
An Overview of Batch Processing in Java EE 7.0
by Mahesh Kannan
Published June 2013
Examine the new batch processing capability provided by JSR 352 for Java EE 7.
Batch processing is used in many industries for tasks ranging from payroll processing; statement generation; end-of-day jobs such as interest calculation and ETL (extract, load, and transform) in a data warehouse; and many more. Typically, batch processing is bulk-oriented, non-interactive, and long running—and might be data- or computation-intensive. Batch jobs can be run on schedule or initiated on demand. Also, since batch jobs are typically long-running jobs, check-pointing and restarting are common features found in batch jobs.
JSR 352 (Batch Processing for Java Platform), part of the recently introduced Java EE 7 platform, defines the programming model for batch applications plus a runtime to run and manage batch jobs. This article covers some of the key concepts including feature highlights, an overview of selected APIs, the structure of Job Specification Language, and a sample batch application. The article also describes how you can run batch applications using GlassFish Server Open Source Edition 4.0.
Batch Processing Architecture
This section and Figure 1 describe the basic components of the batch processing architecture.
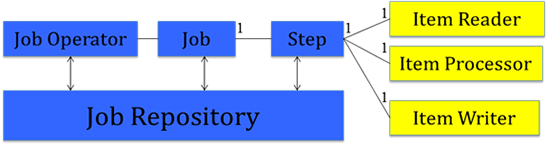
Figure 1
- A job encapsulates the entire batch process. A job contains one or more steps. A job is put together using a Job Specification Language (JSL) that specifies the sequence in which the steps must be executed. In JSR 352, JSL is specified in an XML file called the job XML file. In short, a job (with JSR 352) is basically a container for steps.
- A step is a domain object that encapsulates an independent, sequential phase of the job. A step contains all the necessary logic and data to perform the actual processing. The batch specification deliberately leaves the definition of a step vague because the content of a step is purely application-specific and can be as complex or simple as the developer desires. There are two kinds of steps: chunk and batchlet.
- A chunk-style step contains exactly one
ItemReader, oneItemProcessor, and oneItemWriter. In this pattern,ItemReaderreads one item at a time,ItemProcessorprocesses the item based upon the business logic (such as "calculate account balance"), and hands it to the batch runtime for aggregation. Once the "chunk-size" number of items are read and processed, they are given to anItemWriter, which writes the data (for example, to a database table or a flat file). The transaction is then committed. - JSR 352 also defines a roll-your-own kind of a step called a batchlet. A batchlet is free to use anything to accomplish the step, such as sending an e-mail.
- A chunk-style step contains exactly one
JobOperatorprovides an interface to manage all aspects of job processing, including operational commands, such as start, restart, and stop, as well as job repository commands, such as retrieval of job and step executions. See section 10.4 of the JSR 352 specification for more details aboutJobOperator.JobRepositoryholds information about jobs currently running and jobs that ran in the past.JobOperatorprovides APIs to access this repository. AJobRepositorycould be implemented using, say, a database or a file system.
Developing a Simple Payroll Processing Application
This article demonstrates some of the key features of JSR 352 using a simple payroll processing application. The application has been intentionally kept quite simple in order to focus on the key concepts of JSR 352.
The SimplePayrollJob batch job involves reading input data for payroll processing from a comma-separated values (CSV) file. Each line in the file contains an employee ID and the base salary (per month) for one employee. The batch job then calculates the tax to be withheld, the bonus, and the net salary. The job finally needs to write out the processed payroll records into a database table.
We use a CSV file in this example just to demonstrate that JSR 352 allows batch applications to read and write from any arbitrary source.
Job Specification Language for the Payroll Processing Application
We discussed that a step is a domain object that encapsulates an independent, sequential phase of the job, and a job is basically a container for one or more steps.
In JSR 352, a JSL basically specifies the order in which steps must be executed to accomplish the job. The JSL is powerful enough to allow conditional execution of steps, and it also allows each step to have its own properties, listeners, and so on.
A batch application can have as many JSLs as it wants, thus allowing it to start as many batch jobs as required. For example, an application can have two JSLs, one for payroll processing and another for report generation. Each JSL must be named uniquely and must be placed in the META-INF/batch-jobs directory. Subdirectories under META-INF/batch-jobs are ignored.
Our JSL for payroll processing is placed in a file called SimplePayrollJob.xml and looks like Listing 1:
<job id="SimplePayrollJob" xmlns=http://xmlns.jcp.org/xml/ns/javaee version="1.0">
<step id="process">
<chunk item-count="2">
<reader ref="simpleItemReader/>
<processor ref="simpleItemProcessor/>
<writer ref="simpleItemWriter/>
</chunk>
</step>
</job>Listing 1
Our SimplePayrollJob batch job has just one step (called "process"). It is a chunk-style step and has (as required for a chunk-style step), an ItemReader, an ItemProcessor, and an ItemWriter. The implementations for ItemReader, ItemProcessor, and ItemWriter for this step are specified using the ref attribute in the <reader>, <processor>, and <writer> elements.
When the job is submitted (we will see later how to submit batch jobs), the batch runtime starts with the first step in the JSL and walks its way through until the entire job is completed or one of the steps fails. The JSL is powerful enough to allow both conditional steps and parallel execution of steps, but we will not cover those details in this article.
The item-count attribute, which is defined as 2 in Listing 1, defines the chunk size of the chunk.
Here is a high-level overview of how chunk-style steps are executed. Please see section 11.6 ("Regular Chunk Processing") of the JSR 352 specification for more details.
- Start a transaction.
- Invoke the
ItemReaderand pass the item read by theItemReaderto theItemProcessor.ItemProcessorprocesses the item and returns the processed item to the batch runtime. - The batch runtime repeats Step 2
item-counttimes and maintains a list of processed items. - The batch runtime invokes the
ItemWriterthat writesitem-countnumber of processed items. - If exceptions are thrown from
ItemReader,ItemProcessor, orItemWriter, the transaction fails and the step is marked as "FAILED." Please refer to Section 5.2.1.2.1 ("Skipping Exceptions") in the JSR 352 specification. - If there are no exceptions, the batch runtime obtains checkpoint data from
ItemReaderandItemWriter(see section 2.5 in the JSR 352 specification for more details). The batch runtime commits the transaction. - Steps 1 through 6 are repeated if the
ItemReaderhas more data to read.
This means that in our example, the batch runtime will read and process two records and the ItemWriter will write out two records per transaction.
Writing the ItemReader, ItemProcessor, and ItemWriter
Writing the ItemReader
Our payroll processing batch JSL defines a single chunk style step and specifies that the step uses an ItemReader named simpleItemReader. Our application contains an implementation of ItemReader to read input CSV data. Listing 2 shows a snippet of our ItemReader:
@Named
public class SimpleItemReader
extends AbstractItemReader {
@Inject
private JobContext jobContext;
...
}Listing 2
Note that the class is annotated with the @Named annotation. Because the @Named annotation uses the default value, the Contexts and Dependency Injection (CDI) name for this bean is simpleItemReader. The JSL specifies the CDI name of the ItemReader in the <reader> element. This allows the batch runtime to instantiate (through CDI) our ItemReader when the step is executed.
Our ItemReader also injects a JobContext. JobContext allows the batch artifact (ItemReader, in this case) to read values that were passed during job submission.
Our payroll SimpleItemReader overrides the open() method to open the input from which payroll input data is read. As we shall see later, the parameter prevCheckpointInfo will not be null if the job is being restarted.
In our example, the open() method, which is shown in Listing 3, opens the payroll input file (which has been packaged along with the application).
public void open(Serializable prevCheckpointInfo) throws Exception {
JobOperator jobOperator = BatchRuntime.getJobOperator();
Properties jobParameters = jobOperator.getParameters(jobContext.getExecutionId());
String resourceName = (String) jobParameters.get("payrollInputDataFileName");
inputStream = new FileInputStream(resourceName);
br = new BufferedReader(new InputStreamReader(inputStream));
if (prevCheckpointInfo != null)
recordNumber = (Integer) prevCheckpointInfo;
for (int i=1; i<recordNumber; i++) { //Skip upto recordNumber
br.readLine();
}
System.out.println("[SimpleItemReader] Opened Payroll file for reading from record number: " + recordNumber);
}Listing 3
The readItem() method basically reads one line of data from the input file and determines whether the line contains two integers (one for employee ID and one for base salary). If there are two integers, it creates and returns a new instance of PayrollInputRecord and returns to the batch runtime (which is then passed to ItemWriter).
public Object readItem() throws Exception {
Object record = null;
if (line != null) {
String[] fields = line.split("[, \t\r\n]+");
PayrollInputRecord payrollInputRecord = new PayrollInputRecord();
payrollInputRecord.setId(Integer.parseInt(fields[0]));
payrollInputRecord.setBaseSalary(Integer.parseInt(fields[1]));
record = payrollInputRecord;
//Now that we could successfully read, Increment the record number
recordNumber++;
}
return record;
}Listing 4
The method checkpointInfo() is called by the batch runtime at the end of every successful chunk transaction. This allows the Reader to check point the last successful read position.
In our example, the checkpointInfo() returns the recordNumber indicating the number of records that have been read successfully, as shown in Listing 5.
@Override
public Serializable checkpointInfo() throws Exception {
return recordNumber;
}Listing 5
Writing the ItemProcessor
Our SimpleItemProcessor follows a pattern similar to the pattern for SimpleItemReader.
The processItem() method receives (from the batch runtime) the PayrollInputRecord. It then calculates the tax and net and returns a PayrollRecord as output. Notice in Listing 6 that the type of object returned by an ItemProcessor can be very different from the type of object it received from ItemReader.
@Named
public class SimpleItemProcessor
implements ItemProcessor {
@Inject
private JobContext jobContext;
public Object processItem(Object obj)
throws Exception {
PayrollInputRecord inputRecord =
(PayrollInputRecord) obj;
PayrollRecord payrollRecord =
new PayrollRecord();
int base = inputRecord.getBaseSalary();
float tax = base * 27 / 100.0f;
float bonus = base * 15 / 100.0f;
payrollRecord.setEmpID(inputRecord.getId());
payrollRecord.setBase(base);
payrollRecord.setTax(tax);
payrollRecord.setBonus(bonus);
payrollRecord.setNet(base + bonus - tax);
return payrollRecord;
}
}Listing 6
Writing the ItemWriter
By now, SimpleItemWriter must be following predictable lines for you.
The only difference is that it injects an EntityManager so that it can persist the PayrollRecord instances (which are JPA entities) into a database, as shown in Listing 7.
@Named
public class SimpleItemWriter
extends AbstractItemWriter {
@PersistenceContext
EntityManager em;
public void writeItems(List list) throws Exception {
for (Object obj : list) {
System.out.println("PayrollRecord: " + obj);
em.persist(obj);
}
}
}Listing 7
The writeItems() method persists all the PayrollRecord instances into a database table using JPA. There will be at most item-count entries (the chunk size) in the list.
Now that we have our JSL, ItemReader, ItemProcessor, and ItemWriter ready, let's see how a batch job can be submitted.
Starting a Batch Job from a Servlet
Note that the mere presence of a job XML file or other batch artifacts (such as ItemReader) doesn't mean that a batch job is automatically started when the application is deployed. A batch job must be initiated explicitly, say, from a servlet or from an Enterprise JavaBeans (EJB) timer or an EJB business method.
In our payroll application, we use a servlet (named PayrollJobSubmitterServlet) to submit a batch job. The servlet displays an HTML page that presents to the user a form containing two buttons. When the first button, labeled Calculate Payroll, is clicked, the servlet invokes the startNewBatchJob method, shown in Listing 8, which starts a new batch job.
private long startNewBatchJob()
throws Exception {
JobOperator jobOperator = BatchRuntime.getJobOperator();
Properties props = new Properties();
props.setProperty("payrollInputDataFileName", payrollInputDataFileName);
return jobOperator.start(JOB_NAME, props);
}Listing 8
The first step is to obtain an instance of JobOperator. This can be done by calling the following:
JobOperator jobOperator = BatchRuntime.getJobOperator();
The servlet then creates a Properties object and stores the input file name in it. Finally, a new batch job is started by calling the following:
jobOperator.start(jobName, properties)
The jobname is nothing but the job JSL XML file name (minus the .xml extension). The properties parameter serves to pass any input data to the job. The Properties object (containing the name of the payroll input file) is made available to other batch artifacts (such as ItemReader, ItemProcessor, and so on) through the JobContext interface.
The batch runtime assigns a unique ID, called the execution ID, to identify each execution of a job whether it is a freshly submitted job or a restarted job. Many of the JobOperator methods take the execution ID as parameter. Using the execution ID, a program can obtain the current (and past) execution status and other statistics about the job. The JobOperator.start() method returns the execution ID of the job that was started.
Retrieving Details About Batch Jobs
When a batch job is submitted, the batch runtime creates an instance of JobExecution to track it. JobExecution has methods to obtain various details such as the job start time, job completion time, job exit status, and so on. To obtain the JobExecution for an execution ID, you can use the JobOperator.getJobExecution(executionId) method. Listing 9 shows the definition of JobExecution:
package javax.batch.runtime;
public interface JobExecution {
long getExecutionId();
java.lang.String getJobName();
javax.batch.runtime.BatchStatus getBatchStatus();
java.util.Date getStartTime();
java.util.Date getEndTime();
java.lang.String getExitStatus();
java.util.Date getCreateTime();
java.util.Date getLastUpdatedTime();
java.util.Properties getJobParameters();
}Listing 9
Packaging the Application
Now that we have our JSL, ItemReader, ItemProcessor, ItemWriter, and our servlet ready, it is time to package them and get ready to deploy.
You can deploy your batch application as any of the supported Java EE archives (for example, .war, .jar, or .ear). You can bundle your batch artifact classes along with other Java EE classes (such EJB beans and servlets).
The only special requirement is that you need to place your job JSLs under the META-INF/batch-jobs directory for .jar files. For .war archive types, place your job JSLs under the WEB-INF/classes/META-INF/batch-jobs directory.
Deploying and Running the Payroll Sample Application in GlassFish 4.0
Let's deploy the payroll application that we have developed into the GlassFish 4.0 application server. GlassFish 4.0 is the reference implementation (RI) for the Java EE 7.0 specification and contains the RI for JSR 352 as well. You can find more information about GlassFish 4.0 at http://glassfish.org and about the Java Batch 1.0 RI at https://javaee.github.io/.
Installing and Starting GlassFish 4.0
You can download GlassFish 4.0 from https://glassfish.java.net/download.html and then install it. Start GlassFish 4.0 by opening a command window and running the following command:
<GlassFish Install Dir>/bin/asadmin start-domain
Because the sample payroll application uses a database (to write out processed data), we need a database running before we can run our application. You can start the Apache Derby database by running the following command:
<GlassFish Install Dir>/bin/asadmin start-database
Compiling, Packaging, and Deploying the Payroll Application
First, create a new directory named hello-batch. Then change to the hello-batch directory:
cd hello-batch
To compile and package, run the following command, which creates hello-batch.war under the target directory:
mvn clean package
To deploy hello-batch.war, run the following command:
<GlassFish Install Dir>/bin/asadmin deploy target/hello-batch.war
If you want to redeploy the application, you can run the following command:
<GlassFish Install Dir>/bin/asadmin deploy -force target/hello-batch.war
Running the Payroll Application
Once you deploy the hello-batch.war file, you can run the application by accessing http://localhost:8080/hello-batch/PayrollJobSubmitterServlet from a browser. Accessing this URL should present the screen shown in Figure 2.
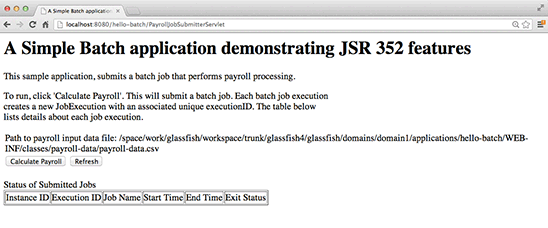
Figure 2
Click the Calculate Payroll button and you should see a new entry in the table, as shown in Figure 3.
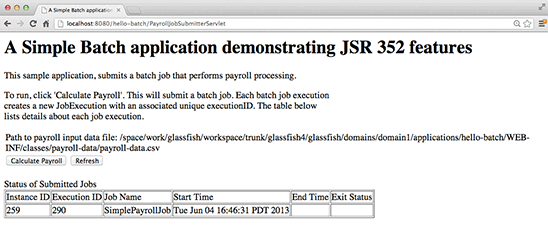
Figure 3
Click the Refresh button and you should see the Exit Status and End Time columns updated for the latest job (see Figure 4). The Exit Status column shows whether the job failed or completed successfully. Since our SimplePayrollJob doesn't have any errors (at least not yet!), the Exit Status displays COMPLETED.
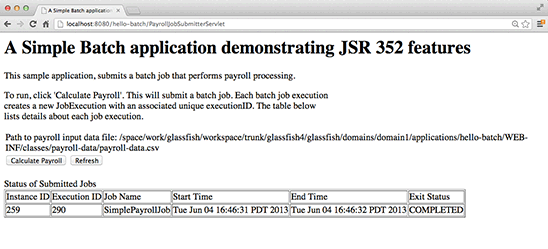
Figure 4
Click the Calculate Payroll and Refresh buttons a few more times. Note that each time a job is started, a new execution ID (and instance ID) is given to the job, as shown in Figure 5.
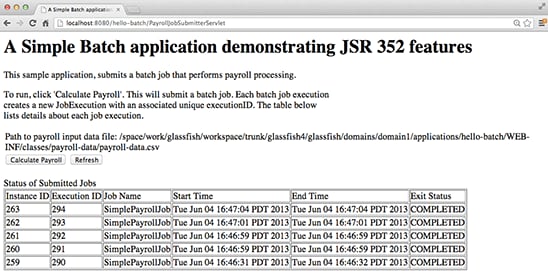
Figure 5
Restarting Failed Jobs
So far, we had been starting batch jobs using the jobOperator.start() method. Let's say that our payroll input file has some errors. Either the ItemReader or the ItemProcessor could detect invalid records and fail the current step and the job. The administrator or the end user can fix the error and can restart the batch job. This approach of launching a new job that starts from the beginning after recovering from errors might not scale if the amount of data to be processed is large. JobOperator provides another method called restart() to solve exactly this problem.
Quick Overview of JobInstance and JobExecution
We saw earlier that a job is essentially a container for steps. When a job is started, it must be tracked, so the batch runtime creates a JobInstance. A JobInstance refers to the concept of a logical run. In our example, we have a PayrollJob and if the PayrollJob is run every month, there will be a Jan-2013 JobInstance and there will be another Feb-2013 JobInstance, and so on.
If the payroll processing for Jan-2013 fails, it must be restarted (after presumably fixing the error), but it is still the Jan-2013 run because it is still processing Jan-2013 records.
A JobExecution refers to the concept of a single attempt to run a Job. Each time a job is started or restarted, a new JobExecution is created that belongs to the same JobInstance. In our example, if the Jan-2013 JobInstance is restarted, it is still the same Jan-2013 JobInstance but a new JobExecution is created that belongs to the same JobInstance.
In summary, a job can have one or more instances of JobInstance and each JobInstance can have one or more JobExecution instances. Using a new JobInstance means "start from the beginning" and using an existing JobInstance generally means "start from where you left off."
Resuming Failed Jobs
If you recall, a chunk-style step executes in a transaction in which item-count entries are read, processed, and written. After the ItemWriter's writeItems() has been invoked, the batch runtime calls the checkpointInfo() method on both ItemReader and ItemWriter. This allows both ItemReader and ItemWriter to bookmark (save) their current progress. The data that is bookmarked for an ItemReader could be anything that will help it to resume reading. For example, our SimpleItemReader needs to save the line number up to which it has read successfully so far.
Section 10.8 of the JSR 352 specification describes the restart processing in detail.
Let's take a moment to look into the log file where our SimpleItemReader outputs some useful messages from the open() and checkpoint() methods. Each message is prefixed with the string [SimpleItemReader] so you can quickly identify the messages. The log file is located at <GlassFish install Dir>/domains/domain1/logs/server.log.
Listing 10 shows the messages that are prefixed by the string [SimpleItemReader]:
[SimpleItemReader] Opened Payroll File. Will start reading from record number: 0]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 2]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 4]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 6]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 8]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 9]]
[SimpleItemReader] close called.]]Listing 10
Note: You could also use the command tail -f server.log | grep SimpleItemReader.
Because, our job XML file (SimplePayrollJob.xml) specifies a value of 2 for item-count as the chunk size, the batch runtime calls checkpointInfo() on our ItemReader every two records. The batch runtime stores this checkpoint information in JobRepository. So, if an error occurs during the midst of our chunk processing, the batch application must be able to resume from the last successful checkpoint.
Let's introduce some errors in our input data file and see how we can recover from input errors.
If you look at our servlet's output, which is located under <GlassFish install Dir>/domains/domain1/applications/hello-batch/WEB-INF/classes/payroll-data/payroll-data.csv, you see that it displays the location of the input file from where CSV data is read for our payroll application. Listing 11 shows the content of the file:
1, 8100
2, 8200
3, 8300
4, 8400
5, 8500
6, 8600
7, 8700
8, 8800
9, 8900Listing 11
Open your favorite editor and introduce an error. For example, let's say we add a few characters to the salary field on the eighth record, as shown in Listing 12:
1, 8100
2, 8200
3, 8300
4, 8400
5, 8500
6, 8600
7, 8700
8, abc8800
9, 8900Listing 12
Save the file and quit the editor. Go back to your browser and click the Calculate Payroll button followed by the Refresh button. You would see that the recently submitted job failed, as shown in Figure 6. (Look at the Exit Status column.)
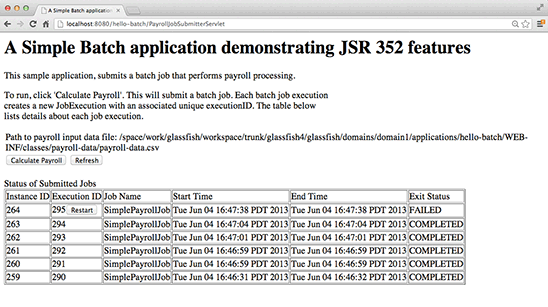
Figure 6
You will also notice that a Restart button appears next to the execution ID of the job that just failed. If you click Refresh, the job will fail (because we haven't fixed the issue yet). Figure 7 shows what is displayed after a few clicks of the Refresh button.
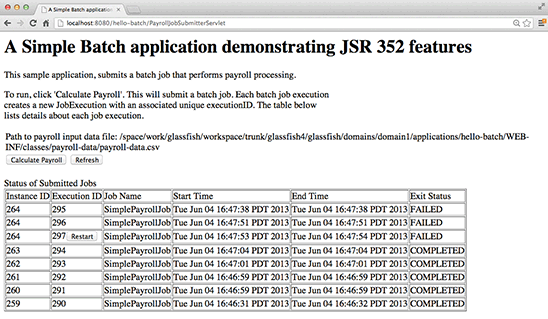
Figure 7
If you look into the GlassFish server log (located under <GlassFish install Dir>/domains/domain1/logs/server.log), you will see an exception, as shown in Listing 13:
Caught exception executing step: com.ibm.jbatch.container.exception.BatchContainerRuntimeException:
Failure in Read-Process-Write Loop
...
...
Caused by: java.lang.NumberFormatException: For input string: "abc8800"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:492)
at java.lang.Integer.parseInt(Integer.java:527)
at com.oracle.javaee7.samples.batch.hello.SimpleItemReader.readItem(SimpleItemReader.java:100)Listing 13
You should also notice that when you click the Restart button, a new job execution is created but its job instance ID remains the same. When you click the Refresh button, our PayrollJobSubmitter servlet calls a method named restartBatchJob(), which is shown in Listing 14:
private long restartBatchJob(long lastExecutionId)
throws Exception {
JobOperator jobOperator = BatchRuntime.getJobOperator();
Properties props = new Properties();
props.setProperty("payrollInputDataFileName", payrollInputDataFileName);
return jobOperator.restart(lastExecutionId, props);
}Listing 14
The key line in Listing 14 is the call to JobOperator's restart() method. This method takes a Properties object just like start(), but instead of passing a job XML file name, it passes the execution ID of the most recently failed job. Using the most recently failed job's execution ID, the batch runtime can retrieve the previous execution's last successful checkpoint. The retrieved checkpoint data is passed to the open() method of our SimpleItemReader (and ItemWriter) to enable them to resume reading (and writing) from the last successful checkpoint.
While ensuring that your browser shows the page with a Restart button, edit the file again and remove the extraneous characters from the eighth record. Then click the Restart and Refresh buttons. The latest execution should display a COMPLETED status, as shown in Figure 8.
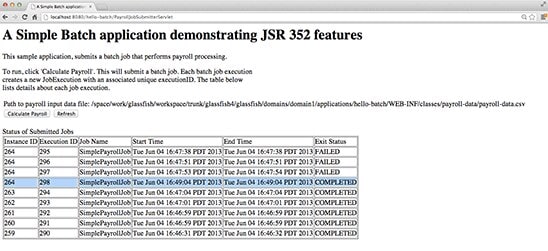
Figure 8
It is time to look into the log file to understand what just happened. Again, looking for messages prefixed with SimpleItemReader, Listing 15 shows what you might see:
[SimpleItemReader] Opened Payroll File. Will start reading from record number: 7]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 9]]
[SimpleItemReader] checkpointInfo() called. Returning current recordNumber: 10]]
[SimpleItemReader] close called.]]Listing 15
As you can see, our SimpleItemReader's open() method was called with the previous checkpoint value (which was record number 7) allowing our SimpleItemReader to skip the first six records and resume reading from the seventh record.
Viewing Batch Jobs Using the GlassFish 4.0 Admin Console
You can view the list of all batch jobs in the JobRepository. Fire up a browser window and go to localhost:4848. Then click server (Admin Server) in the left panel, as shown in Figure 9.
Figure 9
You can click the Batch tab, which should list all the batch jobs submitted to this GlassFish server. Note that the JobRepository is implemented using a database and, hence, the job details survive GlassFish 4.0 server restarts. Figure 10 shows all the batch jobs in the JobRepository.
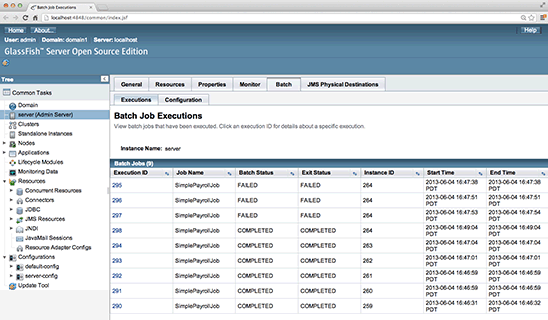
Figure 10
You can also click one of the IDs listed under Execution IDs. For example, clicking 293 reveals details about just that execution:
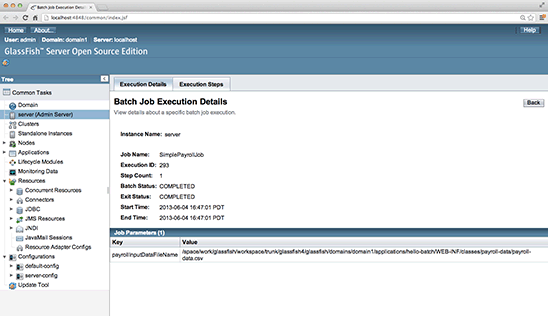
Figure 11
More details about the execution can be obtained by clicking the Execution Steps tab on the top.
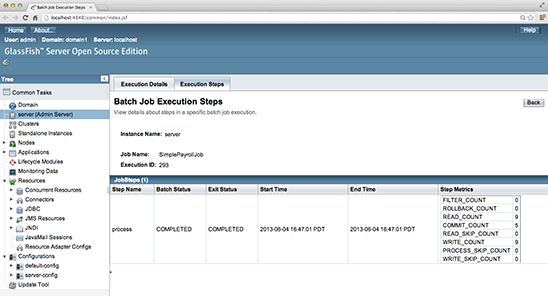
Figure 12
Look at the statistics provided by this page. It shows how many reads, writes, and commits were performed during this execution.
Viewing Batch Jobs Using the GlassFish 4.0 CLI
You can also view the details about jobs running in the GlassFish 4.0 server by using the command-line interface (CLI).
To view the list of batch jobs, open a command window and run the following command:
asadmin list-batch-jobs -l
You should see output similar to Figure 13:

Figure 13
To view the list of batch JobExecutions, you can run this command:
asadmin list-batch-job-executions -l
You should see output similar to Figure 14:
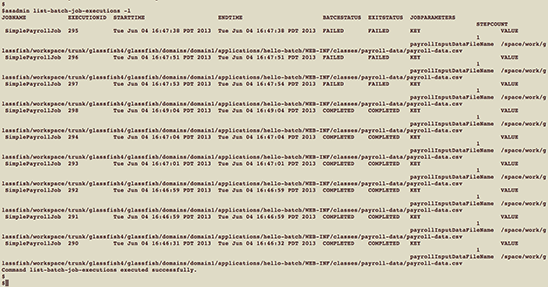
Figure 14
The command lists the completion status of each execution and also the job parameters passed to each execution.
Finally, in order to see details about each step in a JobExecution, you could use the following command:
asadmin list-batch-job-steps -l
You should see output similar to Figure 15:

Figure 15
Take note of the STEPMETRICS column. It tells how many times ItemReader and ItemWriter were called and also how many commits and rollbacks were done. These are extremely valuable metrics.
The CLI output must match the Admin Console view because they both query the same JobRepository.
You can use asadmin help <command-name> to get more details about the CLI commands.
Conclusion
In this article, we saw how to write, package, and run simple batch applications that use chunk-style steps. We also saw how the checkpoint feature of the batch runtime allows for the easy restart of failed batch jobs. Yet, we have barely scratched the surface of JSR 352. With the full set of Java EE components and features at your disposal, including servlets, EJB beans, CDI beans, EJB automatic timers, and so on, feature-rich batch applications can be written fairly easily.
This article also covered (briefly) the GlassFish 4.0 Admin Console and CLI support for querying the batch JobRepository. Both the Admin Console and the CLI provide valuable details about jobs and steps that can be used to detect potential bottlenecks.
JSR 352 supports many more exciting features such as batchlets, splits, flows, and custom checkpoints, which will be covered in future articles.
See Also
About the Author
Mahesh Kannan is a senior software engineer with Oracle's Cloud Application Foundation team, and he is the Expert Group Member for the Java Batch JSR. Due to his extensive experience with application servers, containers, and distributed systems, he has served as lead architect and "consultant at large" on many projects that build innovative solutions for Oracle products.
Join the Conversation
Join the Java community conversation on Facebook, Twitter, and the Oracle Java Blog!