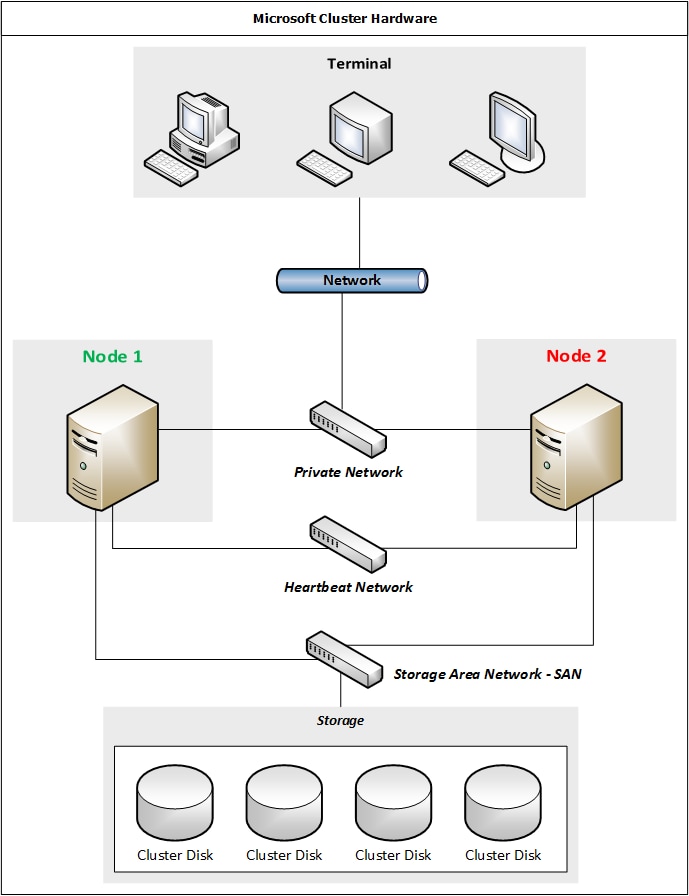
A solução "Oracle Fail Safe", trabalha em função dessas perspectivas acima citadas. Em outras palavras, o "Oracle Fail Safe" é uma espécie de integrador entre Oracle Database x Cluster Microsoft, cujo objetivo é proporcionar um cenário de alta disponibilidade para aplicações e banco de dados Oracle em standalone (single instance).
As aplicações e banco de dados são alojados em um node do Microsoft Windows Clusters e em caso de falha deste, o software de cluster move os recursos para o node sobrevivente, com base nos parâmetros que foram configurado no Microsoft Windows Failover Cluster Manager. Esse cenário é trata-se de um cluster ativo-passivo, também denominado shared-nothing.
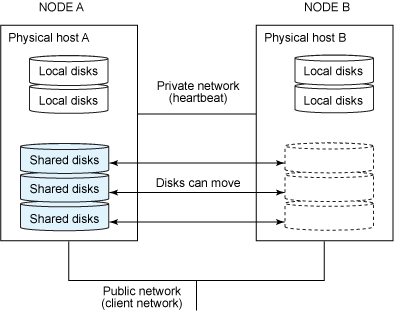
Shared-nothing é uma arquitetura de computação distribuída, onde todos os nodes do cluster estão fisicamente conectados no mesmo storage, contudo, somente um dentre todos é capaz de fazer uso (I/O) deste storage, os outros nodes são coadjuvantes (passivo), e somente faram uso deste recurso, caso ocorra uma falha do node primário ou ativo.
Entende-se por “disponibilidade do serviço” no contexto de Microsoft Cluster System a proteção de um grupo de recursos (Group), que podem ser qualquer componente físico ou lógico disponibilizado para o sistema computacional que é vital para o funcionamento da aplicação ali hospeda. Neste caso, o grupo refere-se a um banco de dados Oracle. Podemos citar como exemplos de recursos de banco de dados Oracle: os Discos, Serviços Oracle, Network Device, etc.
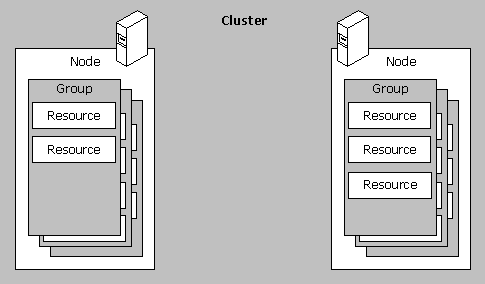 A manutenção da "disponibilidade do serviço" em caso de falha é garantida por meio de um mecanismo denominado Failover. Segundo as documentações da Microsoft, Failover é o processo de migração dos recursos de cluster (Um ou mais grupo de recursos) de um node indisponível para um disponível. Este mecanismo é automaticamente iniciado pelo MSCS quando detectado uma falha física ou lógica do node ativo. Em outras palavras, o processo que leva um grupo de recursos em estado off-line em um determinando node para online em outro. Com isso os recursos do grupo voltam a acessibilidade, fazendo com que a aplicação em questão fique novamente disponível.
A manutenção da "disponibilidade do serviço" em caso de falha é garantida por meio de um mecanismo denominado Failover. Segundo as documentações da Microsoft, Failover é o processo de migração dos recursos de cluster (Um ou mais grupo de recursos) de um node indisponível para um disponível. Este mecanismo é automaticamente iniciado pelo MSCS quando detectado uma falha física ou lógica do node ativo. Em outras palavras, o processo que leva um grupo de recursos em estado off-line em um determinando node para online em outro. Com isso os recursos do grupo voltam a acessibilidade, fazendo com que a aplicação em questão fique novamente disponível. 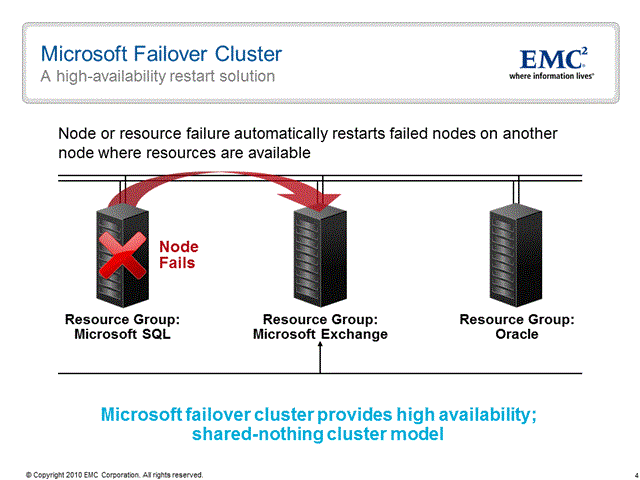
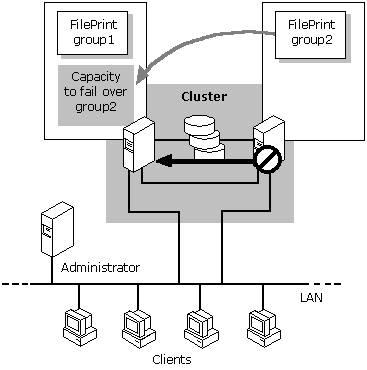
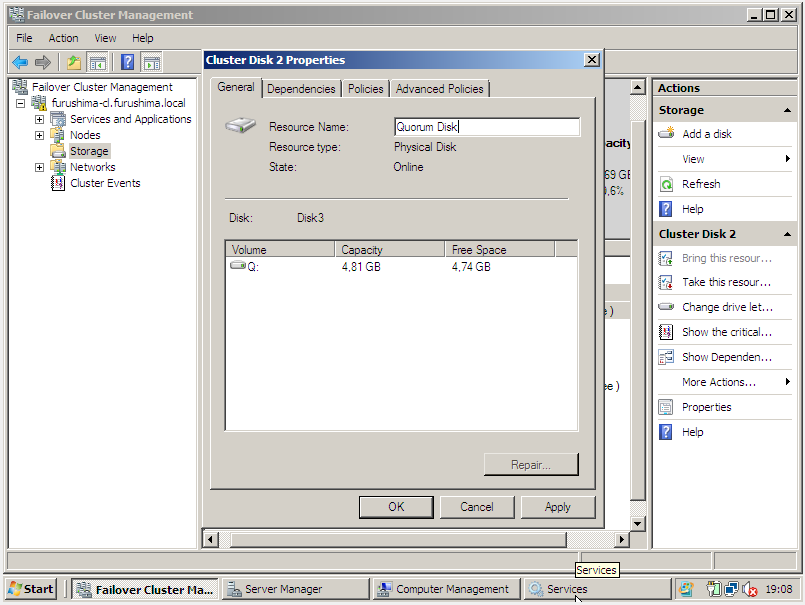
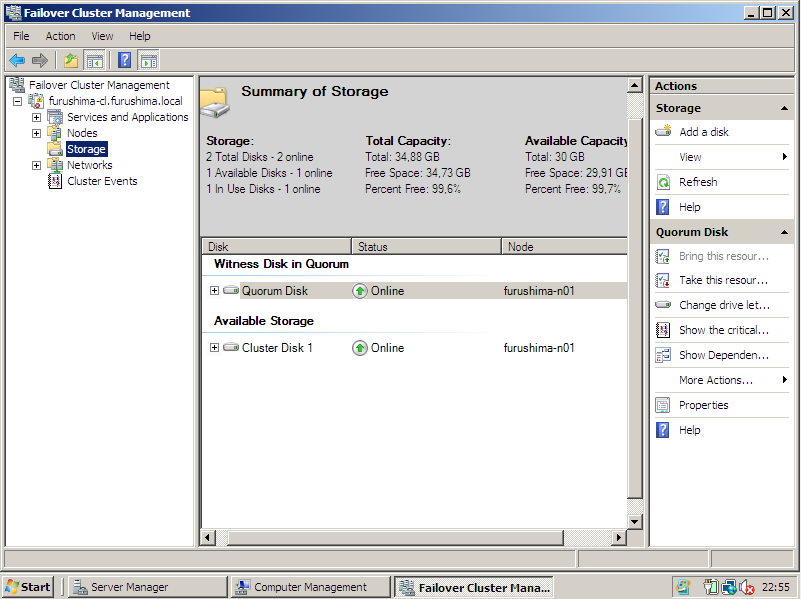
O recurso de quorum é o responsável por gerir e manter os metadados necessários para o funcionamento do cluster, devido sua existência é possível a realização do mecanismo de Failover, esse recurso detém as informações necessárias em forma de logs para recuperação do cluster em caso de falha.
Um disco (device ou volume) representa o quorum disk do cluster, que armazena em forma de arquivo os metadados necessários para o funcionamento do cluster, esse volume está montado (ativo) sempre em um único node do cluster, em caso de falha (lógica ou física), este recurso é flutuado, por meio de Failover como qualquer outro.
Resumindo:
"Cluster Resource" ou "Recurso"
É qualquer componente físico ou lógico disponibilizado para o sistema computacional que é vital para o funcionamento do banco de dados.
Exemplo: Disco, Serviço do Oracle, Network, etc.
Groups ou Grupo
É uma coleção de recursos delimitada de forma logica, onde eles formam uma unidade de failover. Essa coleção de recursos que forma a unidade de failover é responsável pelo funcionamento do todo, no caso o banco de dados Oracle. Ou seja, para garantir a continuidade do serviço (disponibilidade do banco de dados) em caso de falha é necessário que todos os recursos sejam movidos para o node sobrevivente, para ter esse controle de quais recursos mover, o cluster exige a criação do grupo e os recursos pertencentes a ele.
Oracle Fail Safe
Oracle Fail Safe é uma solução que funciona com o Microsoft Windows Clusters, proporcionando high availability para aplicações e para o banco de dados Oracle em standalone (single instance).
Basicamente o Oracle Fail Safe se divede em 3 componetes :
- Oracle Fail Safe Resource Dynamically Linked Libraries (DLLs)
É o binario instalado sobre o disco local de todos os nodes pertencentes ao Microsoft Windows Cluster Server (MSCS)
- Oracle Fail Safe Server
É a camada de clusterização que promove a comunicação entre os nodes do Microsoft Windows Cluster, assegurando um failover em caso de necessidade.
- Oracle Fail Safe Manager
Interface de gerenciamento do cluster, provendo uma tela de integração entre recursos Oracle e Microsoft Windows Cluster Server (MSCS).
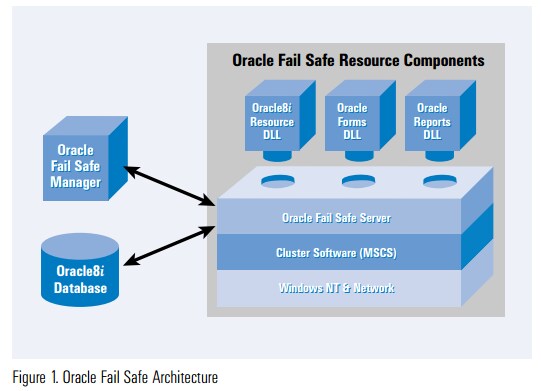 Oracle Database sobre Microsoft Cluster System
Oracle Database sobre Microsoft Cluster System
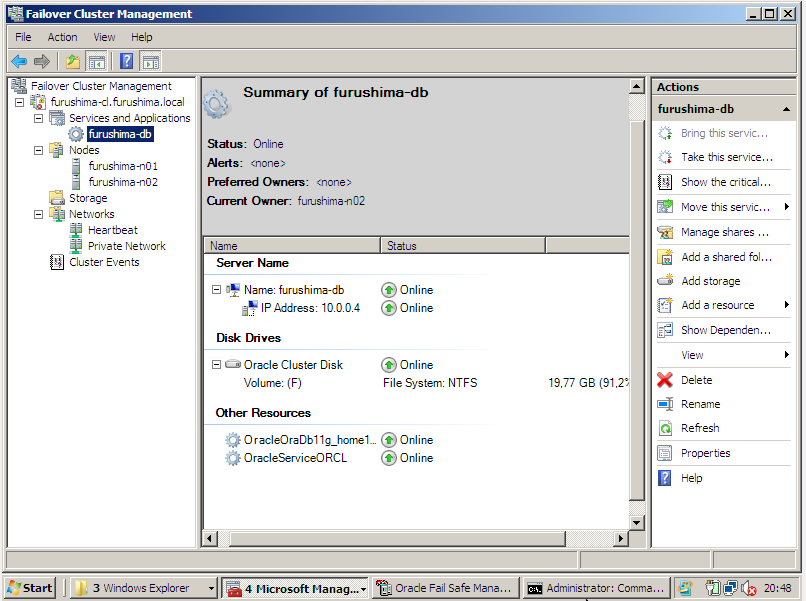
Em um cenário em que o Oracle database esteja em alta disponibilidade no Microsoft Windows Clusters é necessário um grupo onde os recursos pertencentes a ele são:
Todos os discos (Storage) usado pelo Oracle database (exceto disco local onde o binário está instalado)
Serviço de Oracle Database Instance (exemplo: OracleServiceORCL)
Um ou mais virtual adresses, que consiste em IP Virtual Network e Virtual Network Name (Client Access Point).
Serviço Listener (exemplo: OracleOraDb11g_home1TNSListener)
Serviço Oracle Management Agent (Caso estiver usando Enterprise Manager)
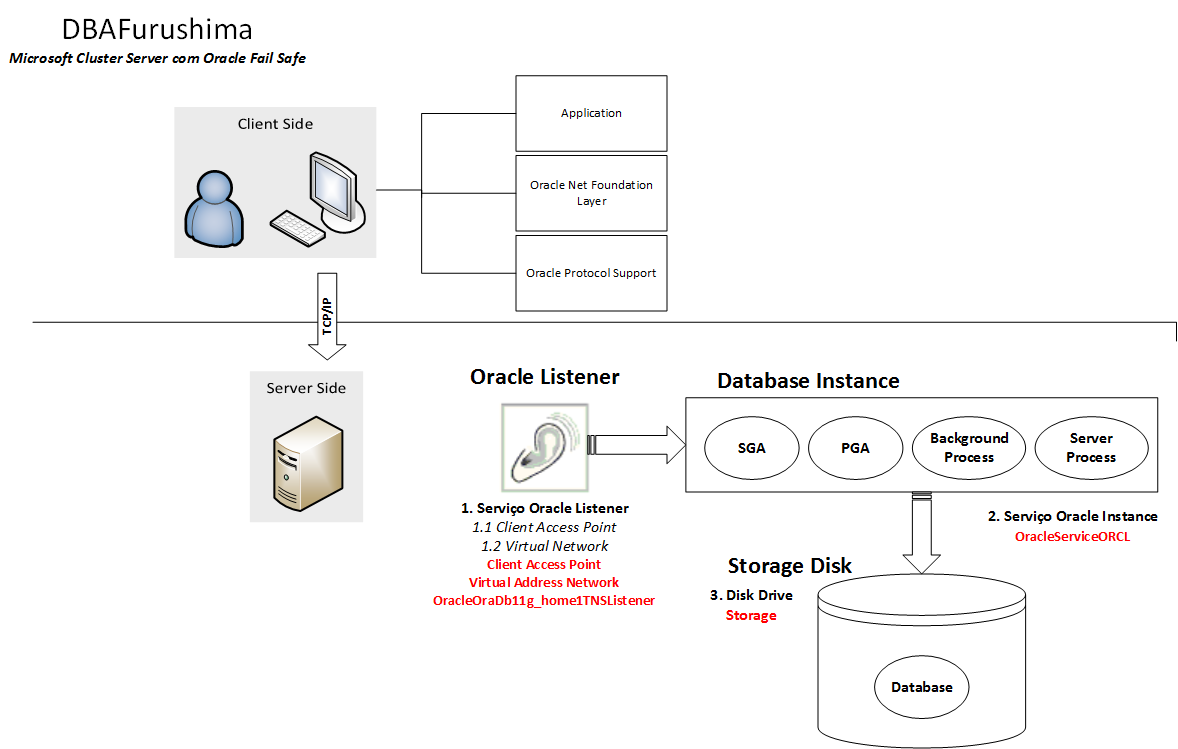
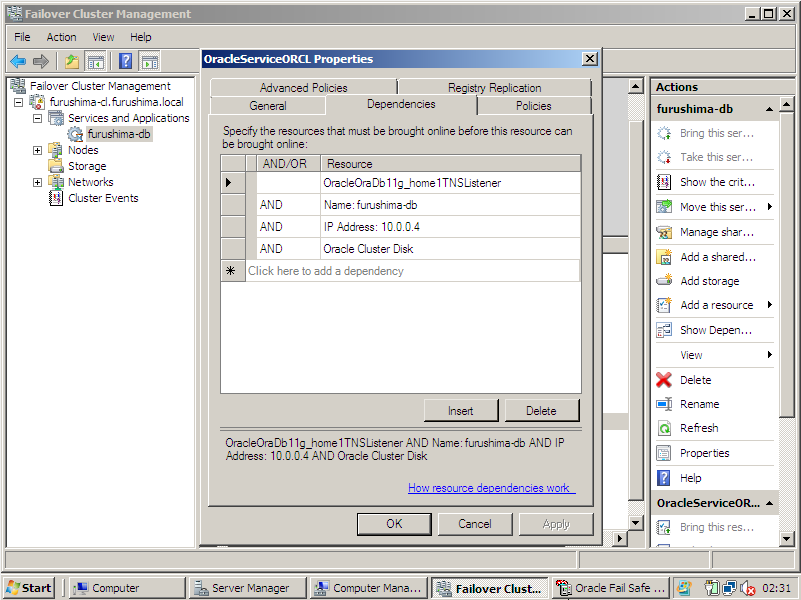
Os recursos pertencentes ao grupo que detém os “Serviços Oracle” necessários para o funcionamento do banco possuem interação uns com os outros e isso provoca uma situação de dependência de recursos, ou seja, para que um recurso possa executar suas atividade é necessário que outros esteja online.
Não é possível abrir um banco de dados Oracle, uma vez que o disco onde os datafiles residem não estão disponíveis. É inviável abrir um banco de dados para uso, sendo que não há serviço listener para os “clients connections” estabelecerem conexões.
Para que um failover seja eficiente, não apresentando falhas ou lentidão, é necessário um bom entendimento de quais recursos devem inicializar primeiro.
| Virtual IP Address Network / Virtual Hostname Address - VIP |
|---|
| É um recurso de cluster que representa um endereço IP e um hostname que tem a capacidade de flutuar entre os nodes do cluster por meio de Failover. |
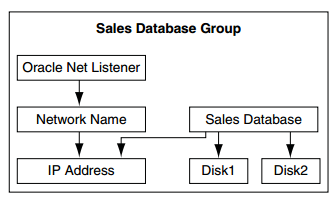
- Database Instance: depende dos discos onde reside o database (arquivo de banco de dados)
- Database Instance: depende de um IP Address para se registrar no listener.
- Oracle Net Listener: depende de um Network Name e um Ip addresss para cumprir seu papel e estabelecer conexões com o servidor de banco de dados oracle.
Antes de qualquer iniciação prática é importante ter a seguinte visão da solução:
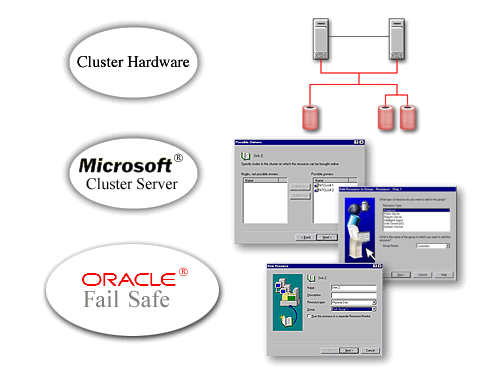
Implementando uma solução Microsoft Windows Cluster com Oracle Fail Safe, com o objetivo de ter um Database em alta disponibilidade.
Abaixo é mostrado a arquitetura de um Oracle Database em High Availability, usando Microsoft Windows Clusters Server (MSCS) e Oracle Fail Safe:

Pré-requisitos para implementação da solução:
- Domain Controller
- DNS
- Infra-estrutura física de rede
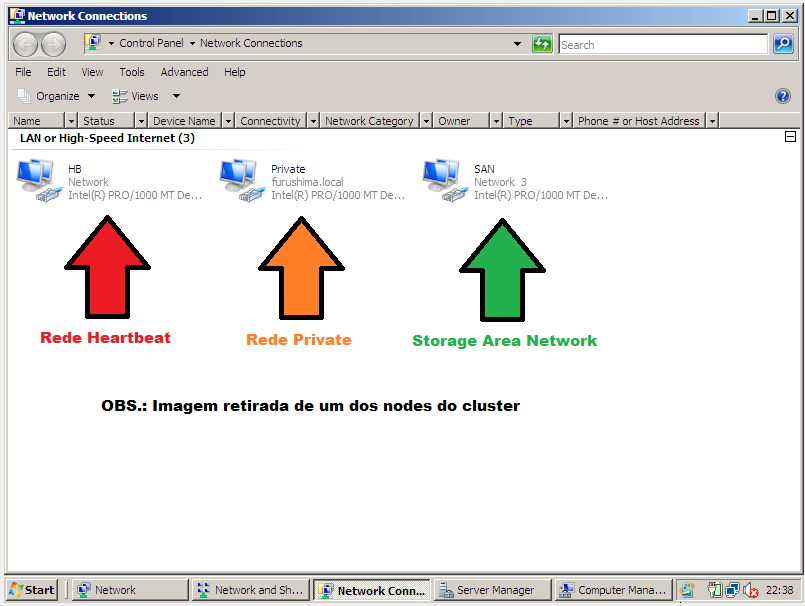
IMPORTANTE: O storage deste cenário, trata-se de um ISCSI, portanto a rede é ethernet, em caso “fiber channel storage”, o connection SAN, não estaria neste print, por não se tratar de rede ethernet.
Passo 1) Construção do Windows cluster
Neste passo as seguintes etapas são executadas:
- Instalação da feature “Failover Clustering”.
- Criação do cluster, usando a feature “Failover Clustering”.
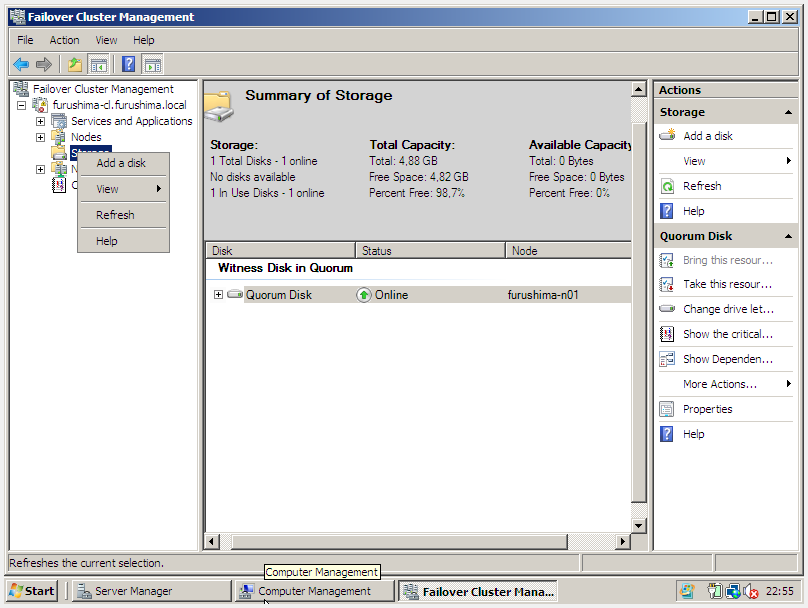
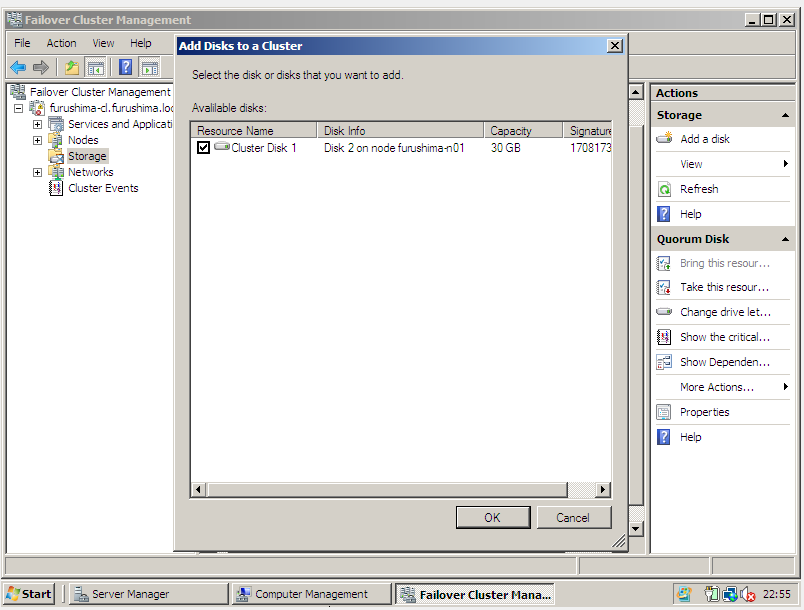
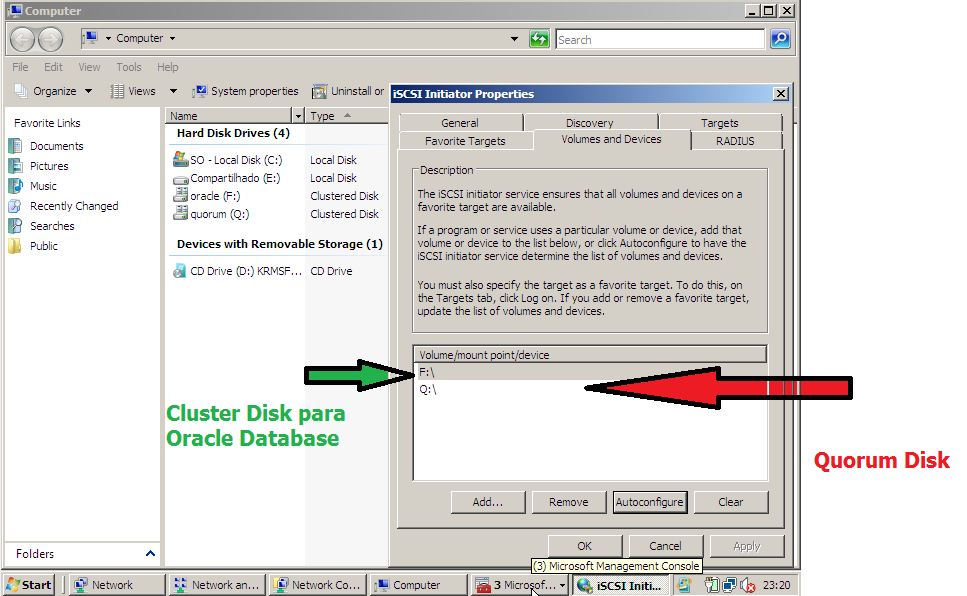
- Criação de um Cluster Disk para Quorum.
- Criação de um Cluster Disk para o Oracle Database.
a) Em todos os nodes, é necessário fazer a instalação da feature “Failover Clustering”, esta fornecerá a interface de criação do cluster.
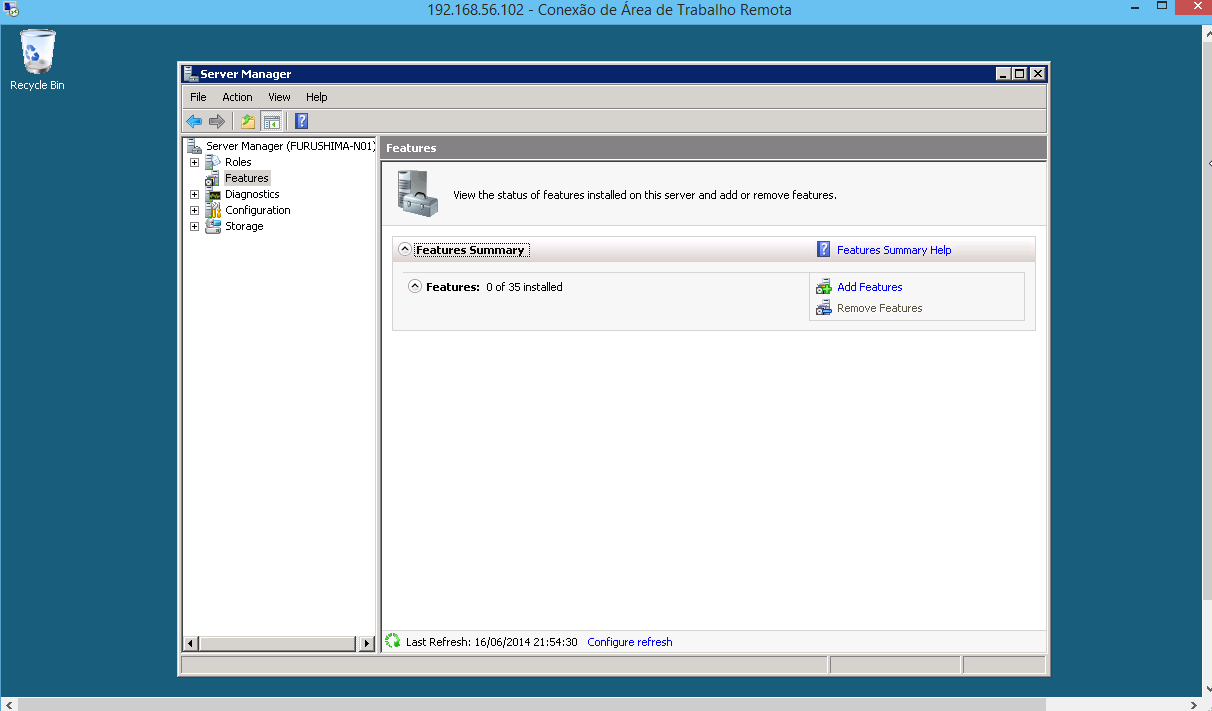

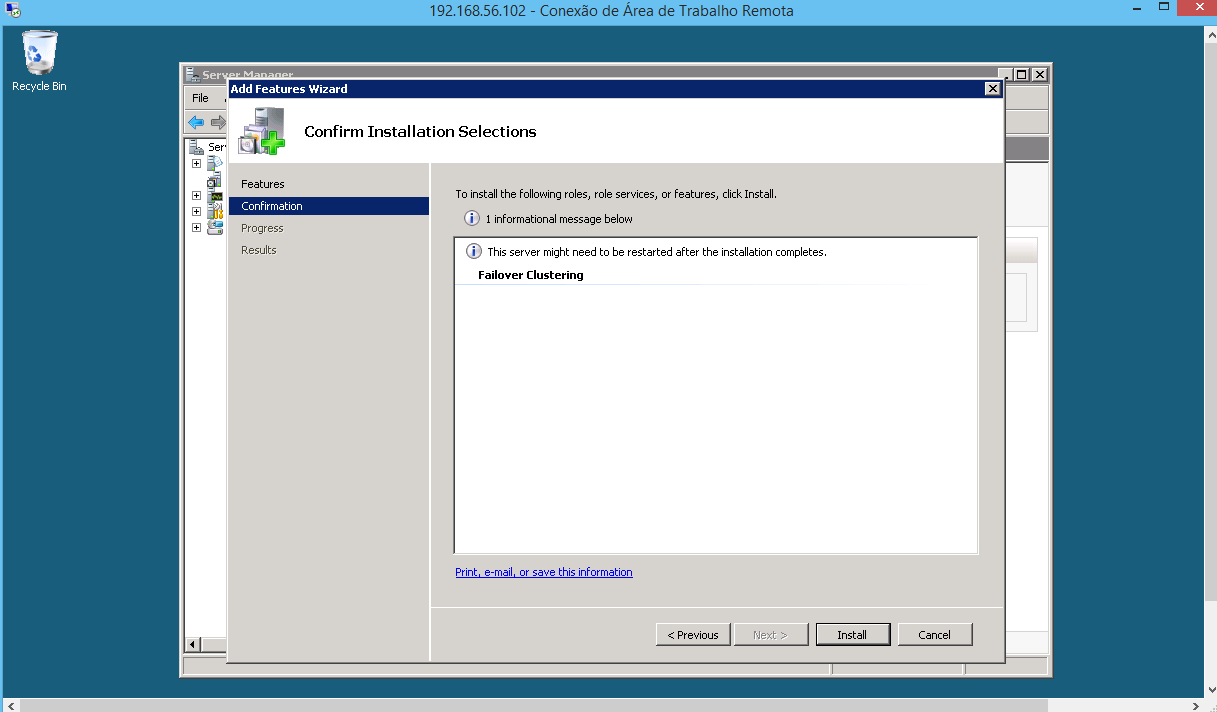


FAZER A CRIAÇÃO DA FEATURE EM TODOS OS NODES DO CLUSTER
b) Após fazer a instalação da feature “Failover Clustering” em todos os node do cluster, é necessário criar o cluster, usando a interface da feature instalada.
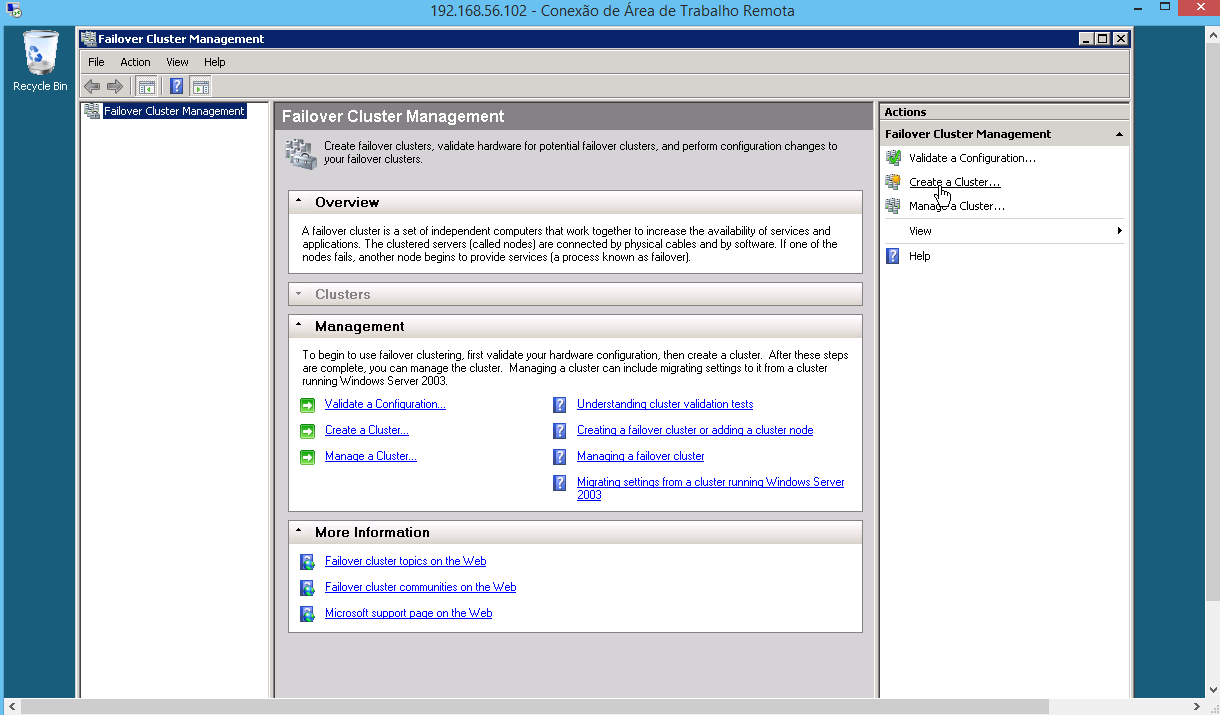


Neste passo iremos selecionar os nodes do cluster. Devemos nos atentar que ambas as máquinas (nodes), devem pertencer ao Domínio, controlado pelo DC.
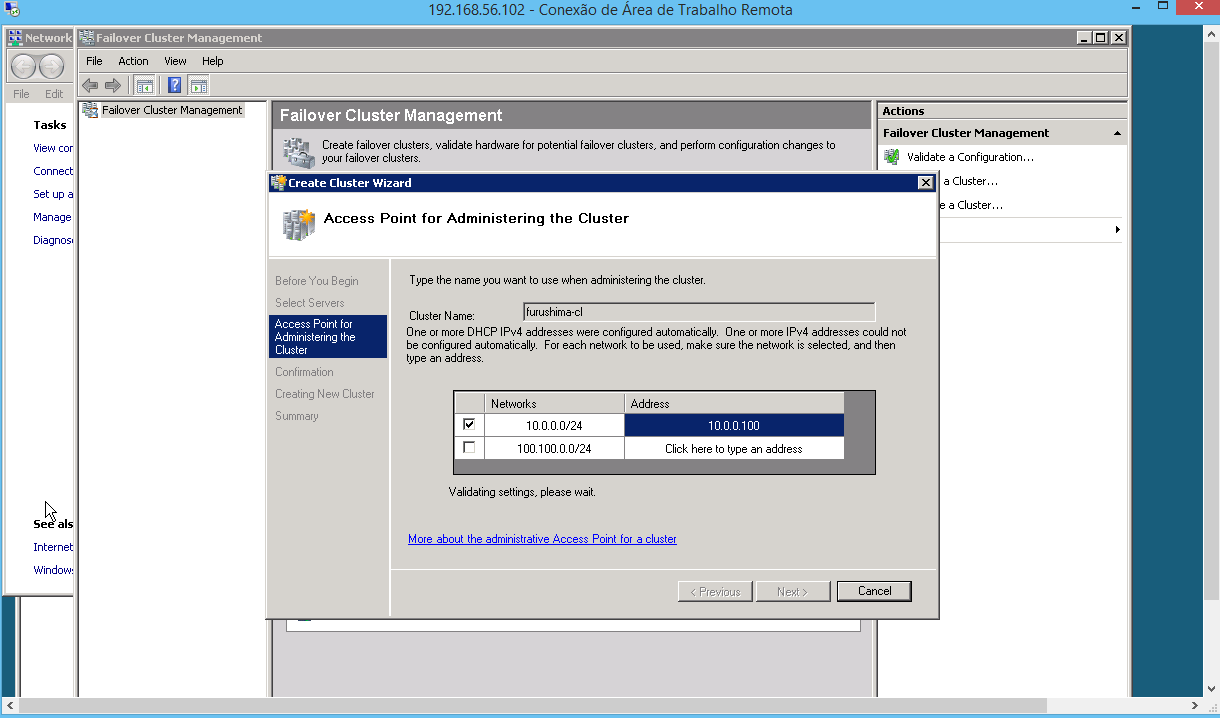
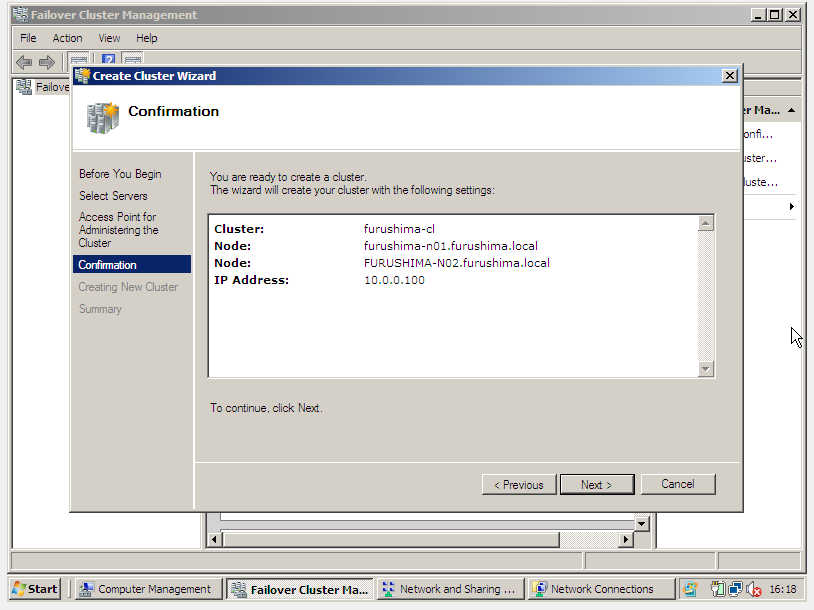
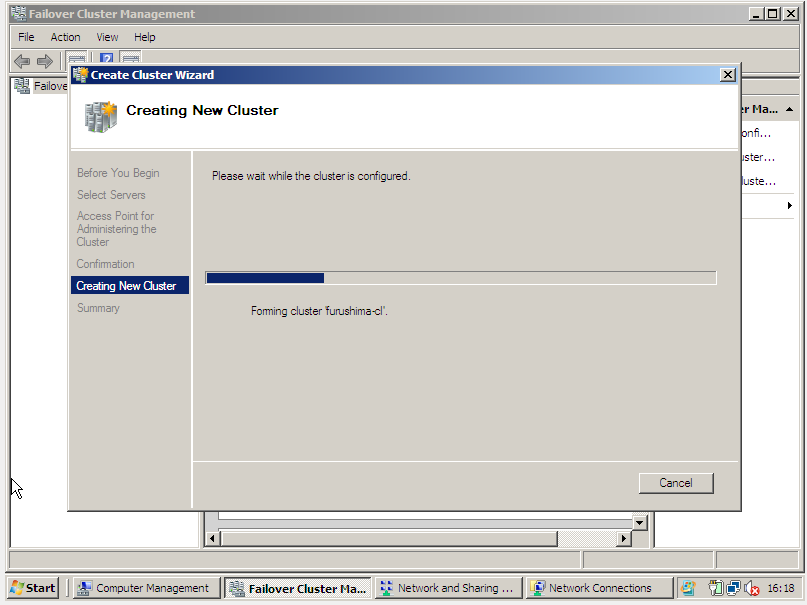

Este warning informa ao Administrador que não existe um shared storage válido. É necessário configurar o Quorum em um step posterior.
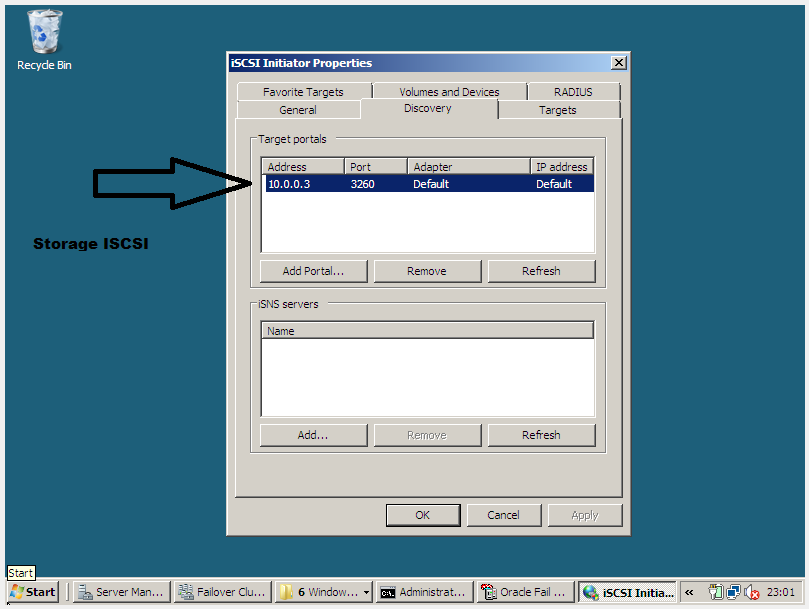
c) Criação do Quorum Disk e do Oracle Database Disk
Para criar o quorum é necessário ter um disco oriundo de storage, onde o mesmo deve estar particionado e formatado em NTFS. Veja:




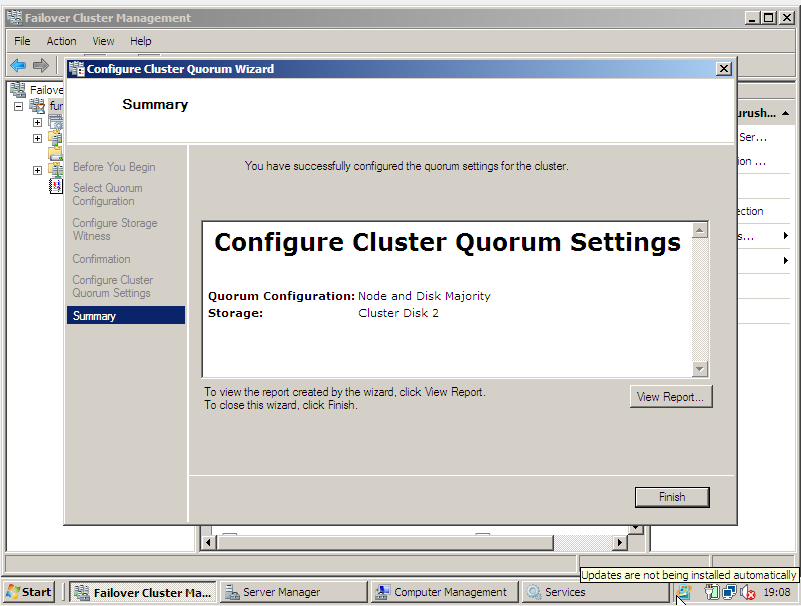
Passo 2) Construção do Oracle Database
Neste passo as seguintes etapas são executadas:
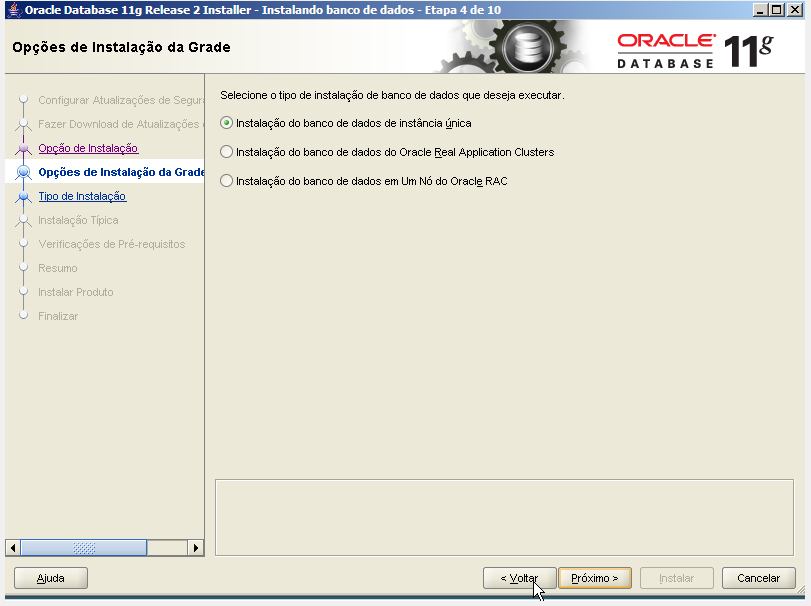
- Instalação do Oracle Database em Standalone.
- Criação da Oracle Database Instance.
- Instalação do Oracle Fail Safe
a) Em ambos os nodes, é necessário fazer a instalação do Oracle Database em Standalone.









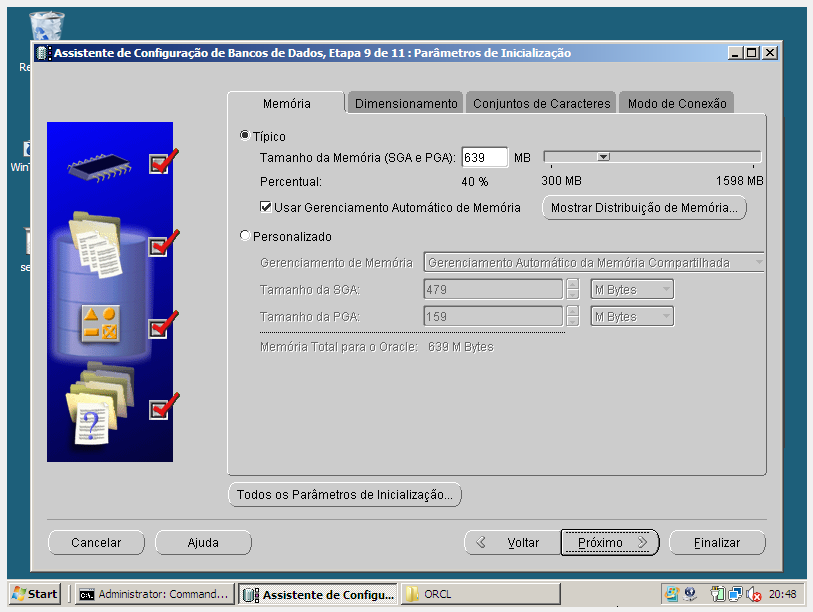
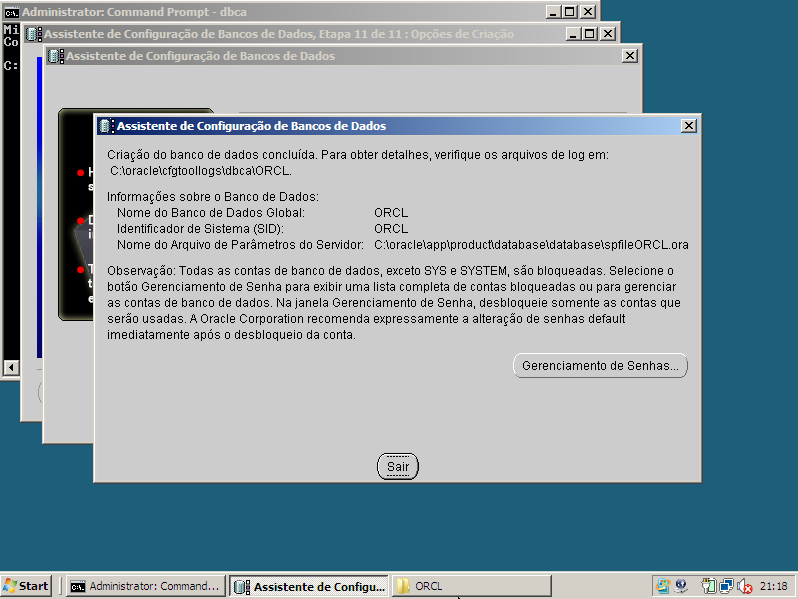
b) No node onde, está localizado o cluster disk para o oracle database crie a Database Instance via dbca.
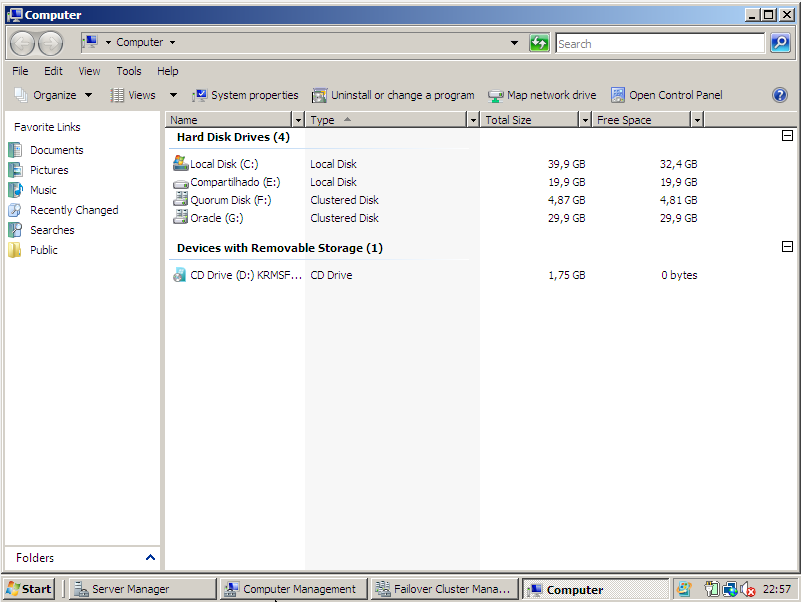


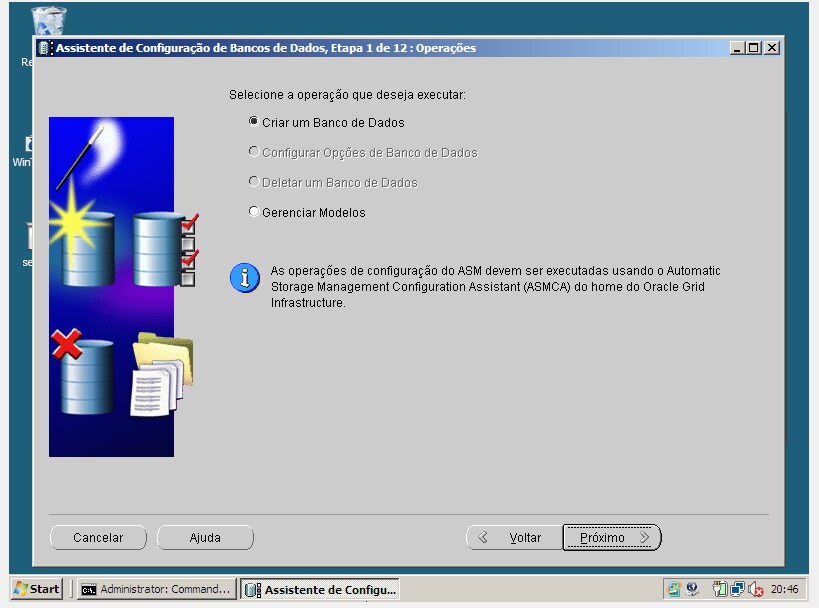

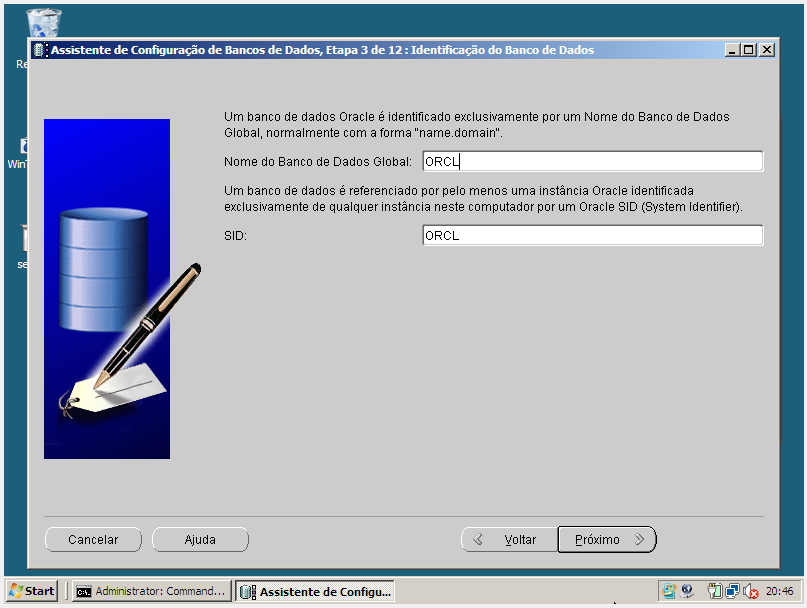
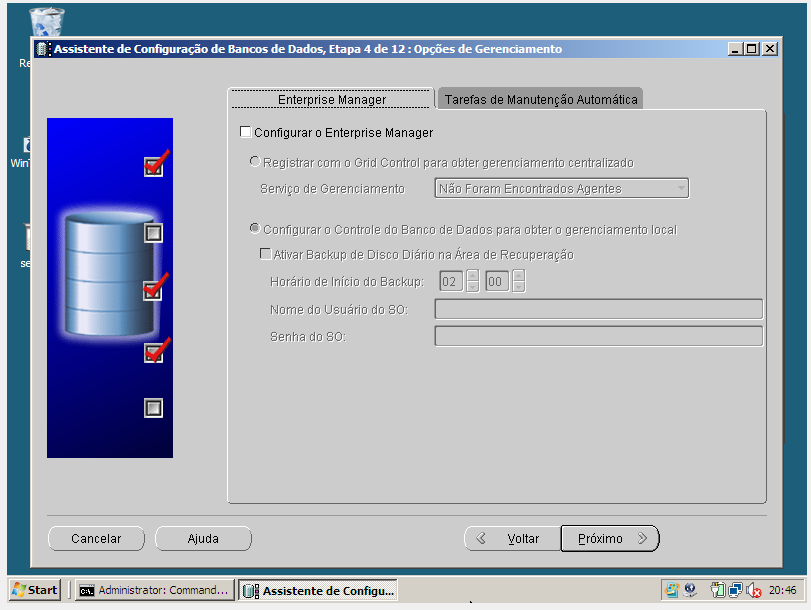
OBS.: Foi excluído todos os componentes, pois este cenário trata-se de um laboratório de teste, em um ambiente produtivo é necessário verificar quais componente sua aplicação usará.


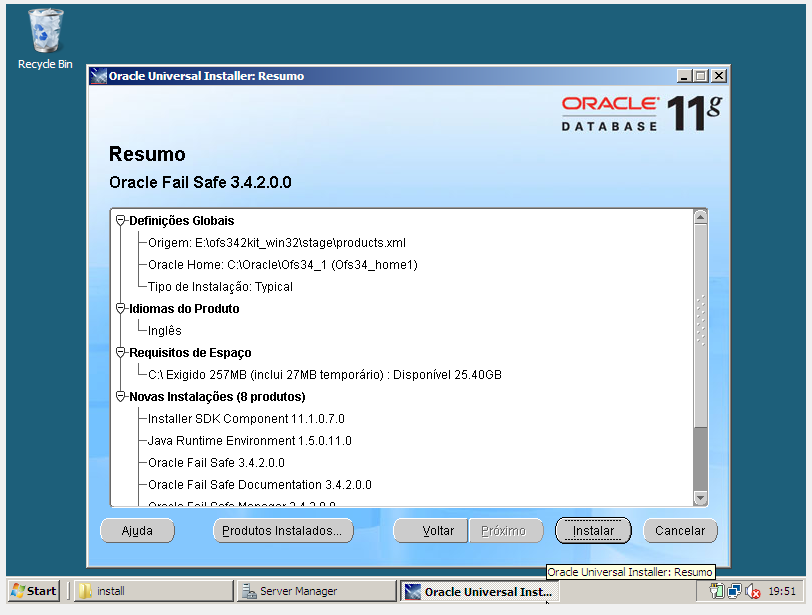
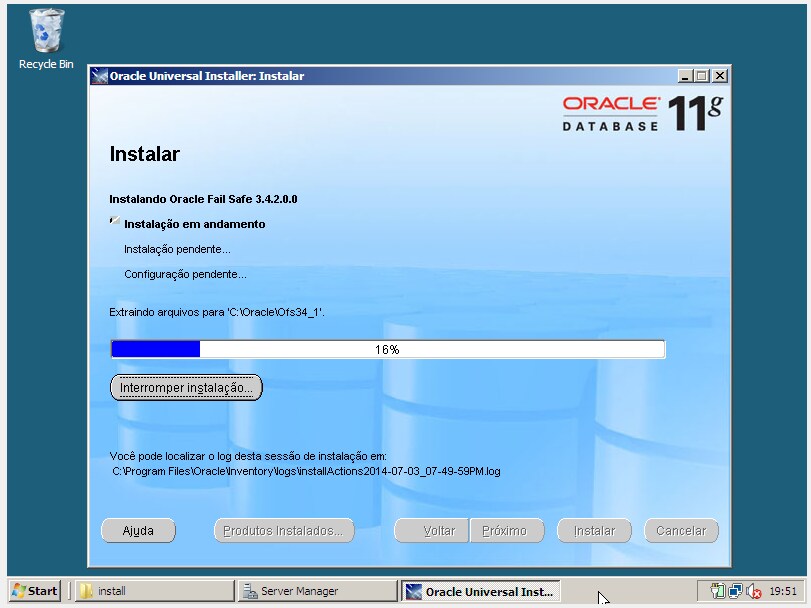
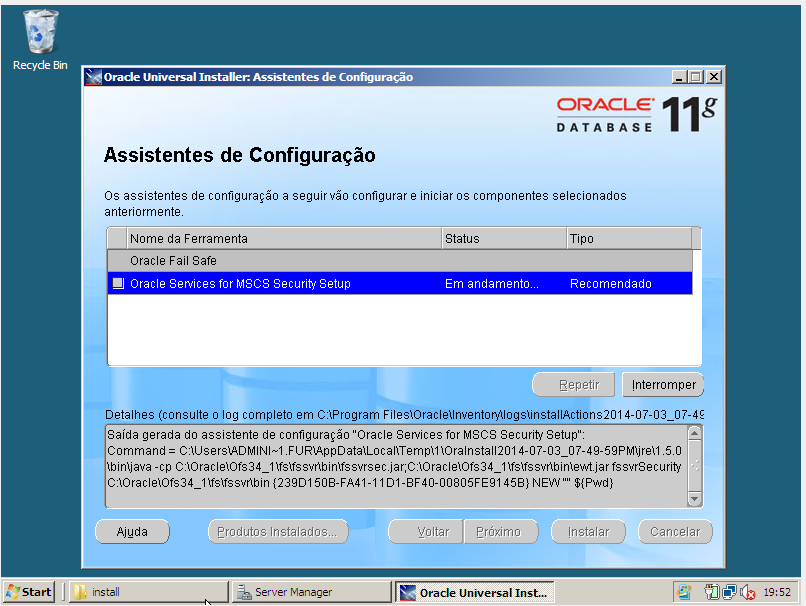
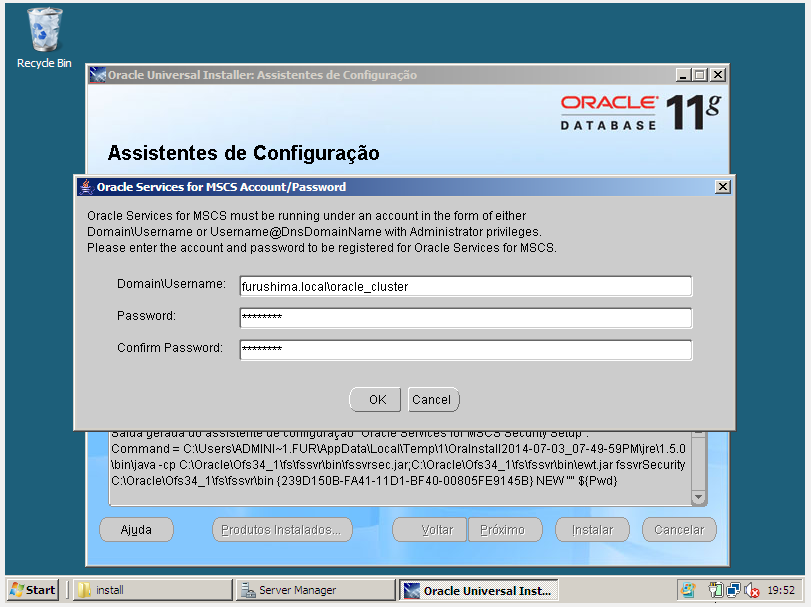
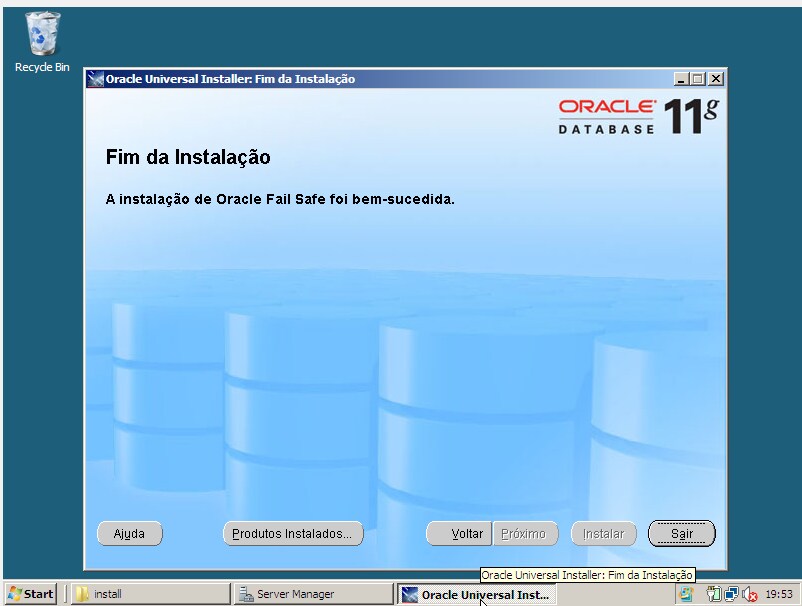
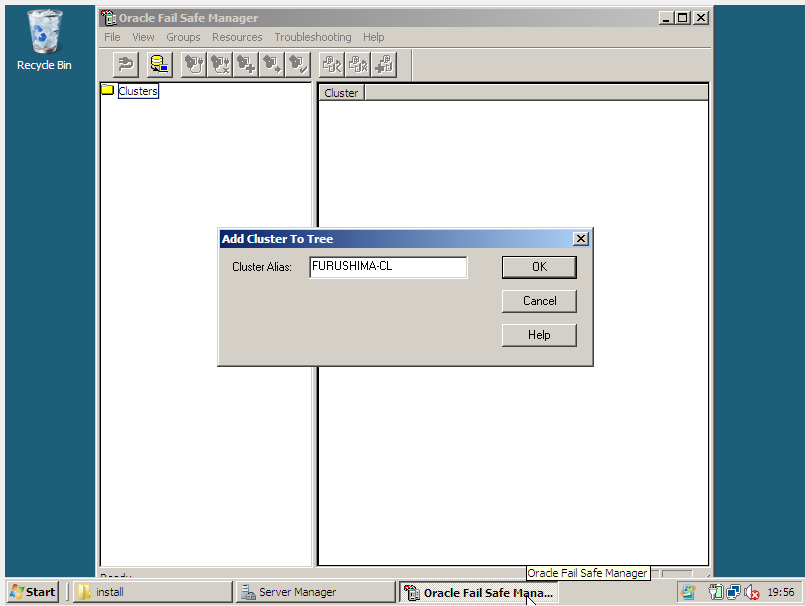


Passo 3) Integração do Oracle Database com Windows Cluster via Oracle Fail Safe
Neste passo as seguintes etapas são executadas:
- Configuração dos serviços Oracle no Windows Cluster
- Verificação dos recursos no Oracle Fail Safe
- Teste de Fail Over
O passo 3 é o momento da integração entre Oracle Database Instance e Windows Cluster, conforme vimos na parte teórica. Denominamos esta integração como Oracle Database em High Availability. Alguns pontos de extrema importância devem ser considerados:
- O parameter file deve ser compartilhado entre os node do cluster.
É possível criar esse cenário de diversas maneiras, optei por seguir uma linha semelhante como é encontrado no RAC (Real Application Cluster), onde no disco local (%ORACLE_HOME%\DATABASE), existe um parameter file do tipo pfile, onde possui somente 1 parâmetro, o SPFILE, este parameter file do tipo spfile está localizado em um local compartilhado, neste caso o cluster disk para o oracle database.

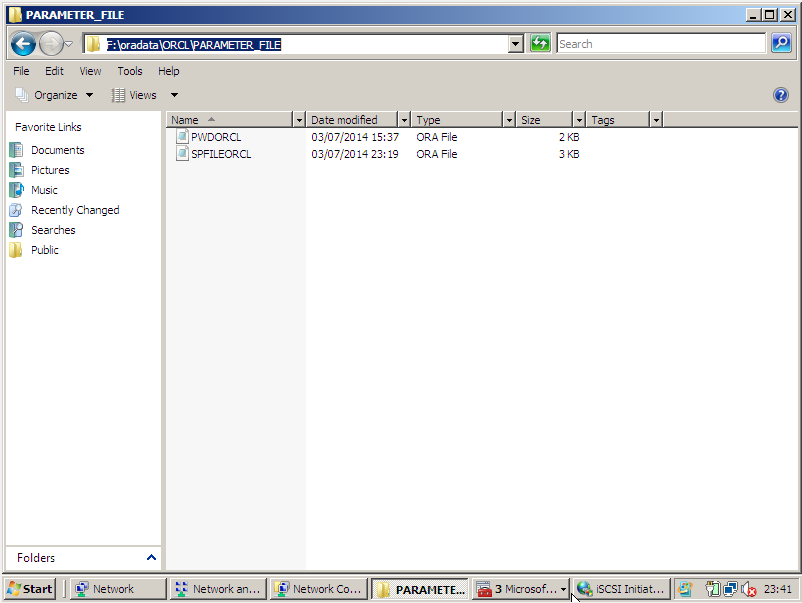

- Serviço de instance e listener deve ser criado no node passivo.
O processo de criação do serviço de instance e listener não é automático no node passivo do cluster, portanto deve ser criado manualmente, como um step de criação da solução como um todo. Usarei o utilitário ORADIM para criação do serviço de instance e para o listener usarei o LSNRCTL.
Para criar o service instance:
ORADIM -NEW -SID ORCL –STARTMODE MANUAL
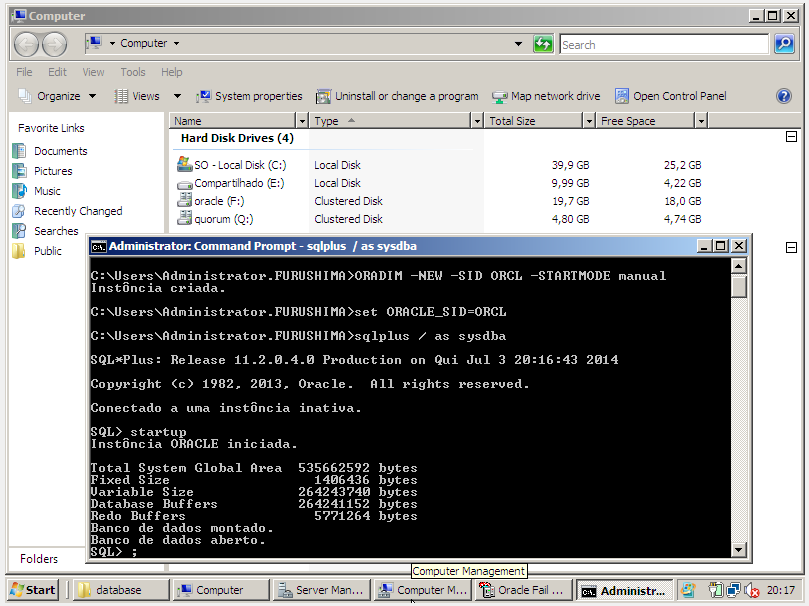
Após criação do Service Instance, faremos startup do banco de dados, para isso é necessário que o cluster disk para o Oracle Database esteja montado neste node passivo, para isso faça o FAILOVER do disco ou execute um reboot no node ativo.
A criação do listener é feita com o comando start via LSNRCTL.
LSNRCTL START
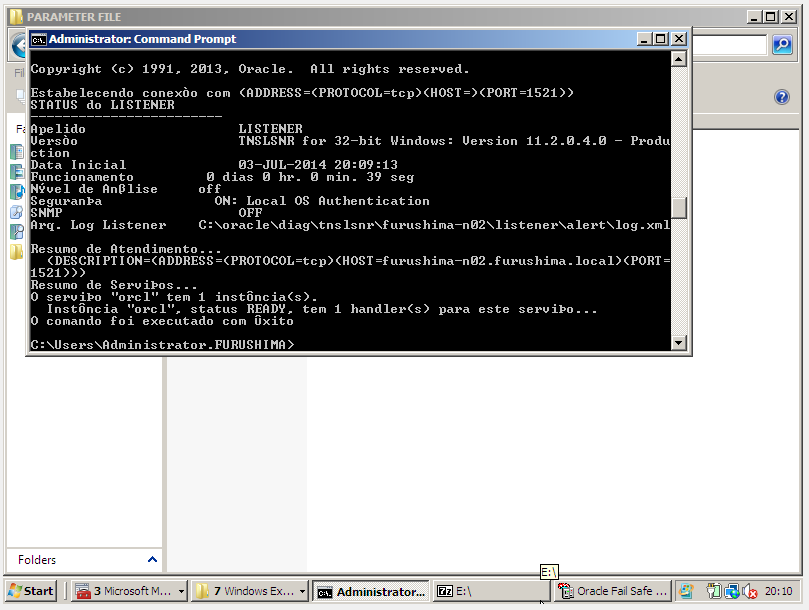
Certifique-se que o parâmetro local_listener de sua instance, seja usando o “DESCRIPTION TNS”, com o IP Virtual Network para o Oracle Database ou hostname Virtual Network para o Oracle. Abordamos estes conceitos na parte teórica.

Após ter essas 2 condições completadas, devemos criar o "grupo de recursos" para o Oracle.



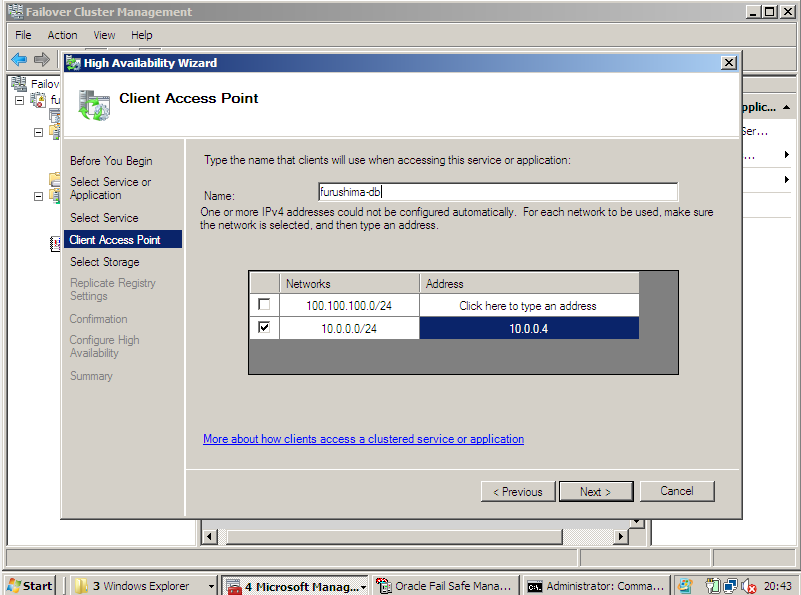
Foi denominado como "furushima-db", o "grupo de recursos" para o Oracle, que possui um IP Virtual Network, definido em "10.0.0.4".


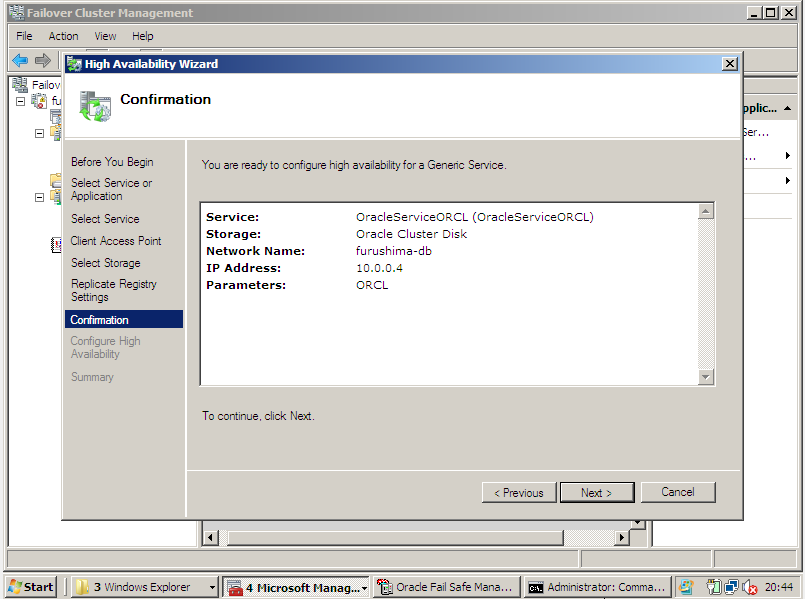

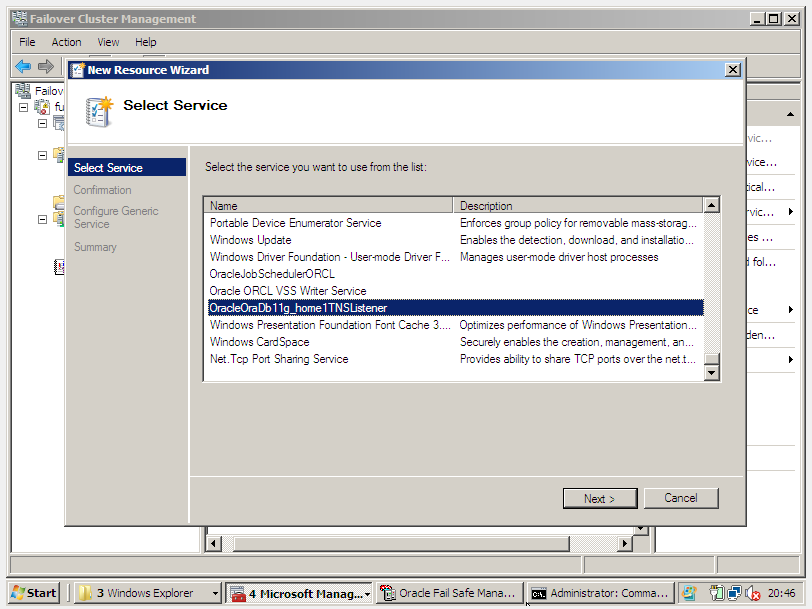


Para que o banco de dados esteja disponível para uso, é necessário:
- Instance em estado OPEN
- Cluster disk com os database files para startup da instance
- IP Virtual Network para registro do database no LISTENER
- Serviço LISTENER em estado STARTED
Para isso, é imprescindível configurar as dependências entre recursos para o serviço de instance OracleServiceORCL. (Veja acima)
Referências Bibliográficas:
http://docs.oracle.com/cd/E10736_01/doc/server.341/e11080/intro.htm
http://docs.oracle.com/html/A96684_01/intro.htm
http://www.oracle.com/au/products/database/unix-clusters-099271.html
http://www.ibm.com/developerworks/data/library/techarticle/dm-0901matthae/
http://blogs.msdn.com/b/clustering/archive/2009/03/02/9453288.aspx
https://www.microsoft.com/resources/documentation/windowsnt/4/server/proddocs/en-us/clustsvr/mscsadm1.mspx?mfr=true
http://docs.oracle.com/cd/E10736_01/doc/server.341/e11080/concepts.htm
http://pic.dhe.ibm.com/infocenter/tsminfo/v6r2/index.jsp?topic=%2Fcom.ibm.itsm.srv.doc%2Fc_clusters_srvs_mscs_virtual_win.html
http://docs.oracle.com/cd/E10736_01/doc/server.341/e11080/concepts.htm
http://otndnld.oracle.co.jp/tech/windows/failsafe/htdocs/failsafe331qt/int2_01.htm
http://powerwindows.wordpress.com/2010/10/25/windows-geoclusters-stretch-clusters-and-recoverpointce-failover/
Carlos H. Y. Furushima é um especialista em banco de dados relacional, trabalhando como consultor de TI, atuando principalmente como o Oracle Database Administrator (DBA Oracle). Tem uma vasta experiência e conhecimento em “Performance, diagnosticand tuning", "High Availability", "Backup & Recovery" e "Exadata". Ele também está entusiasmado com sistema operacional Linux/Unix, onde contribui com o desenvolvimento do código do kernel Linux em parceria com a comunidade "GNU Linux", com criação e revisão de novas funcionalidades, melhorias e correções de bugs. Recentemente, Furushima divide seu tempo com consultoria especializada em banco de dados Oracle e estudos sobre "Oracle Internals", com o objetivo de descobrir e entender os benefícios do bancos de dados Oracle em plataforma Linux/Unix.
Este artigo foi revisto pela equipe de produtos Oracle e está em conformidade com as normas e práticas para o uso de produtos Oracle.