Datenmodell
Bei der Datenmodellierung geht es darum, Daten in einer Form darzustellen, die für Geschäftsanwender leicht zu verstehen ist und ihnen Antworten auf ihre Fragen liefert. Die Datenmodellierung erfordert einen zentralisierten Ansatz, um einheitliche Unternehmenskennzahlen zu gewährleisten, sowie einen Selfserviceansatz für Geschäftsanwender, um Daten zur Unterstützung ihrer Datenuntersuchungen zu mischen.
Datenmodellierung
Die Datenmodellierung ist unerlässlich, um einerseits Daten in einer Form bereitzustellen, mit der die meisten erwarteten Geschäftsfragen beantwortet werden können, und um andererseits eine einheitliche Sicht auf alle Unternehmenszahlen zu gewährleisten. Datenmodelle umgehen zudem die Komplexität der physischen Datenspeicherung und bieten den Geschäftsanwendern stattdessen eine für sie sinnvolle Sicht auf ihre Daten. Finanznutzer müssen beispielsweise keine SQL- oder MDX-Abfragesprachen beherrschen, sondern können ein relationales Datenbankmanagementsystem (RDBMS) oder einen Essbase-Würfel mit Hilfe erkennbarer Finanzbegriffe aus ihrem eigenen Lexikon abfragen.
Das Datenmodell ist eine zentrale Stelle für die Definition von Unternehmensberechnungen. Unabhängig davon, wie oder wo diese Berechnungen verwendet werden, bleibt der Wert einheitlich und vertrauenswürdig. Für die Kennzahl „Personalaufwand“ beispielsweise müssten die entsprechenden Quellsysteme korrekt abgebildet und die Berechnung zentral definiert werden. Dann würde jeder Visualisierungs- oder Berichtsprozess, der diese Metrik aufruft, immer dieselbe Zahl melden.
Gesteuertes semantisches Modell
Entwickeln und stellen Sie vertrauenswürdige und gesteuerte semantische Modelle bereit, um eine einheitliche Ansicht geschäftskritischer Daten zu gewährleisten. Ordnen Sie komplexe Daten vertrauten und konsistenten Geschäftsbegriffen zu. Entwerfen Sie eine optimierte, optimierte Abfrage für die Ausführung.
Das semantische Modell besteht aus drei Schichten, beginnend mit der physischen Schicht, die in die logische Schicht übergeht, die wiederum in die Präsentationsschicht mündet. Die physische Schicht bildet die physischen Datenquellsysteme des Unternehmens ab und wird normalerweise von der IT-Abteilung konfiguriert und verwaltet. Die logische Schicht wird verwendet, um geschäftliche Berechnungen, Hierarchien und die Abbildung verschiedener Datenquellen in logischen Berichtsbereichen zu erstellen. So können beispielsweise das ERP-System und das Data Warehouse für den Bereich Finanzreporting gemeinsam abgebildet werden. Die Präsentationsschicht ist die Art und Weise, wie den Benutzern die Attribute und Metriken präsentiert werden, die ihnen zur Erstellung ihrer Analyseberichte zur Verfügung stehen. Während alle Daten einheitlich berechnet werden, wird die spezielle Sicht eines Benutzers auf diese Daten auf der Grundlage seines Sicherheitszugangs und seiner Berechtigung gefiltert.
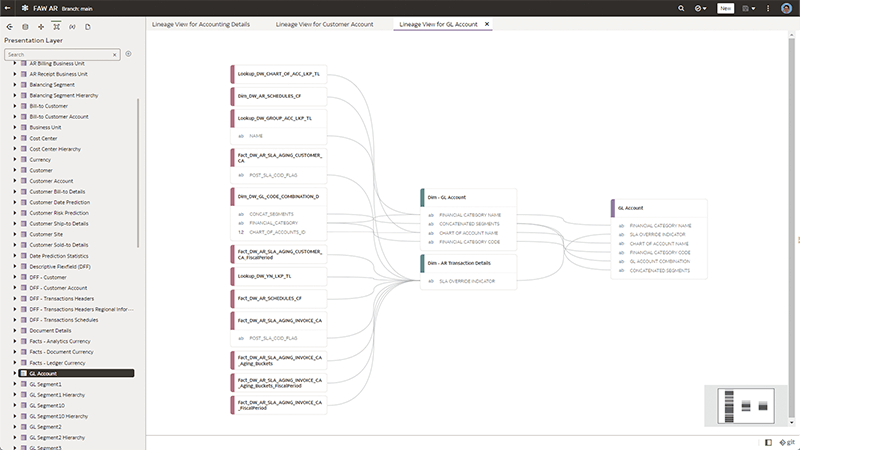
Das semantische Modell ist auch für Visualisierungstools von Drittanbietern (z. B. Tableau, Power BI oder benutzerdefinierte Anwendungen) als JDBC-Quelle sichtbar. Dadurch wird sichergestellt, dass Unternehmensmetriken nur einmal definiert werden müssen und über alle Berichtsplattformen im Unternehmen hinweg konsistent bleiben, auch wenn einige Geschäftsgruppen unterschiedliche Visualisierungstools wählen.
Mehr über die semantische Ebene erfahren
Selfservice-Datenmodellierung
Nutzer können zwei oder mehr Tabellen direkt verknüpfen und die Beziehung (z. B. innere oder äußere Verknüpfungen) selbst steuern. Teilen Sie Selfservice-Datenmodelle ganz einfach mit Kollegen.
Demo eines Multitabellen-Datensatzes ansehen (2:57)

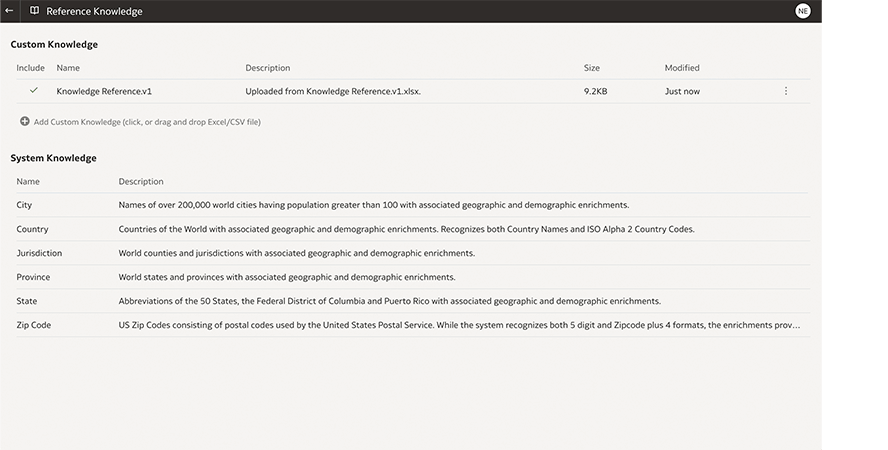
Datenerweiterung und -empfehlungen
Datensätze können durch zusätzliche Daten, Attribute oder Transformationen ergänzt werden. Das eingebaute Nachschlagewerk beinhaltet:
- GPS-Erweiterung:
Bezug auf Breiten- und Längengrad für Städte oder Postleitzahlen. - Referenzbasierte Erweiterungen:
Bestimmen Sie das Geschlecht unter Verwendung des Vornamens der Person als Attribut, das die Geschlechtsentscheidung definiert. - Spaltenverkettungen:
Verknüpfen Sie den Vor- und Nachnamen einer Person in einer Spalte. - Teilextraktionen:
Trennen Sie die Hausnummer von dem Straßennamen in einer Adresse. - Semantische Extraktionen:
Extrahieren Sie Informationen aus einem erkannten semantischen Typ, z. B. die Domäne aus einer E-Mail-Adresse. - Extraktion von Datumsteilen:
Ziehen Sie den Wochentag aus einem Datum heraus, das das Format Monat/Tag/Jahr (oder Tag/Monat/Jahr) verwendet, um die Daten in Visualisierungen nützlicher zu machen. - Vollständige und Teilverschleierung:
Maskieren Sie erkannte sensible Felder, wie Kreditkarten- oder Sozialversicherungsnummern. - Allgemeine Empfehlungen:
Löschen Sie Spalten, die erkannte sensible Felder enthalten. - Benutzerdefinierte Knowledge-Erweiterungen:
Nutzen Sie die benutzerdefinierten Eingliederungen, die der Administrator zu Oracle Analytics hinzugefügt hat.
Semantic Modeler Markup Language (SMML)
Entwickler von Datenmodellen können semantische Modelle mit dem webbasierten grafischen Tool erstellen, bearbeiten und abstimmen. Ein anderer Ansatz ist jedoch die programmatische Änderung von Modellen mit der Semantic Modeler Markup Language (SMML). SMML ist eine JSON-basierte Markup-Sprache, die die Objekte des semantischen Modells zur Entwurfszeit beschreibt. Jede SMML-Datei stellt ein Objekt im semantischen Modell dar. Sie können SMML-Dateien für die Migration von Metadaten, die programmgesteuerte Erzeugung und Bearbeitung von Metadaten, das Patchen von Metadaten und andere Funktionen verwenden. Das bedeutet, dass Entwickler den Code des semantischen Modells direkt bearbeiten oder Änderungen über andere programmatische Prozesse vornehmen können, indem sie einfach textuelle Änderungen direkt an der SMML-Definition vornehmen.

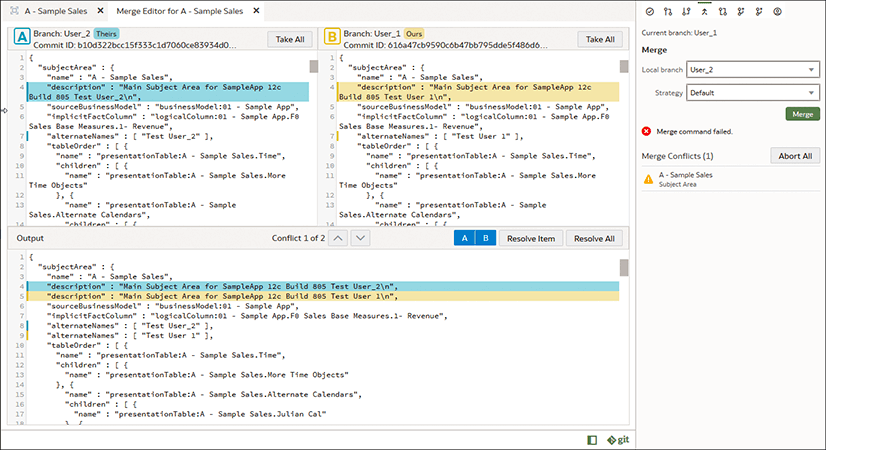
Mehrbenutzer-Modellentwicklung und Git-Integration
Der semantische Modellierer lässt sich mit jedem Git-kompatiblen Repository wie GitHub, GitLab oder Git auf Oracle Visual Builder integrieren, um eine nahtlose, kollaborative, mehrbenutzerfähige Entwicklungsumgebung und Versionskontrolle zu bieten. Die Git-Integration für die Mehrbenutzerentwicklung unterstützt Verzweigungen, Zusammenführungen, Pull- und Push-Operationen und ermöglicht einen vollständigen Einblick in den Lebenszyklus der Entwicklung des semantischen Modells.