This topic provides a guide to the various performance tuning options in OEDQ.
There are four general techniques, applicable to all types of process, that are available to maximize performance in OEDQ.
Click on the headings below for more information on each technique:
In the case of Parsing and Matching, a large amount of work is performed by an individual processor, as each processor has many stages of processing. In these cases, options are available to optimize performance at the processor level.
Click on the headings below for more information on how to maximize performance when parsing or matching data:
The option to stream data in OEDQ allows you to bypass the task of staging data in the OEDQ repository database when reading or writing data.
A fully streamed process or job will act as a pipe, reading records directly from a data store and writing records to a data target, without writing any records to the OEDQ repository.
When running a process, it may be appropriate to bypass running your snapshot altogether and stream data through the snapshot into the process directly from a data store. For example, when designing a process, you may use a snapshot of the data, but when the process is deployed in production, you may want to avoid the step of copying data into the repository, as you always want to use the latest set of records in your source system, and because you know you will not require users to drill down to results.
To stream data into a process (and therefore bypass the process of staging the data in the OEDQ repository), create a job and add both the snapshot and the process as tasks. Then click on the staged data table that sits between the snapshot task and the process and disable it. The process will now stream the data directly from the source system. Note that any selection parameters configured as part of the snapshot will still apply.
Note that any record selection criteria (snapshot filtering or sampling options) will still apply when streaming data. Note also that the streaming option will not be available if the Data Store of the Snapshot is Client-side, as the server cannot access it.
Streaming a snapshot is not always the 'quickest' or best option, however. If you need to run several processes on the same set of data, it may be more efficient to snapshot the data as the first task of a job, and then run the dependent processes. If the source system for the snapshot is live, it is usually best to run the snapshot as a separate task (in its own phase) so that the impact on the source system is minimized.
It is also possible to stream data when writing data to a data store. The performance gain here is less, as when an export of a set of staged data is configured to run in the same job after the process that writes the staged data table, the export will always write records as they are processed (whether or not records are also written to the staged data table in the repository).
However, if you know you do not need to write the data to the repository (you only need to write the data externally), you can bypass this step, and save a little on performance. This may be the case for deployed data cleansing processes, or if you are writing to an external staging database that is shared between applications, for example when running a data quality job as part of a larger ETL process, using an external staging database to pass the data between OEDQ and the ETL tool.
To stream an export, create a job and add the process that writes the data as a task, and the export that writes the data externally as another task. Then disable the staged data that sits between the process and the export task. This will mean that the process will write its output data directly to the external target.
Note that Exports to Client-side data stores are not available as tasks to run as part of a job. They must be run manually from the OEDQ Director Client as they use the client to connect to the data store.
Minimizing results writing is a different type of 'streaming', concerned with the amount of Results Drilldown data that OEDQ writes to the repository from processes.
Each process in OEDQ runs in one of three Results Drilldown modes:
All mode should be used only on small volumes of data, to ensure that all records can be fully tracked in the process at every processing point. This mode is useful when processing small data sets, or when debugging a complex process using a small number of records.
Sample mode is suitable for high volumes of data, ensuring that a limited number of records is written for each drilldown. The System Administrator can set the number of records to write per drilldown; by default this is 1000 records. Sample mode is the default.
None mode should be used to maximize the performance of tested processes that are running in production, and where users will not need to interact with results.
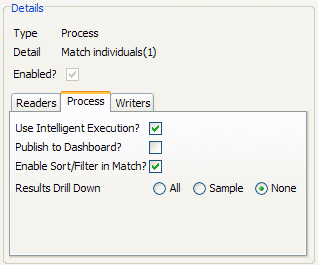
To change the Results Drilldown mode when executing a process, use the Process Execution Preferences screen, or create a Job and click on the process task to configure it.
For example, the following process is changed to write no drilldown results when it is deployed in production:
When working with large data volumes, it can take a long time to index snapshots and written staged data in order to allow users to sort and filter the data in the Results Browser. In many cases, this sorting and filtering capability will not be needed, or only needed when working with smaller samples of the data.
The systemapplies intelligent sorting and filtering enablement, where it will enable sorting and filtering when working with smaller data sets, but will disable sorting and filtering for large data sets. However, you can choose to override these settings - for example to achieve maximum throughput when working with a number of small data sets.
When a snapshot is created, the default setting is to 'Use intelligent Sort/Filtering options', so that the system will decide whether or not to enable sorting and filtering based on the size of the snapshot. See Enabling sorting and filtering on snapshots.
However, If you know that no users will need to sort or filter results that are based on a snapshot in the Results Browser, or if you only want to enable sorting or filtering at the point when the user needs to do it, you can disable sorting and filtering on the snapshot when adding or editing it.
To do this, edit the snapshot, and on the third screen (Column Selection), uncheck the option to Use intelligent Sort/Filtering, and leave all columns unchecked in the Sort/Filter column:

Alternatively, if you know that sorting and filtering will only be needed on a sub-selection of the available columns, use the tick boxes to select the relevant columns.
Disabling sorting and filtering means that the total processing time of the snapshot will be less as the additional task to enable sorting and filtering will be skipped.
Note that if a user attempts to sort or filter results based on a column that has not been enabled, the user will be presented with an option to enable it at that point.
When staged data is written by a process, the server does not enable sorting or filtering of the data by default. The default setting is therefore maximized for performance.
If you need to enable sorting or filtering on written staged data - for example, because the written staged data is being read by another process which requires interactive data drilldowns - you can enable this by editing the staged data definition, either to apply intelligent sort/filtering options (varying whether or not to enable sorting and filtering based on the size of the staged data table), or to enable it on selected columns (as below):

It is possible to set sort/filter enablement options for the outputs of matching. See Matching performance options.
The OEDQ server should be configured for optimal performance.
For Windows server installations, the OEDQ installer will set a number of performance settings automatically according to the specification of the server it is installed on. However, for other platforms, the settings may need to be changed manually.
Note that the server configuration should only be changed by an administrator.
Two configuration options are particularly important for performance:
For Windows server installations, the number of process threads used to execute jobs is automatically set by the installer to the number of available CPUs, and should therefore not need to be changed. However, for other platforms (Unix or Linux), you will need to add the following line to the override.properties file in the config directory where OEDQ is installed:
processengine.processThreads = [number of threads]
Note that as for Windows, we recommend setting the number of threads to the number of CPUs on the server.
If you need to write a lot of results to the OEDQ results repository, as is typical when using OEDQ particularly for profiling, analysis and matching, the type of database used for the repository becomes very important to performance.
The default OEDQ repository is a PostgreSQL database, configured for OEDQ.
However, for very large volumes of data, there will be significant performance improvements when reading from and writing to the repository if you use an Oracle database (version 10i or 11i).
To change the type of repository database, go to the OEDQ Launchpad, select Configuration, and then Database Setup. You will need to log in as an OEDQ user with administration privileges.
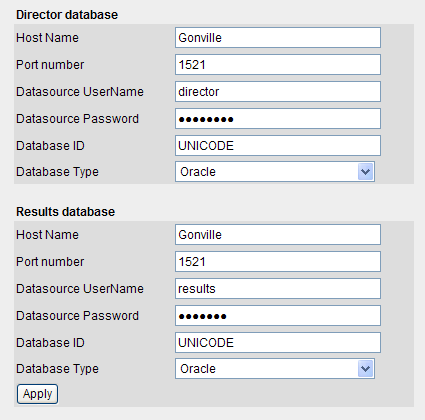
You can then change the two databases used by OEDQ - the Director database (used to store project configuration data), and the Results database (used to store results data). The Results database is the repository database.
For example, the below screenshot shows changing the Director and Results databases to use an Oracle database:
Note that the server may be remote from the application server where OEDQ will run, but it must be on a fast network connection.
When maximum performance is required from a Parse processor, it should be run in Parse mode, rather than Parse and Profile mode.
This is particularly true for any Parse processors with a complete configuration, where you do not need to investigate the classified and unclassified tokens in the parsing output.
For even better performance where only metrics and data output are required from a Parse processor, the process that includes the parser may be run with no drilldowns - see Minimized results writing above.
When designing a Parse configuration iteratively, where fast drilldowns are required, it is generally best to work with small volumes of data. When working with large volumes of data, an Oracle results repository will greatly improve drilldown performance.
The following techniques may be used to maximize matching performance:
Matching performance may vary greatly depending on the configuration of the match processor, which in turn depends on the characteristics of the data involved in the matching process. The most important aspect of configuration to get right is the configuration of clustering in a match processor.
In general, there is a balance to be struck between ensuring that as many potential matches as possible are found and ensuring that redundant comparisons (between records that are not likely to match) are not performed. Finding the right balance may involve some trial and error - for example, assessment of the difference in match statistics when clusters are widened (perhaps by using fewer characters of an identifier in the cluster key) or narrowed (perhaps by using more characters of an identifier in a cluster key), or when a cluster is added or removed.
The following two general guidelines may be useful:
See the Clustering Concept Guide for more information about how clustering works and how to optimize the configuration for your data.
By default, sorting, filtering and searching are enabled on all match results to ensure that they are available for user review. However, with large data sets, the indexing process required to enable sorting, filtering and searching may be very time-consuming, and in some cases, may not be required.
If you do not require the ability to review the results of matching using the Review Application, and you do not need to be able to sort or filter the outputs of matching in the Results Browser, you should disable sorting and filtering to improve performance. For example, the results of matching may be written and reviewed externally, or matching may be fully automated when deployed in production.
The setting to enable or disable sorting and filtering is available both on the individual match processor level, available from the Advanced Options of the processor (see Sort/Filter options for match processors for details), and as a process or job level override.
To override the individual settings on all match processors in a process, and disable the sorting, filtering and review of match results, untick the option to Enable Sort/Filter in Match processors in a job configuration, or process execution preferences:

Match processors may write out up to three types of output:
By default, all available output types are written. (Merged Output cannot be written from a Link processor.)
However, not all the available outputs may be needed in your process. For example you should disable Merged Output if you only want to identify sets of matching records.
Note that disabling any of the outputs will not affect the ability of users to review the results of a match processor.
To disable Match (or Alert) Groups output:
Or, if you know you only want to output the groups of related or unrelated records, use the other tick boxes on the same part of the screen.
To disable Relationships output:
Or, if you know you only want to output some of the relationships (such as only Review relationships, or only relationships generated by certain rules), use the other tick boxes on the same part of the screen.
To disable Merged Output:
Or, if you know you only want to output the merged output records from related records, or only the unrelated records, use the other tick boxes on the same part of the screen.
Batch matching processes require a copy of the data in the OEDQ repository in order to compare records efficiently.
As data may be transformed between the Reader and the match processor in a process, and in order to preserve the capability to review match results if a snapshot used in a matching process is refreshed, match processors always generate their own snapshots of data (except from real time inputs - see Real time matching) to work from. For large data sets, this can take some time.
Where you want to use the latest source data in a matching process, therefore, it may be advisable to stream the snapshot rather than running it first and then feeding the data into a match processor, which will generate its own internal snapshot (effectively copying the data twice). See Streaming a Snapshot above.
Oracle ® Enterprise Data Quality Help version 9.0
Copyright ©
2006,2012, Oracle and/or its affiliates. All rights reserved.