Match |
Match is a sub-processor of all matching processors except Group and Merge. The purpose of the Match stage of match processor configuration is to configure the main matching process, that is, how to compare records, and how to interpret the results of those comparisons (as automatically match, do not match, or assign for manual review).
It is also possible to configure how to output the results of the matching process - that is, the sets of matching records, and the relationships created between records.
The four tabs of match configuration are:
The set of comparisons and match rules needed to match records accurately will depend on the requirements of the matching process, and also on the quality of the data being matched.
In general, when first developing a match process, the following tips are useful:
For more high-level information about matching in OEDQ, see the Matching concept guide.
There are four steps of configuration of the Match sub-processor, with different tabs on the configuration dialog for each.
For match processors which use Match Review to review possible matches, the tabs appear as follows. Click on the relevant tab on the image below for information about each step:

For match processors which use Case Management to review possible matches, the tabs appear as follows. Click on the relevant tab on the image below for information about each step:

The main configuration of matching is encapsulated in the Comparisons and Match rules tabs. The two types of output have default configuration settings, which will often not need to be changed, or may only need changing when the development of the match process is nearing completion.
Comparisons are matching functions that determine how well two records match each other, for a given identifier.
OEDQ comes with a library of comparisons to cover the majority of matching needs. New comparisons may also be scripted and added into OEDQ - see Extending matching in OEDQ.
Comparisons compare all the records within a cluster group with each other, and produce a comparison result. The possible comparison results depend on the comparison, and the type of identifier (such as String, number or date) being compared.
For example, the Exact String Match comparison delivers one of the following results for each comparison it performs:
So, the exact String match comparison simply determines whether or not a pair of records match.
By contrast, the Character Edit Distance comparison attempts to find how well a pair of records match, by calculating a numeric value for how many character edits it would take to get from one value to another. For example the values 'test' and 'test' would match exactly, meaning a character edit distance result of 0, the values 'test' and 'tast' have a character edit distance of 1, because a single character is different, and the values 'test' and 'mrtest' would result in a character edit distance of 2, because two characters are different.
Comparisons are added to each identifier using the Add Comparison button at the bottom of the dialog. It is also possible to copy and paste comparisons (for example, if you want the same comparison configuration on another identifier), by copying (Ctrl + C) with a comparison selected and pasting (Ctrl + V), with an identifier. Note that comparisons can also be copied between matching processors, so you can reuse comparison configurations that you have used in other match processors.
Each comparison is configured using the right-hand side of the dialog.
Adding transformations to comparisons
Adding transformations on comparisons allows identifiers to be transformed before they are compared.
For example, you might want to strengthen a match rule where identifier values (such as names) are similar, but do not match exactly, with a comparison that ensures that the two values sound the same. To do this, use an Exact String match comparison, but add a Metaphone transformation to the comparison, so that you are comparing the metaphone key for each identifier rather than the individual value - this would mean (for example) that 'Jhon' and 'John' would match.
Comparison transformations may themselves require configuration, depending on the transformation used. See the help pages for the individual transformations for a full guide.
Comparison options
The comparison options vary depending on the comparison used. For a full guide to the available options, see the help pages for the individual comparisons. For example, the following options are available for the Exact String match comparison:
Comparisons that yield numeric results (such as a match percentage, or an edit distance between two identifier values) have result bands, which allow you to configure distinct comparison results (to drive whether or not to match records automatically) for bands of results. Default result bands for each comparison are provided to illustrate this, and so that you do not always have to configure the result bands from scratch.
For example, the following result bands are configured by default for a Character edit distance comparison:

You can change the result bands for a comparison if you want to band results differently. For example, when using a Character edit distance comparison, you might simply want a rule that matches that identifier if the edit distance is 2 or less. In this case, you can change the result bands to the following:

Note also the colors on the right-hand side of each result band. These are used in the Match rules pane (visible with the match processor open on the canvas, and the Match sub-processor selected) to provide a quick guide to the strength of the comparison result, and therefore a quick visual guide to the configuration of each match rule across several comparisons. Use the Invert Colors tick box to change the direction of the colors. Use Green to indicate a strong match, and Red to indicate a weak match, with various gradients in between.
A match rule determines how many comparison results are interpreted during the matching process.
Each match rule results in a decision. There are three possible decisions:
These decisions are interpretations of a number of comparison results - for example if all comparison results match, this might be categorized as a Match. If only some comparisons match, you might prefer to review the matching records manually in order to decide whether records linked by the rule are matches or not.
Match rules are processed in a logical order, from top to bottom as they are displayed in the Match Rules pane. If match rule groups are in use, the match rules in the first match rule group are processed first, from top to bottom, before any of the rules in the next group are processed.
The complete set of match rules form a decision table for the comparison results.
If a pair of records meets the criteria for the top match rule, (for example, Comparison 1 = True, Comparison 2 = Close match), the match rule's decision will be applied to that pair of records. Match rules that are lower down in the decision table will not apply to pairs of records already linked (or not linked, in the case of rules with No Match decisions) by a higher rule.
Normally, it is best to use the strongest match rules (with Match decisions) at the top of the table. For example, a complete duplicate across all identifiers would be considered a very strong (exact) match, and would meet the criteria of the top rule. The match rules will then get 'looser' as you move down the table.
For example, the following initial set of match rules may be set up when matching customers using Name and Post Code identifiers:

The first rule above ("Exact match") matches records where both the Name and Postcode identifiers match exactly. These pairs of values are considered automatic matches.
The highlighted fourth rule above ("Exact name, close postcode") matches pairs of records where the Name matches exactly, and the Postcode matches with a character edit distance of 1. In this case, pairs of records matched by this rule will be reviewed in order to determine if they are matches or not.
After matching has run, the links (termed 'relationships') formed by each match rule are available in the Rules view of the Results Browser, and you can drill down to the Relationships Output to see the related records.
Match rules are managed using the buttons underneath the match rules list:

Rules are added using the plus sign and deleted using the minus sign. Their position in the list is adjusted using the arrow buttons at the right hand side.
The check box to the left of the match rule allows you temporarily to disable a match rule from the next run of the match processor, without losing the rule altogether (as you may wish to reinstate it later). This is particularly useful for pre-configured match processors, as some of the rules provided may not be required for your specific data, and so can quickly be disabled without deleting the rule.
Each match rule is configured on the right-hand side of the dialog. Each comparison is listed, and you need to decide which comparison results you want to interpret with a match decision (MATCH, NO MATCH, or REVIEW).
It is also very useful to create new rules by copying and pasting other rules, and making minor changes to the configuration on the right - for example because you want to create a new rule that varies only slightly from an existing rule. Standard keyboard shortcuts (<Ctrl> C and <Ctrl> V) can be used, and a right-click menu is also available:

The pasted rule will be added immediately below the original rule. You can then edit the rule name, change its configuration, and move it to the appropriate place in the table of rules.
Rules can be copied from one match rule group and pasted into another.
For each configured comparison, it is possible to select a comparison result for the match rule. As different comparisons offer different results, the possible results for a comparison vary. For example, the Exact String Match comparison may return one of the following results:
When selecting the result of the comparison in a match rule, you can therefore choose any of the above results, or you may choose *, meaning 'Any result':

Note that all comparisons offer a 'No data' result. Comparing a value containing data with a Null or empty string value will always give a No data result. Comparing two Null or empty strings gives a No data result only if the Match No Data Pairs option (also on all comparisons) is set to No. If Match No Data Pairs is set to Yes, the two No Data values will be matched with the maximum result for the comparison (for example, True, for the case of an Exact String Match).
Match Rules are collated into groups. A match rule group consists of a set of match rules that perform a similar function. Match rules in a match rule group can be managed as a unit, including:
The rules in a match rule group form a contiguous set of rules in the decision table. That is, for any given group, it is not possible for rules that are not part of the group to be interspersed with the rules in that group. The following screenshot shows an example of a match processor configured using match rule groups:

The match rules displayed are those which are associated with the selected group.
It is possible to ignore match rule groups completely. By default, every match processor has a 'default' match rule group, into which all the match rules are placed. If you do not create any other match rule groups, then grouping will have no effect on the match rule configuration.
Match rule groups are managed in a similar way to the match rules themselves. Again, buttons underneath the list are used to add, remove and reorder the match group rules.
Deleting a match rule group deletes all the match rules within the group.
Bulk changes to the rules in a group can be made via the match rules group right-click menu:
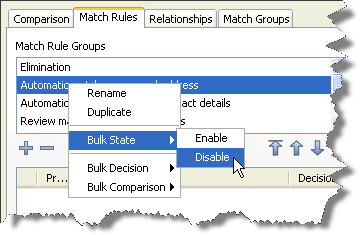
In the example above, all the rules in the selected group are to be disabled. You can also change the match decision of all the rules in a group, or apply a comparison to all the rules in a group, via this mechanism.
The Relationships tab allows you to configure the Relationships output from the matching process.
Relationships are links between two records, created by automatic match rules and manual decisions. The same record may be related to more than one other record, and therefore might exist in more than one relationship, but each relationship is always for a distinct pair of records.
The relationships output is available as an output from each matching processor, and can be used for writing and exporting to an external database or file, or for further processing, such as profiling. It is also available as a Data View in the Results Browser. Finally, it is used in the drilldowns from the Rules and Review Status summary views for a match processor.
The relationships output has a default set of attributes, and a default set of output records (one for each relationship formed in matching). However, you can change the set of attributes that form the output, and you can change the set of relationships to output.
The attributes that make up the default relationships data are listed on the left-hand side of the configuration dialog.
The relationships data outputs a single record for each relationship created by your matching process. Each record in the output data therefore contains information from two matching records.
The default format includes the following attributes by default, as shown on the left-hand side of the screen:
To keep the default format for the relationships output, keep the Auto Attribute Selection option ticked at the bottom of the dialog. Note that the attributes in the output may still change, as attributes are included for each identifier. Adding or removing identifiers will change the attributes in the default output.
If you want to customize the output, you can choose to untick this box, and add or remove attributes. A number of attributes are available to add. You can add values from any of the input attributes to the match process, for either or both records in the relationship, and also a number of additional attributes that are made available from the matching process, such as the REVIEW_USER (the user that made the last manual decision on the relationship, if any), the REVIEW_DATE (the date of the last manual decision), COMMENT (the last comment made on the relationship during the review process), COMMENT_USER (the user that made the last comment) and Case Management Extended Attributes (if Case Management is in use).
Note that if you change the output to a custom format, for example, by adding attributes, the Auto Attribute Selection option is automatically de-selected. This means that adding identifiers will not automatically add attributes to the output, though you can still add them manually if required.
There are a number of options available for changing the set of relationships that are output:
|
Option |
Description |
Default setting |
|
Generate relationships output |
Determines whether or not to generate the relationships output (at all) or not. For example, if you have fully developed the matching process, and you are not using the relationships output, you can save on performance by not generating it. |
Selected |
|
Output match relationships |
Determines whether or not to output relationships with a Match decision |
Selected |
|
Output review relationships |
Determines whether or not to output relationships with a Review decision |
Selected |
|
Output manual no match relationships |
Determines whether or not to output 'relationships' that initially had a Review decision (by automatic rule) but which were given a No Match decision during review. For example, if you want to output a full audit trail of the decisions made during the review process, you might select this option, and de-select the options above. |
Not selected |
|
Match rules to include |
Allows you to select whether or not to output relationships created by individual match rules |
All rules selected |
The Match groups tab allows you to configure the match groups output from the matching process.
Match groups are the final groups of records from the matching process. Each working record that is input to the matching process is output in a match group, possibly with other matched records. The groups consist of records that are related via Match decisions. Groups may contain a single record, if it has not been matched to any others. There is an option whether or not to output these unrelated records (groups of 1).
The match groups output is available as an output from each matching processor. It can be used for writing and exporting to an external database or file, or for further processing, such as profiling. It is also available as a Data View in the Results Browser. Finally, it is used in the drilldowns from the Matching and Match Groups summary views for a match processor.
The match groups output has a default set of attributes, and a default set of output records. However, you can change the set of attributes that form the output, and you can change the set of groups to output.
The attributes that make up the default match groups data are listed on the left-hand side of the configuration dialog.
The match groups data outputs the working records input into the matching process, organized into groups according to the way that they were matched to other records.
|
Note: Records from reference data streams are only included in match groups if they are related to working records. Where a match group contains a single record, that record is always from a working data stream. |
The default format includes the following attributes by default, as shown on the left-hand side of the screen:
|
Attribute Name |
Description |
Attribute Value |
|
|
MatchGroup |
Match Group Id |
The internal Id of the match group that each record belongs to
|
|
|
InternalId |
Internal Record Id |
The internal record Id of each record |
|
|
InputName |
Record's Input Name |
The name of the input data stream for the record |
|
|
MatchGroupSize |
The total number of records in the match group of the record |
||
|
[identifier name] |
Value from identifier: [Identifier name] |
An attribute for each identifier value from the first record in the relationship |
To keep the default format for the match groups output, check the Auto Attribute Selection option at the bottom of the dialog. Note that the attributes in the output may still change, as attributes are included for each identifier. Adding or removing identifiers will change the attributes in the default output.
If you want to customize the output, you can choose to un-check this box, and add or remove attributes. You can add values from any of the input attributes to the match process.
Note that if you change the output to a custom format, for example, by adding attributes, the Auto Attribute Selection option is automatically de-selected. This means that adding identifiers will not automatically add attributes to the output, though you can still add them manually if required.
There are a number of options available for changing the set of match groups that are output:
|
Option |
Description |
Default setting |
|
Generate Match Groups report |
Determines whether or not to generate the match groups output (at all) or not. For example, if you have fully developed the matching process, and you are not using the match groups output, you can save on performance by not generating it. |
Selected |
|
Output related records |
Determines whether or not to output groups of related records. |
Selected |
|
Output unrelated records |
Determines whether or not to output groups of unrelated records. |
Selected, for Deduplicate and Consolidate processors. Not Selected, for Enhance, Link and Advanced Match processors. |
The Alert groups tab allows you to configure the alert groups output from the matching process.
The groups output is available from each matching processor. It can be used for writing and exporting to an external database or file, or for further processing, such as profiling. It is also available as a Data View in the Results Browser. Finally, it is used in the drilldowns from the Matching and Match Groups summary views for a match processor.
Alert groups are the collected sets of records from the matching process form alerts for use in the review process. Each working record that is included in a relationship by the matching process is output in an alert group, possibly with other matched records. The groups consist of records that are related via Alert Key.
Any records which have not been matched to any others will not be included in any alert groups, and will not be assigned an Alert Key. These singleton records can optionally be included in the Alert Groups output.
The alert groups output is pre-configured with a default set of output attributes and a default selection of output groups. These default configurations can be changed on the Alert Groups tab of the Match processor dialog.
The attributes that are output in the alert group data are listed on the left-hand side of the configuration dialog:

Alert groups contain the working records input into the matching process, organized into groups by their Alert Key.
|
Note: Records from reference data streams are only included in alert groups if they are related to working records. |
The default format includes the following attributes by default, as shown on the left-hand side of the screen:
|
Attribute Name |
Description |
Attribute Value |
|
CaseKey |
Case Key |
The Case Key of the records in the alert group. |
|
AlertKey |
Alert Key |
The Alert Key used to collect the records into the alert group. |
|
InputName |
Record's Input Name |
The name of the input data stream for the record. |
|
InternalId |
Internal record ID |
The internal identifier of the record. |
|
MatchGroupSize |
The total number of records in the alert group of the record. |
|
|
[identifier name] |
Value from identifier: [Identifier name] |
An attribute for each identifier value from the first record in the relationship |
To keep the default format for the alert groups output, check the Auto Attribute Selection option at the bottom of the dialog. Note that the attributes in the output may still change, because attributes are included for each identifier. Adding or removing identifiers will change the attributes in the default output.
If you want to customize the output, you can choose to uncheck this box, and add or remove attributes. You can add values from any of the input attributes to the match process.
Note that if you change the output to a custom format, for example, by adding attributes, the Auto Attribute Selection option is automatically de-selected. This means that adding identifiers will not automatically add attributes to the output, though you can still add them manually if required.
There are a number of options available for specifying which alert groups will be output:
|
Option |
Description |
Default setting |
|
Generate Alert Groups report |
Determines whether or not to generate any alert groups output at all. Once you have finished developing the matching process, you can improve the performance of the process by disabling the alert groups output. |
Selected |
|
Output related records |
Determines whether or not to include records which are found in alert groups (that is, they have been matched with other records). |
Selected |
|
Output unrelated records |
Determines whether or not to output records which are not part of any alert groups (that is, they have not been matched with any other records). |
Selected, for Deduplicate and Consolidate processors. Not Selected, for Enhance, Link and Advanced Match processors. |
Oracle ® Enterprise Data Quality Help version 9.0
Copyright ©
2006,2011 Oracle and/or its affiliates. All rights reserved.