ASM – Automatic Storage Management
Por Carlos H. Y. Furushima Revisado por Marcelo Pivovar - Solution Architect ,
Postado em Março 2015
Pequeno Glossário para iniciarmos:
ASM: Automatic Storage Management ASM Diskgroup: É um pool de armazenamento ou unidade ou ponto de montagem que contém uma coleção (1 ou mais) de discos do sistema operacional (exemplo: /dev/sdb). Manager Path: Software que faz o gerenciamento dos devices em sistemas Unix e Linux, tais como EMC PowerPath, DM-Multipath, MPIO, mknod, Oracle ASM support, entre outros. SAME: “Stripe And Mirror Everywhere” - Principio do ASM: sempre tende a distribuir e deixar redundante as "cargas" entre os discos.
1. O que é ASM?
1.1 Overview
Segundo as documentações oficiais, ASM é um sistema de arquivos (File system) e gerenciador de volumes para arquivos do banco de dados da Oracle, tais como controlfile, datafile, parameter file, backupset rman, etc. Está solução é suportável em ambientes Single-Instance e RAC. Nas versões legadas (11gR1 ou inferior) ASM e Clusterware eram coisas distintas, hoje são uma só coisa chamada grid infrastructure. Assim, para ter um ASM em Single-Instance, o Clusterware é instalado e o ASM torna-se um recurso integrado a ele. Porém, não haverá failover de recursos por não existir nodes associados a essa solução (Não é um cluster). Quando tive os primeiros contato com ASM confesso que tive quebrar alguns preconceitos e entender bem a fundo suas vantagens e desvantagens. Concluí que ASM é uma ótima solução sobre 3 condições:
1. Usando sistema operacional Unix
2. Usando um bom "manager path":
Se Unix, recomendo: PowerPath, MPIO, multipath ou mknod. Se Linux, utilizar o manager path e "Oracle ASM support" ou somente OracleASM lib. O problema reside numa possível troca de nomenclatura gerada pelo SO para os discos brutos. Caso aquele que era “/dev/sdc” se tornar “/dev/sdd”, teremos problemas com no startup do ASM.
3. Tendo um bom alinhamento com o storage
Não adianta ter uma separação de diskgroup para Index e Data se, no storage, eles estão em um mesmo array (de disco ou controladora). Uma boa configuração arquitetônica do ASM é intrinsicamente dependente de como os discos estão distribuídos. Afinal, é lá que os blocos serão lidos e escritos. Assim, é de extrema importância conhecimentos básicos em storage e obrigatória a leitura da documentação funcional feito pelo fabricante.
Resumindo: ASM = Gerenciador de Volumes + FileSystem
1.2 Arquitetura e Internals
Componentes do ASM Antes de iniciarmos a explicação de alguns mecanismos de arquitetura é necessário ter o pleno entendimento da relação entre as estruturas de arquivos referente ao banco de dados Oracle e as estruturas do FileSystem ASM.
É denominado Oracle Database, todos os arquivos necessários para o funcionamento do banco de dados, exceto binário de instalação, esses arquivos são:
- Datafile
- Controlfile
- Redo Log File
- Archive
- Parameter File (spfile e/ou pfile)
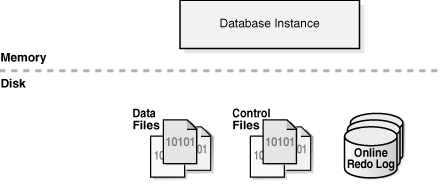
Imagem retirada da documentação oficial da oracle.
É possível armazena-los em quaisquer sistema de arquivo (Homologado pela oracle), cada sistema de arquivo tem sua característica e os arquivos acima citados, são hospedados sobre este sistema de arquivo em função dessas características, que também podemos defini-las como arquitetura de baixo nível do sistema de arquivo. No momento, discutiremos a hospedagem desses arquivos que compõem o Oracle Database sobre o ASM.
Os arquivos que compõem o Oracle Database são armazenados no FileSystem ASM como Oracle ASM File, ou seja, qualquer arquivo que compõem um Oracle Database se transforma em Oracle ASM File a partir do momento em que este foi armazenados no FileSystem ASM. Um Oracle ASM File pertence a um Oracle ASM Disk Group que por sua vez é uma coleção de discos oriundos do sistema operacional, considerado pelo FileSystem ASM como uma unidade de armazenamento.
Com esse entendimento é possível chegar a algumas conclusões:
- Um datafile, controlfile, redo log file e entre outros arquivos é considerado pelo FileSystem ASM um Oracle ASM File sobre um Oracle ASM Disk Group.
- Um Oracle ASM Disk Group é uma unidade de armazenamento do FileSystem, que é composto por 1 ou mais discos oriundo do sistema operacional.
Trecho retirado da documentação oficial: “Oracle Database can store a data file as an Oracle ASM file in an Oracle ASM disk group, which is a collection of disks that Oracle ASM manages as a unit. Within a disk group, Oracle ASM exposes a file system interface for database files.”
Um ASM Disk Group conforme dito anteriormente é composto por 1 ou mais discos oriundo do sistema operacional, o intuito desta estrutura é permitir o funcionamento do mecanismo de Stripe e Mirror, que nos documentações oficiais é citado como método SAME (veremos mais detalhes adiante).
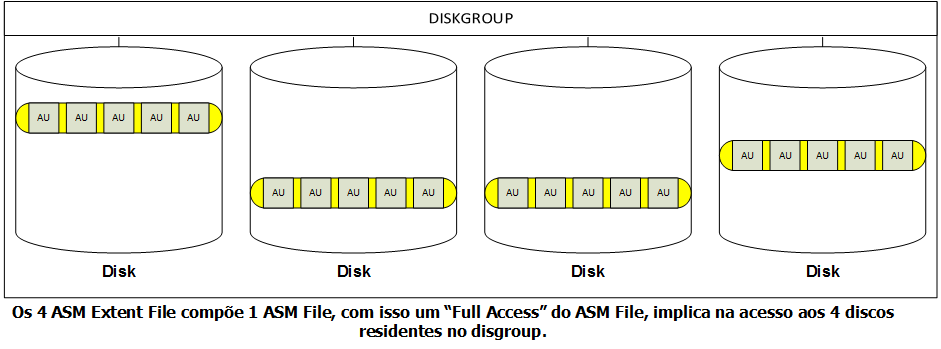
É denominado Oracle ASM Disk, os discos oriundo do sistema operacional que fazem parte de um ASM Disk Group, os Oracle ASM File residem nos discos em forma de pedaços uniformes, denominados Oracle ASM Extents (também conhecidos como ASM Extents Files ou File Extents), adiante veremos que essa estrutura ira orquestrar o mecanismo Stripe e Mirror (Método SAME). Por fim, temos a menor estrutura residente no FileSystem ASM o Oracle ASM Allocation Units, que é uma unidade fundamental de alocação do ASM Diskgroup, ela irá compor um Oracle ASM Extents (também conhecidos como ASM Extents Files ou File Extents).
Com esse entendimento é possível chegar a algumas conclusões:
- Oracle ASM Extents são pedaços uniformes que formam um Oracle ASM File, ele (Oracle ASM Extents) está espalhado sobre todos os Oracle ASM Disk que fazem parte de um Oracle ASM Disk Group.
- A existência do Oracle ASM Extents permite o mecanismo de Stripe e Mirror.

Imagem retirada da documentação oficial da oracle.
Stripe e Mirror
O Diskgroup (DG) é a unidade de armazenamento do ASM. No momento da criação é mandatório a escolha do tipo de redundância (Redundancy), que pode ser: EXTERNAL, NORMAL e HIGH. Estas opções controlam a quantidade de “cópias” que os ASM Files terão distribuído pelos discos. Na verdade, o ASM faz cópias das unidades que compõem os ASM Files. Estas unidades são chamadas de Physical Extents, porém não são a mesma coisa que os “extents” do DB. Daqui para frente, quando falarmos em Extents estamos nos referindo ao ASM.
Na criação do diskgroup define-se também as dimensões do “allocation unit” (AU), que se refere a espessura (uniforme) dos segmentos sobre os discos. Uma coleção de allocation unit (AU) forma o Extent, que por sua vez dá origem a um ASM File.
O valor default do AU é de 1MB e sendo escolhido este, os extents terão tamanho múltiplo de 1MB. Nas versões mais novas, o ASM faz uso de Extents formado por quantidades variáveis de AUs. Esta técnica é especialmente útil para ASM Files muito grandes. Nos primeiros 20000 extents, seu tamanho é igual ao AU. Nos próximos 20000, cada extent terá tamanho de 4*AU e a partir do 40001 será igual a 16*AU.
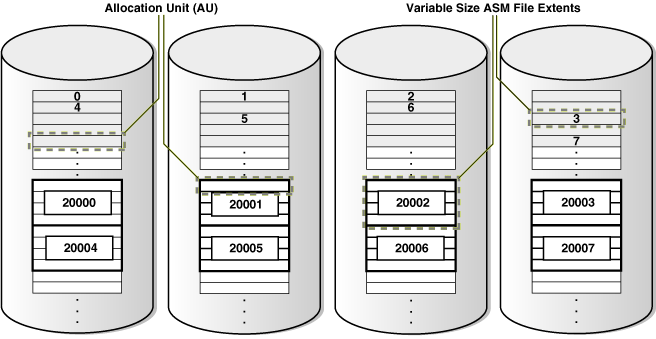
Imagem retirada da documentação oficial da oracle.
Uma outra entidade importante é o Virtual Extent, que são “cópias fieis” de um Physical Extend. Exatamente um espelho! E por isso chamado de Mirror. A existência do Virtual Extent permite que ASM File seja capaz de se reconstruir em caso de perda de um dos Physical Extend.
É importante frisar que se o tipo de redundância for EXTERNAL, o ASM não faz “espelhos” do Physical extent (acreditando que há redundância a nível de hardware) e, por isso, a perda de um disco neste tipo de redundância é fatal!
Obs.: Mesmo em redundância EXTERNAL o Virtual Extent existe, porem o Physical Extend é também um Virtual Extent, não existindo assim o Mirror do extent. (Physical Extend é o Virtual Extent e o Virtual Extent é o Physical Extend)
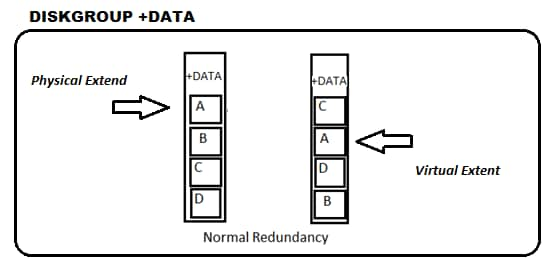
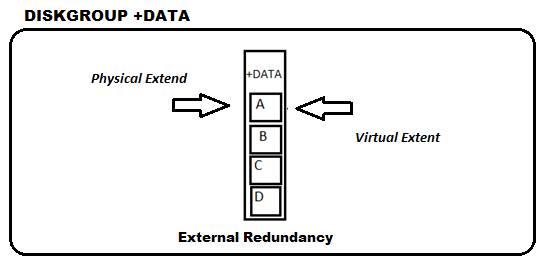
Além das cópias, é possível que o ASM divida a carga (Physical Extend) entre os discos em um DG, se houver mais de um disponível. Desta forma, um DG composto por dois discos terá aproximadamente metade dos extents em cada disco.
ASM Process Segunda a Oracle, é denominado instance, uma área em memória que possui um conjunto de estruturas, afim de gerenciar os database files (arquivos do banco de dados Oracle). Ha dois tipos de instance, são elas:
- Database Instance ou Instance RDBMS
- ASM Instance
Uma ASM Instance é composta pelos seguintes componentes:
1. Processos background básicos
Os mais relevantes são:
- Database writer (DBWn)
- Log writer (LGWR)
- Checkpoint (CKPT)
- System monitor (SMON)
- Process monitor (PMON)
2. Processos background específicos p/ ASM Instance
Os mais relevantes são:
- ASM Background ou ASM Bridge (ASMB)
- ASM Rebalance Master (RBAL)
- ASM Rebalance (ARBn)
3. Estrutura de memoria
- SGA
Os processos background da ASM Instance possui prefixo "asm_", já a database seu prefixo é "ora_", veja um exemplo:
ASM Instance: asm_pmon_+ASM Database Instance: ora_pmon_ORCL
É importante ressaltar que alguns processos existente na ASM Instance, também existem na Database Instance, contudo não necessariamente desempenham a mesma função, analisaremos a seguir os principais processos background que orquestram o funcionamento do ASM.
ASM Background ou ASM Bridge (ASMB) Instance onde atua:
- Somente na Database Instance, em caso de standalone
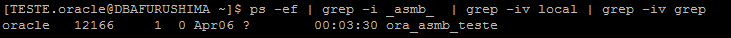
- Em ambas as instance, em caso de RAC

Atividade de atuação:
- Comunicador (Ponte) entre ASM Instance (ASM) e Database Instance (RDBMS).
Detalhes: O processo ASMB é atuante quando é necessário a interação entre ASM Instance (ASM) e Database Instance (RDBMS), com finalidade de gerenciar o armazenamento e fornecer estatística sobre a atividade realizada ou em realização, pode-se citar dois exemplos clássicos desta interação, são eles:
1. Execução do comando cp (copy) disparado sobre o prompt ASMCMD
2. Acesso ao SPFILE do Database Instance (RDBMS) quando o mesmo é armazenado no ASM.
Esta interação se dá pela abertura de uma sessão na instance ASM, cujo responsável pela abertura é o processo background ASMB.
- Standalone

- RAC

ASM Rebalance Master (RBAL)
Instance onde atua:
- Database Instance
- ASM Instance

Atividade de atuação:
- Depende da instance em questão, veremos mais detalhes a seguir
Detalhes: Em parágrafos anteriores, foi ressaltado que alguns processos existente na ASM Instance, também existem na Database, contudo não necessariamente desempenham a mesma função, isso ocorre com o processo background RBAL, este não tem a mesma atividade de atuação na ASM instance e Database instance, ou seja, o processo backup "ora_rbal_SID" não exerce a mesma função do "asm_rbal_SID".
Na ASM Instance o processo background RBAL desempenha uma função de coordenação da atividade de rebalanceamento quando um disco é adicionado ou deletado, ou seja, imediatamente quando um disco é adicionado ou deletado o processo é acionado para traçar um plano de rebalanceamento (movimentação dos ASM File Extents - Strip) com estimativa de tempo e custo de trabalho, este plano deve ser executado pelo também processo background ARBn.
Na Database Instance o processo background RBAL é responsável por acessar o disco do diskgroup (acessar = Abertura e Fechamento - I/O), esta atividade não tem relação com a atividade do processo background RBAL da ASM Instance.
ASM Rebalance (ARBn) Instance onde atua:
- ASM Instance
Atividade de atuação:
- Execução do plano de rebalanceamento traçado pelo RBAL da ASM Instance
Detalhes: O ARBn é um processo "operário" sua função é simplesmente executar um plano de rebalanceamento, que foi arquitetado pelo RBAL da ASM Instance, ARBn sempre atua de forma reativa, ou seja, sua atuação depende de uma ação de adição, deleção ou perda de um disco no diskgroup com isso ele inicia uma movimentação dos ASM File Extents, entre os discos do diskgroup, baseando-se no plano de rebalanceamento traçado pelo RBAL da ASM Instance.
- Na ASM instance ARBn é dependente de RBAL.
- RBAL é responsável pela coordenação das atividades de ARBn.
- ARBn é um processo reativo a uma ação de adição, deleção ou perda de um disco no ASM diskgroup.
Processo de rebalanceamento consiste nos seguintes passos
- Ao adicionar ou remover um disco localizado em um diskgroup uma “trigger action” de balanceamento de ASM Extent File é acionada.
- Processo RBAL é acionado para criar um plano de rebalanceamento a ser executado e coordena-lo.
- RBAL entrega um plano de rebalanceamento, com estimativa de tempo e custo de trabalho para ARBn executar as atividades.
- Os metadados são atualizados para refletir uma atividade de rebalanceamento.
- Cada ASM Extent File a ser realocado é atribuído a um processo ARBn.
- O ASM Extent File é lockado, movido (realocado de disco ou posição no disco) e deslockado pelo processo ARBn.
2. Por que usar ASM?
Nos momentos em que tenho oportunidade em fazer trocas de entendimento com outros DBAs, percebo que alguns tem certa resistência ao ASM, assim como tive um dia, e os motivos são: a complexidade e o desconhecimento. Vejamos o caso do conceito de rebalanceamento, que parece ser simples, embora eu não ousasse fazer esta afirmação. Não é raro ver alguém associando o balanceamento ao tipo de redundância do diskgroup. Há uma relação de dependência, mas, por exemplo, redundância EXTERNAL não implica não existir rebalanceamento. Tive oportunidades de acompanhar do zero implementações de storages (fisicamente e logicamente) e notei que o ASM tem certa peculiaridades em seus conceitos, tais como diskgroup, mirror, striping. Do lado storage, se tomarmos como base alguns disponíveis no mercado, é possível perceber que tais conceitos são tratados de forma nem sempre equivalente. Portanto, acredito que o ASM veio com o propósito de transparecer a relação entre os discos apresentados para o host e o Storage. E assim, fica evidente que o ASM tem grandes benefícios para o banco de dados Oracle.
Principais vantagens quando usamos ASM: 1. Permite stripe dos dados sobre os discos contidos no Diskgroup. Nada mais que distribuir os dados entre os discos de um DG visando divisão de carga. 2. Permite a adição e remoção de discos em tempo de execução (Online), uma vez que o rebalanceamento (movimentação de dados afim de distribuir os blocos entre todos os discos pertencente ao diskgroup) é implícito nessas 2 operações. Imagine que você tenha um diskgroup com 2 discos e 300GB de dados cada e redundância EXTERNAL. Caso você adicione um novo disco ao DG, o ASM se encarrega de distribuir os 600GB entre os 3 discos, ficando agora com 200GB cada. Se você removesse um dos discos da nova configuração, o rebalanceamento novamente faria com que tivéssemos 300GB em cada disco. Veremos este exemplo a frente na “migração por balanceamento”. 3. Permite mirror em 2 níveis de redundância. Forma de manter seus dados “espelhados” em mais de um disco. Vale enfatizar que o mirror do ASM não é a mesma coisa que o do RAID.
O método SAME Resumidamente é uma combinação de um mecanismo de distribuição linear de cargas entre os discos e um mecanismo de proteção das cargas por meio de técnica de espelhamento. (Stripe And Mirror Everywhere)
A técnica de stripe consiste em um princípio de engenharia, denominada "distribuição linear de cargas". Quando exercidas forças sobre uma estrutura, nenhuma parte deveria sofrer mais que outra, em uma situação normal de trabalho. No ASM, a “carga” em questão são os Extents. Na prática, a técnica de stripe consiste na distribuição dos ASM Extent linearmente sobre todos os discos residentes no DG, com isso as operações de escrita e leitura (operação de I/O) não se concentram em um único ponto. A técnica de stripe é feito sobre um diskgroup, que possui uma coleção de discos (1 ou mais ASM Disk), na criação deste diskgroup é definida uma unidade de medida denominada allocation unit ou AU, esta refere-se a uma espessura uniforme localizada sobre os discos do diskgroup, uma coleção de allocation unit (AU) forma o ASM Extent Files, que por sua vez da vida a um ASM File, assim, uma coleção de ASM Extent Files, forma um ASM File.
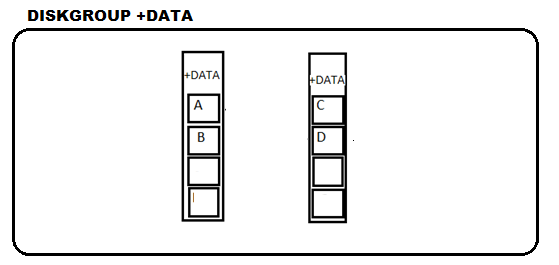
Exemplificando: O diskgroup +DATA é formado por N ASM Disk são eles /dev/xxxx , /dev/yyyy e /dev/zzzz, a unidade de medida allocation unit tem a espessura de 1MB (1MB é o default), a coleção de allocation unit (1 ou mais) forma ASM Extent Files, que estão distribuídos sobre os ASM disk do diskgroup, garantindo a técnica de stripe, que finalmente da vida a um ASM File +DATA/datafile/undo.432.8728123929 .

Com base nisso, pode-se concluir que as operações de I/O aplicado ao diskgroup, consiste no acesso a todos os discos, evitando possíveis stress sobre um ponto da estrutura. Imaginemos que uma operação de leitura ocorra sobre um disco para recuperação de blocos de um datafile e uma operação de escrita esteja ocorrendo neste mesmo disco, neste caso o throughput I/O será intenso sobre esse disco, o stripe evita essa situação, se os ASM Extent Files estão distribuídos, isso quer dizer que um ASM File está espalhado sobre todos os disco, contudo caso ocorra uma "leitura full" de um datafile é necessário acessar todos os discos, o que evita uma força sobre um único ponto.


Agora, vamos explicar essa frase: Para existir um qualquer situação onde o conceito de redundância se faz presente é necessário uma "referencia" que constrói o cenário de redundância (o que contingenciar), ou seja, é necessário 2 respostas para 2 perguntas:
1. O que será redundante?
2. O que espelhar para atingir o objetivo (a redundância)?
Essa pergunta, deve ser respondia com base na frase retirada do asmca, "a redundancy é obtida através do armazenamento de múltiplas cópias dos dados em diferentes failure groups".
O que será redundante?
- R: Os dados (ASM File Extent)
O que espelhar para atingir o objetivo (a redundância)?
- R: Múltiplas cópias dos dados (mirror do ASM File Extent)
Diferentemente do RAID, onde a referência que constrói o cenário de redundância é o disco, no ASM é os dados, ou seja a referência que constrói o cenário de redundância é o mirror (copias ou espelhos) dos ASM Extent Files, em outras palavras haverá um Physical extent file (original) e uma cópia em caso de perda esta denominada Virutal extent file.
Com essa explicação é possível tirar uma conclusão:
Se haver uma redundância é possível retirar fisicamente um disco da storage que pertence ao ASM.
Desta forma, faz sentido pensar: Se neste disco existisse um Physical extent file, o Virtual extent file assumira seu posto e o ambiente continuará disponível. Se existisse um Virtual extent file, o ambiente continuará disponível.
Conforme citado anteriormente, as cópias redundantes, que titulamos de espelhos ou mirror servem para proteger o diskgroup caso uma perda ou falha de um disco aconteça. A referência do cenário de redundância no ASM é o mirroring dos ASM Extent Files, conforme abordado nos últimos parágrafos. Baseado nisso, a configuração de um diskgroup com tolerância a falha (Redundancy NORMAL ou HIGH) é feita com base no que chamamos de Failure Group (FG).
Os Fail Groups são “pontos” que compartilham um risco de falha. Pode ser um disco, uma controladora ou mesmo um storage. No caso mais simples, de redundância NORMAL, um diskgroup formado por dois discos, cada disco é um ponto sujeito a falha.
Este conceito só é claramente entendido quando o DBA consegue ter um visibilidade clara da infra-estrutura. Sem isso, esse conceito pode ser aplicado de forma errada ou desnecessária, portanto a criação do DiskGroup deve ser casado e bem alinhado com a infra-estrutura dos discos apresentados para sua criação.
Um exemplo de criação de diskgroup especificando os FailGroups:
CREATE DISKGROUP data NORMAL REDUNDANCY
FAILGROUP controller1 DISK
'/devices/diska1' NAME diska1,
'/devices/diska2' NAME diska2,
'/devices/diska3' NAME diska3,
'/devices/diska4' NAME diska4
FAILGROUP controller2 DISK
'/devices/diskb1' NAME diskb1,
'/devices/diskb2' NAME diskb2,
'/devices/diskb3' NAME diskb3,
'/devices/diskb4' NAME diskb4
ATTRIBUTE 'au_size'='4M',
'compatible.asm' = '11.1',
'compatible.rdbms' = '11.1';
Quando o ASM Diskgroup é criado com redundância do tipo NORMAL isso significa que o ASM File está protegido contra falhas na camada ASM, de modo que os ASM file extents são espelhados em: Physical extents (copia original primaria) residentes no Failure Group controller1 e Virtual extent (copia redundante secundária) residentes no Failure Group controller2. Os Failure Group são os pontos de falha definidos e com isso o próprio ASM decide em que disco do Failure Group estará os Physical extents e Virutal extent, mas certamente estarão em Failure Group distintos.

Mesmo que não se defina os Failure Group (FG), o ASM automaticamente os cria: 1 FG para cada disco. É importante sempre observar:
- Cada disco em um DG pode pertencer a apenas um FG.
- Failure Group (FG) devem ser do mesmo tamanho (independentemente do número de discos). Com tamanhos diferentes podem comprometer a disponibilidade.
- ASM precisa de pelo menos 2 FG para um DG de redundância NORMAL e pelo menos 3 para HIGH.
- Em cenários de RAC extended cluster, o uso do Failure Group (FG) é vital para o funcionamento da solução.
Este (Failure Group) define referência delimitadora entre Physical extent e Virutal extent. Segunda a Oracle, o Failure Group é um subconjunto dos discos de um diskgroup que, em caso de falha não deve provocar a queda do diskgroup, ou seja, o diskgroup é tolerante quanto a uma possível perda deste subconjunto dos discos.
Portanto, se tivermos uma Redundancy Normal com 2 Failure Group, denominados de A e B, o ASM decidirá em qual Failure Group o Physical extent estará, feito isso o Virtual extent estará no Failure Group oposto ao Physical extent.
- Physical extent no Failure Group A
- Virtual extent no Failure Group B
Em caso de um Redundancy High é necessário 3 Failure Groups (A, B e C), tendo 2 copias espelhadas do Physical extent, ou seja, Virtual extent primário e Virtual extent secundário.
- Physical extent no Failure Group A
- Virtual extent no Failure Group B
- Virtual extent no Failure Group C
Exemplo: Se neste disco estiver um Physical extent file, o Virutal extent file assumira seu posto e o ambiente continuará disponível. Se neste disco estiver um Virutal extent file, o ambiente continuará disponível.
Resumindo a parte de Redundancy: Atualmente o oracle asm suporta 3 tipos de redundância
- External
Neste tipo de redundância você assume que a redundância do seus dados está sendo feita de forma externa, ou seja, no storage. (RAID 1, 5, 10 ...)
- Normal
Neste tipo de redundância 1 cópia do file extent original (Physical extent) é mantida no Failure Group oposto ao que hospeda o file extent espelho (Virtual extent). Este tipo de redundância é para implementação de RAC Estendido (Oracle RAC on Extended Distance Clusters). O uso de CPU é mais intenso que o normal, devido ao trabalho de mirroring e striping.
- High
Neste tipo de redundância 2 copias do file extent original (Physical extent) é mantida em 3 Failure Group, 1 para o file extent original (Physical extent), 1 para o file extent mirror primário (Virutal extent primário) e 1 para o file extent mirror secundário (Virutal extent secundário)
Esses tópicos são encontramos de forma similar em outros blogs ou mesmo na documentação oficial, mas para entendermos plenamente cada um, vamos levá-lo para situações práticas.
Abordagem 1) É melhor ter os datafiles residentes em 1 só disco ou tê-los segregados?
Se os datafiles estão em um só disco, entraremos em um situação a qual o throughput de I/O (quantidade de dados processados em um determinado espaço de tempo) é mais intenso, ou seja, haverá muitos dados sendo escritos em um mesmo destino e também muitos sendo lidos em uma mesma origem.
- Escrita - Gravação de dados oriundo da memória principal
- Leitura - Transmissão de dados oriundo do disco para memoria principal
Conclusão: Neste cenário, haverá uma intensidade de leitura e gravação concentrados em 1 único disco ou array de disco.
Resultado: Gargalo do mecanismo de I/O
Possíveis soluções:
1. Aumentar a quantidade de memória principal do host, reduzindo ou evitando algumas leituras físicas (Physical Reads - Acesso a disco e envio de blocos de dados para memoria) e as convertendo para leituras lógicas (Logical Reads - Acesso ao buffer cache do Oracle). Com isso a demanda ou trabalho requisitado ao disco diminuirá, com relação a escrita, não teríamos ganho.
2. Aumentar a quantidade de cache memory da controladora do storage, se possível (alguns são engessados quanto a isso). Há storages que utilizam de métodos de assincronismo para gravação. O host conectado a ele envia uma requisição de escrita, dos blocos a serem armazenados, estes são enviados (transportado) até o cache memory da controladora. Neste ponto é feita a confirmação de recebimento e para o solicitante a escrita está concluída. Contudo, internamente no storage outro processo se inicia, o arquivamento desses blocos recebidos para discos propriamente dito, seja ele mecânico ou SSD. [A computação clássica define essa técnica como "assincronismo sobre múltiplas camadas"]
3. Em engenharia, a construção de uma estrutura, seja ela qual for é imprescindível a distribuição linear de cargas (nenhuma parte desta estrutura pode sofrer mais que a outra em uma situação normal de trabalho (força sobre a estrutura)), a aplicação deste princípio produz um equilíbrio geométrico da estrutura em questão. Trazendo essa realidade a estrutura do storage analisaremos a distribuição de cargas entre os discos e controladoras, ou seja, é possível fazer uma fragmentação da atividade de I/O entre os discos e as controladoras disponíveis ("dividir para conquistar").
"Dividir para conquistar - Consiste em ganhar o controle de um lugar através da fragmentação das maiores concentrações de poder, impedindo que se mantenham individualmente. O conceito refere-se a uma estratégia que tenta romper as estruturas de poder existentes e não deixar que grupos menores se juntem."
Na abordagem em questão, a distribuição linear de cargas é denominada Striping ou Stripe (dependendo da colocação verbal na frase), com isso o equilíbrio geométrico da estrutura ASM se faz presente, ou seja, os blocos contido no diskgroup é distribuído entre todos os discos residente nele. Esse cenário só é vantajoso, caso o número de disco visíveis no ASM Diskgroup corresponda fisicamente na storage como um disco propriamente dito, por exemplo:
Disco /dev/sdb no unix seja um disco físico na storage e não uma partição avulsa de um disco físico.
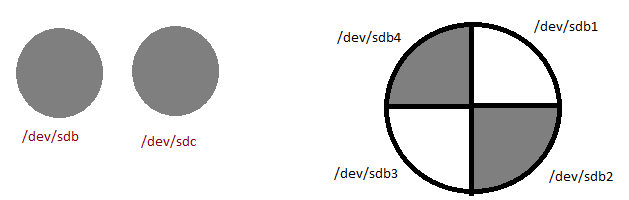
Lembre-se, a atividade real de I/O está no storage e não no ASM, não adianta de nada o ASM ter 500 discos e no storage esses 500 disco visíveis, representar 1 disco com 500 partições, neste caso não haverá balanceamento.
Resumindo: A atividade de striping deve ser bem alinha com a estrutura do storage.

O desenho mostra de forma genérica, uma possível estrutura ASM x Storage, no contexto é possível visualizar um diskgroup (+DATA) com uma coleção de 9 discos associados, veja que na camada do ASM, não é possível ter uma visibilidade clara da estrutura existente no storage (Local onde efetivamente vai ocorrer o I/O). Na camada de storage as LUNs foram distribuídas entre as controladoras existe (3 no caso), isso permite o stripe entre as LUNs (de 1 a 9) e o balanceamento de carga sobre as controladoras existentes no storage.
Caso tivermos somente 1 controladora o risco de gargalo da "queue I/O" (fila de requisição de I/O da controladora) é grande, em sistemas do tipo I/O bound (sistemas com leitura e escrita intensa) a formação de "queue I/O" é natural, devido ao fato do disco sempre ser a parte mais lenta do sistema computacional, contudo é possível diminuir o tamanho da “queue I/O”, paralelizando o atendimento das requisições de I/O (como é feito nos caixa de supermercado), ou seja, distribuindo os discos apresentados para o ASM em diversas controladoras (Dividir para conquistar), no exemplo é possível atender 3 requisições de I/O ao mesmo tempo, é obvio que o acesso ao disco mecânico ou solido (SSD) é feito de forma serial (se 2 controladora requisitar dados do mesmo disco a recuperação é feita de forma sequencial, primeiro um depois o outro), contudo diversos mecanismos é beneficiado nesta arquitetura como por exemplo o uso de cache (se dados estiverem em cache não é necessário o acesso ao disco, neste cenário temos 3 áreas de cache) e escritas assíncronas.
Vantagem destas implementação:
- Maior flexibilidade para em caso de reconfiguração ou manutenção do storage ou ASM.
- Eficiência na realocação dos ASM File Extent em caso de rebalanceamento do ASM
- Eliminação de tuning manual no storage em situação de lentidão.
Abordagem 2) O ASM é uma poderosa ferramenta de transporte de dados entre estruturas físicas. Essa abordagem é pouco confusa: como um filesystem pode ser uma ferramenta de transporte de dados? A explicação técnica é simples!!! A atividade de striping no ASM, nada mais é que a distribuição do total de blocos existentes no ASM Diskgroup sobre todos os discos, sob seu domínio, esse fenômeno é denominado balanceamento (balancear os blocos existentes entre os discos existentes).
Cenário: DiskGroup +DATA (disco 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 oriundo do storage A)
1. Vou adicionar 10 discos oriundos do storage B 2. O processo de balanceamento é implicitamente iniciado. Assim o total de blocos existente no Diskgroup, antes era dividido entre 10 discos oriundo do storage A, com a adição dos novos discos, os blocos existente no Diskgroup passa a ser distribuído entre 20 discos, onde 10 são oriundo do storage A e 10 oriundo do storage B.
Agora temos: DiskGroup +DATA (Disco 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 oriundo do storage A) (Disco 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 oriundo do storage B)
3. Vou dropar 10 discos oriundos do storage A 4. O processo de balanceamento é implicitamente iniciado. Assim o total de blocos existente no Diskgroup, antes era dividido entre 20 discos oriundo do storage A e B, com a deleção dos 10 discos, os blocos existente no Diskgroup passa a ser distribuído entre 10 discos oriundo do storage B. 5. Dados migrados entre os storages
O que ocorre na adição? Os dados e metadados do asm é distribuído igualmente entre todos discos (incluindo o adicionado), ou seja, é feito um cálculo matemático baseado em algoritmos heurísticos para divisão dos blocos de dados e metadados, o objetivo é a equalização da divisão dos blocos, agora com o novo disco pertencente ao diskgroup.
O que ocorre na deleção? Os dados e metadados do ASM está distribuído igualmente entre todos os discos, ao fazer o drop de um disco, este não é eliminado instantaneamente, pois caso isso ocorra com certeza haverá perda de dados, a solução para isso é dividir o drop em 2 passos:
1. Re-balanceamento dos blocos de dados e metadados tendo em base a quantidade total de disco menos 1 disco (devido ao drop), por exemplo, 58333 blocos divididos entre 20 discos, com a deleção de 1, o rebalanceamento deve refazer a distribuição onde 58333 blocos divididos entre 19 discos. 2. Exclusão do disco marcado para ser dropado do ASM Diskgroup, após o re-balanceamento.
Exemplo prático de migração por balanceamento Em /proc/scsi/scsi é possível visualizar os devices atachados no host, existe 2 storages ligados no host, o destacado em vermelho é um storage "IET Virtual-Disk", já o verde é um "OPNFILER Virtual-Disk".
Importante:
- No storage "IET Virtual-Disk" existe 2 LUNs apresentadas 01 e 02
- No storage "OPNFILER Virtual-Disk" existe 1 LUN apresentada 00
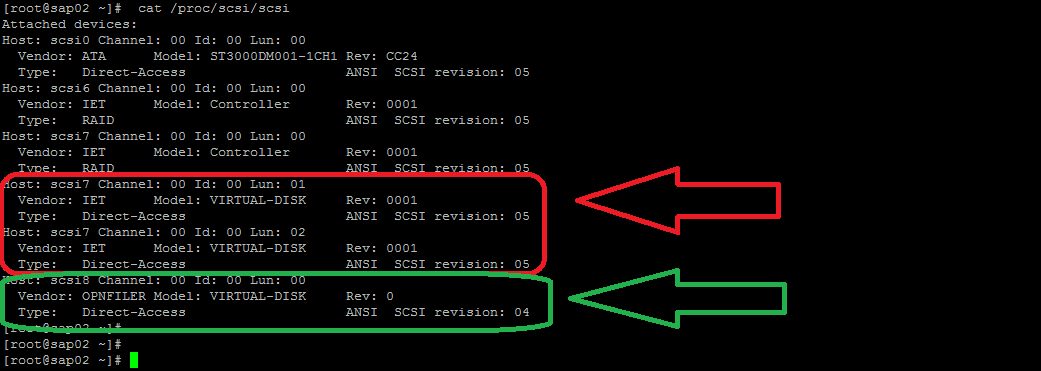
No fdisk é possível verificar os devices já reconhecidos.

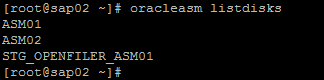
Os discos ASM01 e ASM02 pertencem a storage "IET Virtual-Disk", já o disco STG_OPENFILER_ASM01 pertence a storage "OPNFILER Virtual-Disk”.
Na instance no +ASM é possível ter uma visibilidade dos discos existentes e em qual estrutura de Diskgroup ele pertente.
O disco /dev/oracleasm/disks/ASM02 pertence a um diskgroup (não sabemos qual, pois não é possível saber nesta view), seu nome para o ASM é DATA_0001, já o disco /dev/oracleasm/disks/ASM01 não pertence a nenhuma estrutura de diskgroup, ele está disponível para ser adicionado a qualquer estrutura de diskgroup.
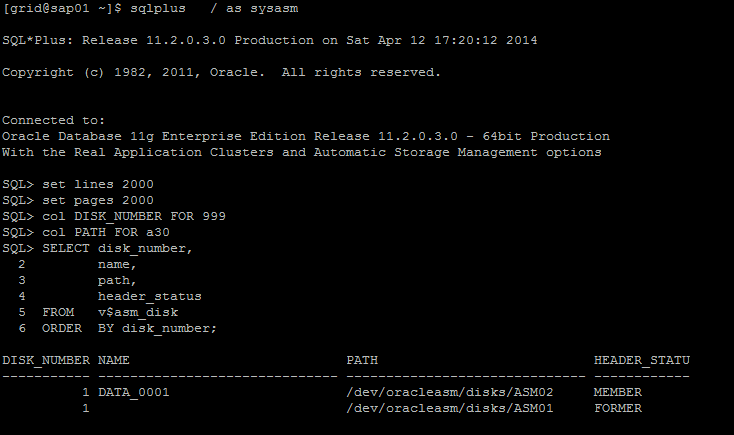
Nesta query é possível visualizar uma intersecção entre discos e diskgroup, por meio de um sql join entre v$asm_diskgroup x v$asm_disk
No utilitário ASMCA é visível o diskgroup, cujo nome é DATA e está montado nos 2 nodes do RAC (MOUNTED 2 of 2)

No utilitário ASMCA vou adicionar o disco da storage "OPNFILER Virtual-Disk", o disco está localizado em /dev/oracleasm/disks/STG_OPENFILER_ASM01, vou chama-lo de OPENFILER_DISK01, ele possui um tamanho de 149597 MB.




Após adicionado o processo de balanceamento é implicitamente iniciado com grau de potência definida no parâmetro asm_power_limit, que por default é 1, a escala é de 1 até 11.
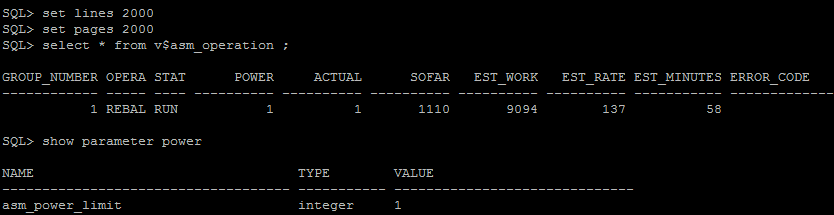
Se quisermos aumentar o grau de potência é possível, mas isso pode causar uma lentidão momentânea, devido à grande intensidade de I/O provocado por esta ação. Essa potência nada mais é que o número de processos background ARBn trabalhando em paralelo, sob supervisão do processo background RBAL (da instance ASM).
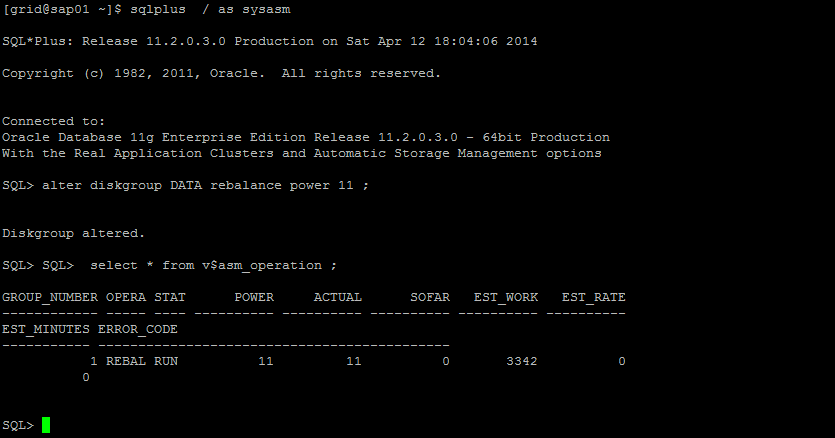
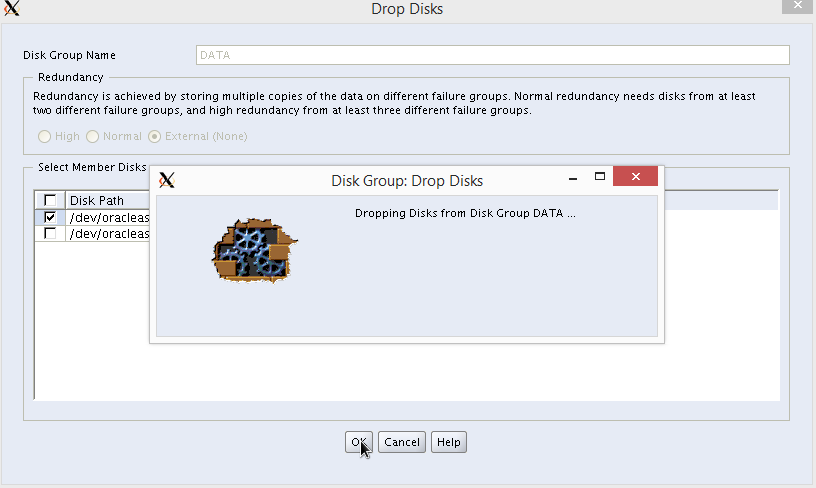
Ao terminar o balanceamento após a adição do disco OPENFILER_DISK01, que está localizado no storage "OPNFILER Virtual-Disk”, vamos deletar o disco DATA_0001, que está localizado no storage "IET Virtual-Disk". Este processo consiste em 2 ações por parte do ASM, são elas:
1. Re-balanceamento dos blocos de dados e metadados tendo em base a quantidade total de disco menos 1 disco (devido ao drop), ou seja, total de blocos divididos entre 2 discos (1 da storage IET Virtual-Disk e 1 da storage OPNFILER Virtual-Disk), após a deleção de 1 disco da storage IET Virtual-Disk, o rebalanceamento deve refazer a distribuição dos blocos, agora em um único disco da storage OPNFILER Virtual-Disk, cujo seu nome é STG_OPENFILER_ASM01.
2. Exclusão do disco marcado (DATA_0001 da storage IET Virtual-Disk), agora não mais pertencente ao ASM Diskgroup +DATA, após o re-balanceamento.



Abordagem 3) Como usar o ASM em RAC estendido
A tecnologia de cluster database da oracle, Real Applications Clusters ou RAC, possui 2 vertentes de implementação, são elas:
- Oracle Real Applications Clusters (RAC) : Single physical datacenter (Nodes em 1 DC)
- Oracle RAC on Extended Distance (Stretched) : Multiple physical datacenter (Nodes em multiplos DC + 3rd Site)
Abordaremos o uso do ASM em RAC estendido (Oracle RAC on Extended Distance), o mecanismo de stripe permite a distribuição dos ASM File Extent entre os storages residentes em cada site (physical datacenter) e o mecanismo de mirror permite o redundância dos ASM File Extent entre os storages residentes em cada site (physical datacenter), o uso do Failure Group é vital na implementação do RAC estendido.

O grande segredo da implementação é a criação do(s) Diskgroup(s) usando(s) pelos arquivos de banco de dados, tais como:
- Datafile
- Controlfile
- Parameter File
- Redo Log Files
E a criação do diskgroup usado pelos arquivos de cluster:
- Votedisk
- OCR
Como deve ser criados os diskgroups para os arquivos de banco de dados:
- Tipo de redundância Normal.
- 2 Failure Group, onde o Failure Group represente 1 storage de cada site.
CREATE DISKGROUP DATA NORMAL REDUNDANCY
FAILGROUP STORAGE_A1 DISK
'/dev/asm_disk01_siteA' NAME diska1,
'/dev/asm_disk02_siteA' NAME diska2,
'/dev/asm_disk03_siteA' NAME diska3,
'/dev/asm_disk04_siteA' NAME diska4
FAILGROUP STORAGE_B2 DISK
'/dev/asm_disk01_siteB' NAME diskb1,
'/dev/asm_disk02_siteB' NAME diskb2,
'/dev/asm_disk03_siteB' NAME diskb3,
'/dev/asm_disk04_siteB' NAME diskb4
ATTRIBUTE 'compatible.asm' = '11.2.0.0.0';
Este comando é um exemplo para criar um DG para arquivos de banco de dados, no exemplo um diskgroup chamado DATA com redundância NORMAL que possui 2 FAILGROUP, que representa 2 storage (1 em cada site).
Como deve ser criados os diskgroups para os arquivos de cluster:
DG PARA VOTEDISK
- Tipo de redundância Normal.
- 2 Failure Group, onde o Failure Group represente 1 storage de cada site.
- 1 Quorum Failure Group para representar o 3rd site
CREATE DISKGROUP VTDISK NORMAL REDUNDANCY
FAILGROUP STORAGE_A1 DISK
'/dev/asm_disk01_siteA' NAME Votedisk01
FAILGROUP STORAGE_B2 DISK
'/dev/asm_disk01_siteB' NAME Votedisk02
QUORUM FAILGROUP 3rd_site DISK
'/votedisk/quorum_disk.vtd' NAME QUORUM_DISK
ATTRIBUTE 'compatible.asm' = '11.2.0.0.0';
DG PARA OCR
- Tipo de redundância Normal.
- 2 Failure Group, onde o Failure Group represente 1 storage de cada site.
CREATE DISKGROUP OCR NORMAL REDUNDANCY
FAILGROUP STORAGE_A1 DISK
'/dev/asm_disk01_siteA' NAME OCR01
FAILGROUP STORAGE_B2 DISK
'/dev/asm_disk01_siteB' NAME OCR02
ATTRIBUTE 'compatible.asm' = '11.2.0.0.0';
Referência bibliográficas:
- a/tech/docs/technical-resources/extended-oracle-rac-clusters.pdf
- //docs.oracle.com/cd/B28359_01/server.111/b28281/architectures.htm#CIHGJEFI
- //uhesse.com/2013/09/20/purpose-of-the-voting-disk-for-oracle-rac/
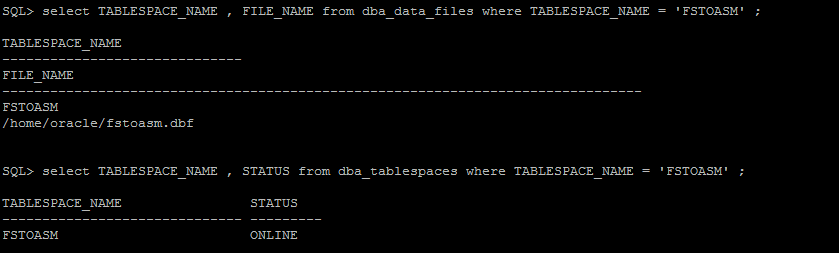
Abordagem 4) Como migrar datafiles entre ASM - Filesystem e Filesystem - ASM
- Transporte de datafile em File System para ASM (File System to ASM) via RMAN
- Criar uma tablespace de teste chamada FStoASM
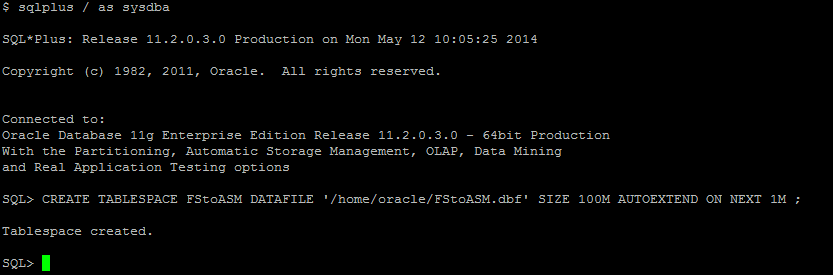
- Verificar status da tablespace e path do(s) datafile(es) correspondentes a ela
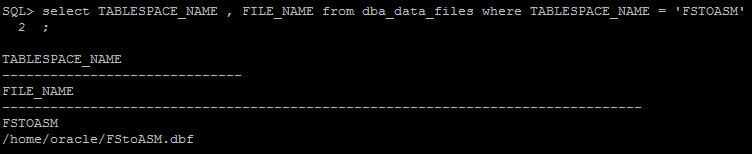
- Alterar status tablespaces para OFFLINE
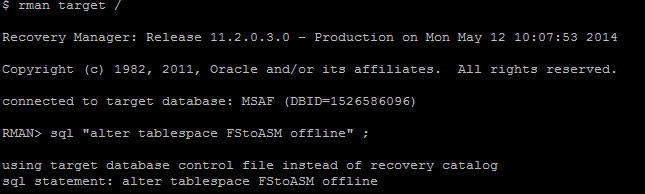
- Executar “copy datafile” via RMAN
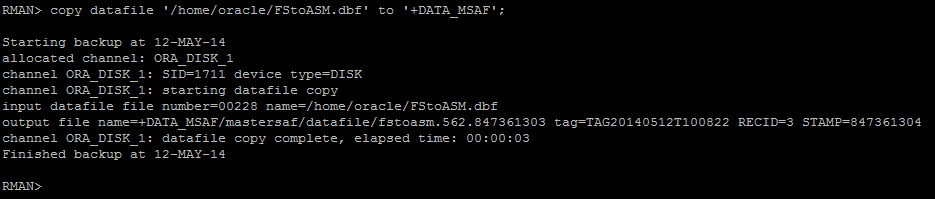
- Alterar o path do datafile no controlfile

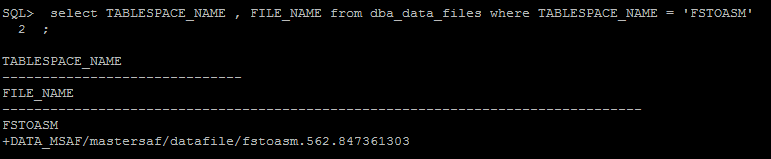
- Alterar status tablespaces para ONLINE










- Transporte de datafile em ASM para File System (ASM to File System) via ASMCMD (11gR2 Somente)
- Criar uma tablespace de teste chamada FStoASM

- Alterar status tablespaces para OFFLINE

- Verificar status da tablespace e path do(s) datafile(es) correspondentes a ela
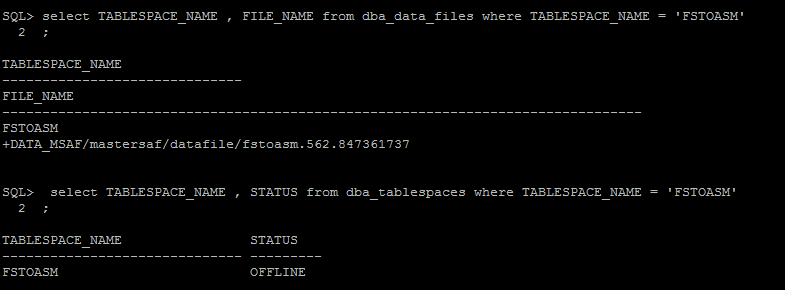
- Executar cp do datafile via ASMCMD

- Alterar o path do datafile no controlfile

- Alterar status tablespaces para ONLINE

- Validação







Referência bibliográficas:
- //docs.oracle.com/cd/E11882_01/server.112/e40540/physical.htm#CNCPT88986
- //oraclehariprasathdba.blogspot.com.br/2013/02/oracle-asm-storage-components.html
- //asmsupportguy.blogspot.com.br/2010/04/about-asm-allocation-units-extents.html
- //books.google.com.br/books?id=QFUXb4Vs54QC&printsec=frontcover&hl=es
- //docs.oracle.com/cd/B28359_01/server.111/b31107/asmcon.htm#OSTMG036
- //www.dba-oracle.com/t_asm_allocation_units.htm
- //hongwang.wordpress.com/2011/09/21/asm-mirroring/
- //docs.oracle.com/cd/B28359_01/server.111/b31107/asmcon.htm#OSTMG036
- //noriegaaoracleexpert.blogspot.com.br/2010/06/asm-load-balancing-anthony-d.html
Carlos H. Y. Furushima é um especialista em banco de dados relacional, trabalhando como consultor de TI, atuando principalmente como o Oracle Database Administrator (DBA Oracle). Tem uma vasta experiência e conhecimento em "Performance, diagnosticand tuning", "High Availability", "Backup & Recovery" e "Exadata". Ele também está entusiasmado com sistema operacional Linux/Unix, onde contribui com o desenvolvimento do código do kernel Linux em parceria com a comunidade "GNU Linux", com criação e revisão de novas funcionalidades, melhorias e correções de bugs. Recentemente, Furushima divide seu tempo com consultoria especializada em banco de dados Oracle e estudos sobre "Oracle Internals", com o objetivo de descobrir e entender os benefícios do bancos de dados Oracle em plataforma Linux/Unix.
Este artigo foi revisto pela equipe de produtos Oracle e está em conformidade com as normas e práticas para o uso de produtos Oracle.