
Development with JSP and XML-- Part II: JSP with XML in mind
By Qusay H. Mahmoud July 2001
Part II: JSP with XML in mind
The Extensible Markup Language (XML) has become the de facto standard data representation format for the Internet. XML data can be processed and interpreted on any platform--from handheld device to mainframe. It a perfect companion for Java applications that need portable data.
Java is the winner programming language to use with XML. Most XML parsers are written in Java, and it provides a comprehensive collection of Java APIs specifically targeted at building XML-based applications. JavaServer Pages (JSP) technology has access to all this since it can use the full power of the Java platform to access programming language objects to parse and transform XML documents. JSP has been designed with XML in mind; you can write a JSP page as an XML document!
This article presents a brief overview of XML, then it shows how to:
- Present XML documents
- Generate XML using JSP
- Parse XML documents using Simple Access API for XML (SAX) and Document
Object Model (DOM) - Use SAX and DOM in JSP
- Transform XML into other markup languages
Overview of XML
XML is a metalanguage used to define documents containing structured data. The features and benefits of XML can be grouped in the following major areas:
- Extensibility: as a metalanguage, XML can be used to create its own markup languages. Many XML-based markup languages exist today, including the Wireless Markup Language (WML).
- Precise structure: HTML suffers from loose structures and that makes it difficult to process HTML documents effectively. On the other hand, XML documents are well structured; each document has a root element and all elements must be nested within other elements.
- Two document types: there are two main XML document types
- Valid document: a valid XML document is defined by a Document Type Definition (DTD), which is the grammar of the document that defines what kind of elements, attributes, and entities may be in the document. The DTD defines the order as well as the occurrence of elements.
- Well-Formed document: a well-formed XML document does not have to adhere to a DTD. But it must follow two rules: 1) each element must have an open tag and a close tag. 2) there must be one root element that contains all other elements.
- Powerful extensions: as we mentioned earlier, XML is used to define syntax only. In other words, it is used to define content. To define the semantics, style, or presentation you need to use the Extensible Stylesheet Language (XSL). Note that a document may have multiple stylesheets that can be used by different users.
Note: A well-formed document is handy if the document is simple, or when processing simple structures over networks where bandwidth is a concern, since it does not have the overhead of a complex DTD.
XML versus HTML
XML and HTML are both markup languages, where tags are used to annotate data. The main differences are:
- In HTML, the syntax and semantics of the document are defined. HTML alone can be used to create a visible presentation to the user. XML allows you to define document syntax.
- HTML documents are not well-formed. For example, not all tags are closed with a matching tag. XML documents are well-formed.
- Tag names are case sensitive in XML, but not in HTML.
Let's look at an XML document. The following example is a sample XML document, from a fictitious quote server, representing a portfolio of stocks. As you can see, there is one root element (portfolio), and every element has a start tag and a close tag.
Sample 1: stocks.xml
<?xml version="1.0" encoding="UTF-8"?>
<portfolio>
<stock>
<symbol>SUNW</symbol>
<name>Sun Microsystems</name>
<price>17.1</price>
</stock>
<stock>
<symbol>AOL</symbol>
<name>America Online</name>
<price>51.05</price>
</stock>
<stock>
<symbol>IBM</symbol>
<name>International Business Machines</name>
<price>116.10</price>
</stock>
<stock>
<symbol>MOT</symbol>
<name>MOTOROLA</name>
<price>15.20</price>
</stock>
</portfolio>The first line of Sample 1 states the XML version number, which is 1; and lets the processor know that the encoding scheme to be used is "UTF-8".
Although this is a simple document, it contains useful information that can be processed easily since it is well structured. For example, the stock server may want to sort the portfolio, in a specific order, based on the price of stocks.
Presenting XML Documents
XML documents contain portable data. This means that the example in Sample 1 can be processed for output to different browsers (desktop browser for the PC, microbrowser for the handheld device). In other words, an XML document can be transformed into HTML or WML or any other markup language.
If you load the stocks.xml document in a browser that supports XML (such as Microsoft's IE), you would see something similar to Figure 1.

Figure 1: stocks.xml in a browser
Basically, the browser has parsed the document and displayed it in a structured manner. But, this is not really useful from a user's point of view. Users want to see data displayed as useful information in a way that is easy to navigate.
One way to display XML documents nicely is to apply a transformation on the XML document, either to extract the data or create a new format (such as transforming XML data to HTML). This transformation can be done using a transformation language such as the Extensible Stylesheet Language Transformation (XSLT), which is part of XSL. XSL allows you to write XML vocabulary for specifying formatting semantics. In other words, there are two parts to XSL, which is part of the World Wide Web Consortium (W3C) Style Activity:
- Transformation language (XSLT)
- Formatting language (XSL formatting objects)
The XSL stylesheet in Sample 2 performs the required transformation for the portfolio element. It generates HTML markup and extracts data from the elements in the stocks.xml document.
Sample 2: stocks.xsl
<?xml version="1.0"?>
<xsl:stylesheet version="1.0" xmlns:xsl=
"http://www.w3.org/TR/WD-xsl">
<xsl:template match="/">
<html>
<head>
<title>Stocks</title>
</head>
<body bgcolor="#ffffcc" text="#0000ff">
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="portfolio">
<table border="2" width="50%">
<tr>
<th>Stock Symbol</th>
<th>Company Name</th>
<th>Price</th>
</tr>
<xsl:for-each select="stock">
<tr>
<td>
<i><xsl:value-of select=
"symbol"/></i>
</td>
<td>
<xsl:value-of select="name"/>
</td>
<td>
<xsl:value-of select="price"/>
</td>
</tr>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>It looks a bit complex, right? Only at first. Once you get the hang of the XSL syntax, it is rather straightforward. Here is what the above syntax is all about:
- xsl:stylesheet: root element
- xsl:template: how to transform selected nodes
- match: attribute to select node
- "/": root node of input XML document
- xsl:apply-templates: apply templates to the children of the selected node
- xsl:value-of: select nodes (extract data from selected nodes)
Now, the question is: how to use this XSL stylesheet with the stocks.xml document? The answer is easy: we need to modify the first line in the stocks.xml document in Sample 1 to use the stocks.xsl stylesheet for presentation. The first line of Sample 1 now should be:
<?xml:stylesheet type="text/xsl" href="/developer/technicalArticles/xml/WebAppDev2/stocks.xsl" version="1.0" encoding="UTF-8"?>
This basically says that when you load stocks.xml in a browser (it will be parsed as a tree of nodes), the corresponding stylesheet should be used to extract data from the tree nodes. When you load the modified stocks.xml in a browser that supports XML and XSL (such as Microsoft's IE), you see something similar to Figure 2.

Figure 2: Using a stylesheet (stocks.xsl)
Generating XML from JSP
JSP technology can be used to generate XML documents. A JSP page could easily generate a response containing the stocks.xml document from Sample 1, as shown in Sample 3. The main requirement for generating XML is that the JSP page set the content type of the page appropriately. As you can see from Sample 3, the content type is set to text/xml. The same technique can be used to generate other markup languages (such as WML).
Sample 3: genXML.jsp
<%@ page contentType="text/xml" %>
<?xml version="1.0" encoding="UTF-8"?>
<portfolio>
<stock>
<symbol>SUNW</symbol>
<name>Sun Microsystems</name>
<price>17.1</price>
</stock>
<stock>
<symbol>AOL</symbol>
<name>America Online</name>
<price>51.05</price>
</stock>
<stock>
<symbol>IBM</symbol>
<name>International Business
Machines</name>
<price>116.10</price>
</stock>
<stock>
<symbol>MOT</symbol>
<name>MOTOROLA</name>
<price>15.20</price>
</stock>
</portfolio>If you request the genXML.jsp page from a web server (such as Tomcat), you would see something similar to Figure 1.
Generating XML from JSP and JavaBeans
The data for the XML can also be retrieved from a JavaBeans component. For example, the following JavaBeans component, PortfolioBean, defines a bean with the stocks data.
Sample 4: PortfolioBean.java
package stocks;
import java.util.*;
public class PortfolioBean implements
java.io.Serializable {
private Vector portfolio = new Vector();
public PortfolioBean() {
portfolio.addElement(new Stock("SUNW",
"Sun Microsystems", (float) 17.1));
portfolio.addElement(new Stock("AOL",
"America Online", (float) 51.05));
portfolio.addElement(new Stock("IBM",
"International Business Machines",
(float) 116.10));
portfolio.addElement(new Stock("MOT",
"MOTOROLA", (float) 15.20));
}
public Iterator getPortfolio() {
return portfolio.iterator();
}
}The PortfolioBean class uses the Stock class, which is shown in Sample 5.
Sample 5: Stock.java
package stocks;
public class Stock implements java.io.Serializable {
private String symbol;
private String name;
private float price;
public Stock(String symbol, String name,
float price) {
this.symbol = symbol;
this.name = name;
this.price = price;
}
public String getSymbol() {
return symbol;
}
public String getName() {
return name;
}
public float getPrice() {
return price;
}
}Now, we can write a JSP page to generate an XML document where the data is retrieved from the PortfolioBean, as shown in Sample 6.
Sample 6: stocks.jsp
<%@ page contentType="text/xml" %>
<%@ page import="stocks.*" %>
<jsp:useBean id="portfolio"
class="stocks.PortfolioBean" />
<%
java.util.Iterator folio =
portfolio.getPortfolio();
Stock stock = null;
%>
<?xml version="1.0" encoding="UTF-8"?>
<portfolio>
<% while (folio.hasNext()) { %>
<% stock = (Stock)folio.next(); %>
<stock>
<symbol<>%=
stock.getSymbol() %></symbol>
<name<>%=
stock.getName() %></name>
<price<>%=
stock.getPrice() %></price>
</stock>
<% } %>
</portfolio>If you request the stocks.jsp page from a browser supporting XML, you would see something similar to Figure 3.

Figure 3: generating XML from JSP and JavaBeans
If you replace the line:
<?xml version="1.0" encoding="UTF-8"?>
with a line that specifies a stylesheet to be used:
<?xml:stylesheet type="text/xsl" href="/developer/technicalArticles/xml/WebAppDev2/stocks.xsl" version="1.0" encoding="UTF-8"?>
the XML document will be generated and the XSL stylesheet will be applied and you see something similar to Figure 2 above.
Converting XML to Server-Side Objects
We have seen how to generate XML, so the question is now how to consume (or use) it in applications. In order to do that we need to convert the XML to server-side objects and extract the object properties. The conversion is not automatic; we have to manually parse an XML document, and encapsulate it into a JavaBeans component. In the future however, the XML/Java Binding Technology will automate this process as it will enable you to compile an XML schema into Java classes.
For parsing, there are two interfaces that can be used:
- Simple API for XML (SAX)
- Document Object Model (DOM)
Before we delve into these two parsing techniques, we will first describe the software environment.
The Software Environment
The software environment we will use for parsing is the Java API for XML Processing (JAXP) version 1.1 which supports SAX 2.0, DOM level 2, and XSL transformations.
To install, unzip it in a directory of your choice, and update the classpath to include the three JAR files for JAXP:
- crimson.jar: the default XML parser, which was derived from the Java Project X parser from Sun
- xalan.jar: the default XSLT engine
- jaxp.jar: the APIs
Alternatively, you can install these JAR files as an extension of Java 2 simply by copying them to JAVA_HOME/jre/lib/ext directory, where JAVA_HOME is the directory where you installed the JDK (for example c:\jdk1.3). Installing the JAR files as Java 2 extensions eliminates the need to modify the classpath.
Simple API for XML (SAX)
SAX is a simple API for XML. It is not a parser! It is simply a standard interface, implemented by many different XML parsers, that was developed by members of the XML-DEV mailing list, currently hosted by OASIS.
The main advantage of SAX is that it is lightweight and fast. This is mainly because it is an event-based API, meaning it reports parsing events (such as the start and end of elements) directly to the application using callbacks, as shown in Figure 4. Therefore, the application implements handlers to deal with the different events, much like handling events in a graphical user interface.
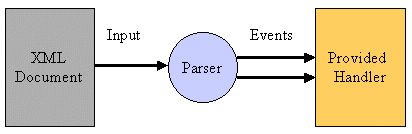
Figure 4: SAX uses callbacks to notify handlers of things of interest
Using SAX involves the following steps, as shown in Sample 7:
- Implement one or more handlers (in this example the
ContentHandleris implemented) - Create an
XMLReader - Create an
InputSource - Call
parseon the input source
Note that MySAXParserBean overrides the methods startElement, endElement, and characters, all of which are defined by the ContentHandler interface. The parser invokes the startElement method at the beginning of every element in the XML document, and invokes the characters method to report each chunk of character data, and finally, invokes the endElement method at the end of every element in the XML document.
package saxbean;
import java.io.*;
import java.util.*;
import org.xml.sax.*;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.SAXParserFactory;
import
javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
public class MySAXParserBean extends
DefaultHandler implements java.io.Serializable {
private String text;
private Vector vector = new Vector();
private MyElement current = null;
public MySAXParserBean() {
}
public Vector parse(String filename) throws
Exception {
SAXParserFactory spf =
SAXParserFactory.newInstance();
spf.setValidating(false);
SAXParser saxParser = spf.newSAXParser();
// create an XML reader
XMLReader reader = saxParser.getXMLReader();
FileReader file = new FileReader(filename);
// set handler
reader.setContentHandler(this);
// call parse on an input source
reader.parse(new InputSource(file));
return vector;
}
// receive notification of the beginning of an
element
public void startElement (String uri, String name,
String qName, Attributes atts) {
current = new MyElement(
uri, name, qName, atts);
vector.addElement(current);
text = new String();
}
// receive notification of the end of an element
public void endElement (String uri, String name,
String qName) {
if(current != null && text != null) {
current.setValue(text.trim());
}
current = null;
}
// receive notification of character data
public void characters (char ch[], int start,
int length) {
if(current != null && text != null) {
String value = new String(
ch, start, length);
text += value;
}
}
}MySAXParserBean is using the MyElement class, which is defined in Sample 8.
Sample 8: MyElement.java
package saxbean;
import org.xml.sax.Attributes;
public class MyElement implements
java.io.Serializable {
String uri;
String localName;
String qName;
String value=null;
Attributes attributes;
public MyElement(String uri, String localName,
String qName, Attributes attributes) {
this.uri = uri;
this.localName = localName;
this.qName = qName;
this.attributes = attributes;
}
public String getUri() {
return uri;
}
public String getLocalName() {
return localName;
}
public String getQname() {
return qName;
}
public Attributes getAttributes() {
return attributes;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}Now, if you like, you can test the MySAXParserBean from the command line to make sure it is working. Sample 9 shows a simple test driver.
Sample 9: MyTestDriver.java
import java.io.*;
import java.util.*;
public class MyTestDriver {
public static void main(String argv[]) {
String file = new String(argv[0]);
MySAXParserBean p = new MySAXParserBean();
String str = null;
try {
Collection v = p.parse(file);
Iterator it = v.iterator();
while(it.hasNext()) {
MyElement element =
(MyElement)it.next();
String tag = element.getLocalName();
if(tag.equals("symbol")) {
System.out.println("Symbol:
" + element.getValue());
} else if(tag.equals("name")) {
System.out.println("Name: "
+element.getValue());
} else if (tag.equals("price")) {
System.out.println("Price: "
+element.getValue());
}
}
} catch (Exception e) {
}
}
}If you run MyTestDriver by providing the XML document in Sample 1 "stocks.xml", you will see something similar to Figure 5.
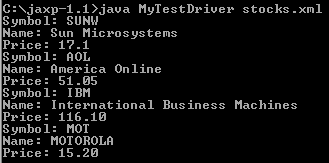
Figure 5: Testing the XML parser from the command line
Now, let's see how to use the MySAXParserBean from a JSP page. As you can see from Sample 10, it is straightforward. We invoke the MySAXParserBean's parse method on an XML document (stocks.xml), and then we iterate over the stocks to extract data and format it into an HTML table.
Note: The XML document input to the parse method can be a URL referencing an XML document.
Sample 10: saxstocks.jsp
<html>
<head>
<title>sax parser</title>
<%@ page import="java.util.*" %>
<%@ page import="saxbean.*" %>
</head>
<body bgcolor="#ffffcc">
<jsp:useBean id="saxparser"
class="saxbean.MySAXParserBean" />
<%
Collection stocks =
saxparser.parse("c:/stocks/stocks.xml");
Iterator ir = stocks.iterator();
%>
<center>
<h3>My Portfolio</h3>
<table border="2" width="50%">
<tr>
<th>Stock Symbol</th>
<th>Company Name</th>
<th>Price</th>
</tr>
<tr>
<%
while(ir.hasNext()) {
MyElement element = (MyElement) ir.next();
String tag = element.getLocalName();
if(tag.equals("symbol")) { %>
<td><%= element.getValue() %></td>
<% } else if (tag.equals("name")) { %>
<td><%= element.getValue() %></td>
<% } else if (tag.equals("price")) { %>
<td><%= element.getValue() %><
/td></tr><tr>
<% } %>
<% } %>
</body>
</html>If you request saxstocks.jsp you would see something similar to Figure 6.

Figure 6: Using MySAXParserBean from JSP
Document Object Model (DOM)
The DOM is a platform- and language-neutral interface for accessing and updating documents. Unlike SAX however, DOM accesses an XML document through a tree structure, composed of element nodes and text nodes, as shown in Figure 7.

Figure 7: DOM creates a tree from an XML document
The tree will be built in memory and therefore there are large memory requirements when using DOM. The advantage of DOM, however, is that it is simpler to program with than SAX. As you can see from Sample 11, an XML document can be turned into a tree in three lines of code. Once you have a tree, you can walk or traverse it back and forth.
Sample 11: MyDOMParserBean.java
package dombean;
import javax.xml.parsers.*;
import org.w3c.dom.*;
import java.io.*;
public class MyDOMParserBean
implements java.io.Serializable {
public MyDOMParserBean() {
}
public static Document
getDocument(String file) throws Exception {
// Step 1: create a DocumentBuilderFactory
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance();
// Step 2: create a DocumentBuilder
DocumentBuilder db = dbf.newDocumentBuilder();
// Step 3: parse the input file to get
a Document object
Document doc = db.parse(new File(file));
return doc;
}
}This will produce a tree, so we need to traverse it. This is done using the traverseTree method in the JSP page, domstocks.jsp, in Sample 12.
Sample 12: domstocks.jsp
<html>
<head>
<title>dom parser</title>
<%@ page import="javax.xml.parsers.*" %>
<%@ page import="org.w3c.dom.*" %>
<%@ page import="dombean.*" %>
</head>
<body bgcolor="#ffffcc">
<center>
<h3>My Portfolio</h3>
<table border="2" width="50%">
<tr>
<th>Stock Symbol</th>
<th>Company Name</th>
<th>Price</th>
</tr>
<jsp:useBean id="domparser"
class="dombean.MyDOMParserBean" />
<%
Document doc =
domparser.getDocument("c:/stocks/stocks.xml");
traverseTree(doc, out);
%>
<%! private void traverseTree(Node node,
JspWriter out) throws Exception {
if(node == null) {
return;
}
int type = node.getNodeType();
switch (type) {
// handle document nodes
case Node.DOCUMENT_NODE: {
out.println("<tr>");
traverseTree
(((Document)node).getDocumentElement(),
out);
break;
}
// handle element nodes
case Node.ELEMENT_NODE: {
String elementName = node.getNodeName();
if(elementName.equals("stock")) {
out.println("</tr><tr>");
}
NodeList childNodes =
node.getChildNodes();
if(childNodes != null) {
int length = childNodes.getLength();
for (int loopIndex = 0; loopIndex <
length ; loopIndex++)
{
traverseTree
(childNodes.item(loopIndex),out);
}
}
break;
}
// handle text nodes
case Node.TEXT_NODE: {
String data =
node.getNodeValue().trim();
if((data.indexOf("\n") <0
) && (data.length()
> 0)) {
out.println("<td>"+
data+"</td>");
}
}
}
}
%>
</body>
</html>If you request domstocks.jsp from a browser, you would see something similar to Figure 6 above.
Transforming XML
As browsers are becoming available on more devices, the ability to transform Internet data into multiple formats, such as XML, HTML, WML, or XHTML, becomes increasingly important. The XSLT can be used to transform XML into any desired format. A transformation engine or processor would take an XML document as input and use the XSL transformation stylesheet to create a new document format, as shown in Figure 8.
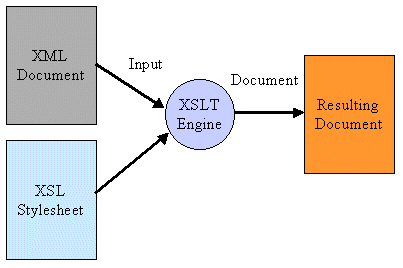
Figure 8: Using an XSLT engine
The following example, xml2html, shows how to transform the XML document, stocks.xml, into an HTML document, stocks.html. As you can see, once you have the XML document and XSL stylesheet to apply, the whole transformation is done in three lines.
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
import java.io.*;
public class xml2html {
public static void main(String[] args)
throws TransformerException,
TransformerConfigurationException,
FileNotFoundException, IOException
{
TransformerFactory tFactory =
TransformerFactory.newInstance();
Transformer transformer =
tFactory.newTransformer(
new StreamSource("stocks.xsl"));
transformer.transform(
new StreamSource(args[0]),
new StreamResult(new FileOutputStream(
args[1])));
System.out.println
("** The output is written in "+
args[1]+" **");
}
}To run this example, use the command:
C:> java xml2html stocks.xml stocks.html
stocks.xml is the input file, and it will be transformed into stocks.html based on the stylesheet stocks.xsl. Here we are using the earlier stylesheet, but we have added a couple of new lines to specify the method of output (HTML in this case) as shown in Sample 14.
Sample 14: stocks.xsl
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl=
"http://www.w3.org/1999/XSL/Transform" version=
"1.0">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="portfolio">
<table border="2" width="50%">
<xsl:for-each select="stock">
<tr>
<td>
<i><xsl:value-of select=
"symbol"/></i>
</td>
<td>
<xsl:value-of select="name"/>
</td>
<td>
<xsl:value-of select="price"/>
</td>
</tr>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>The HTML that will be generated is shown in Figure 9.
![]()
Figure 9: xml2html transformation
Conclusion
A previous article in this series, Web Application Development with JSP and XML--Part I: Fast Track JSP, created a heated discussion arguing whether or not JSP allows developers to separate the business logic from the presentation. My answer is: it depends on how you use JSP! In this article we have seen how to generate the same presentation using different parsing techniques. In some of these examples however, the business logic is mixed with presentation. In the next article we show you how to write your own custom tags and tag libraries that help in separating business logic from presentation.
For more Information
About the Author
Qusay H. Mahmoud provides Java consulting and training services. He has published dozens of articles on Java, and is the author of Distributed Programming with Java (Manning Publications, 1999).