 System Admins and Developers
Hands-On Labs
System Admins and Developers
Hands-On Labs
Oracle Solarisを使用してHadoopクラスタをセットアップする方法
Orgad Kimchi著

Oracle Solaris Zones、ZFS、およびネットワーク仮想化テクノロジーを使用してHadoopクラスタをセットアップする方法
2013年10月公開
|
はじめに
前提条件
システム要件
ラボの演習の概要
Hadoopについて
演習1:Hadoopのインストール
演習2:Hadoop構成ファイルの編集
演習3:Network Time Protocolの構成
演習4:仮想ネットワーク・インタフェースの作成
演習5:ネームノード・ゾーンおよびセカンダリ・ネームノード・ゾーンの作成
演習6:データノード・ゾーンのセットアップ
演習7:ネームノードの構成
演習8:SSHのセットアップ
演習9:ネームノードからのHDFSのフォーマット
演習10:Hadoopクラスタの起動
演習11:MapReduceジョブの実行
演習12:ZFS暗号化の使用
演習13:Oracle Solaris DTraceによるパフォーマンス監視
まとめ
参考資料
著者について
予想される所要時間:180分間
はじめに
このハンズオン・ラボでは、Oracle Solaris Zones、ZFS、ネットワーク仮想化などのOracle Solaris 11のテクノロジーを使用してApache Hadoopクラスタをセットアップする方法を示す演習を提供します。主要なトピックは、Hadoop分散ファイル・システム(HDFS)、Hadoop MapReduceプログラミング・モデルなどです。
Hadoopのインストール・プロセスとクラスタの構成要素(ネームノード、セカンダリ・ネームノード、データノード)についても説明します。また、Oracle Solaris 11のテクノロジーを組み合わせてスケーラビリティとデータ・セキュリティを向上させる方法や、Hadoopクラスタにデータをロードする方法、MapReduceジョブを実行する方法についても説明します。
前提条件
このハンズオン・ラボは、本番環境または開発環境でHadoopクラスタのセットアップやメンテナンスを行うシステム管理者を対象としており、LinuxまたはOracle Solarisシステムの基本的な管理の経験があることが前提となっています。Hadoopに関する予備知識は不要です。
システム要件
このハンズオン・ラボは、Oracle VM VirtualBoxのOracle Solaris 11で実行します。このラボは自己完結型であり、必要なものはすべて、Oracle VM VirtualBoxインスタンスに含まれています。
Oracle OpenWorldでラボに参加する場合は、適切なOracle VM VirtualBoxイメージがラップトップに事前にロードされています。
Oracle OpenWorld以外の場所でこのラボに参加する場合は、Oracle Solaris 11システムが必要です。以下の手順で、マシンをセットアップしてください。
- Oracle Solaris 11をまだインストールしていない場合は、こちらからダウンロードします。
- Oracle Solaris 11.1 VirtualBoxテンプレート(ファイルサイズは1.7GB)をダウンロードします。
- こちらに記載されている手順に従ってテンプレートをインストールします(注:パフォーマンスを高くするには、テンプレートをインストールする際、演習2の手順4でRAMのサイズを4GBに設定してください)。
Oracle OpenWorldの参加者への注意事項
- 各参加者に、ラボ用のラップトップが用意されます。
- このラボのログイン名とパスワードは、要綱に示されています。
- Oracle Solaris 11では、GNOMEデスクトップが使用されます。Linuxまたはその他のUNIXオペレーティング・システムのデスクトップを使用していたのであれば、使い慣れたインタフェースのはずです。ここでは、このインタフェースを初めて使用する場合のために、いくつかの基本的な事柄を簡単に説明します。
- GNOMEデスクトップ・システムでターミナル・ウィンドウを開くには、デスクトップの背景を右クリックし、ポップアップ・メニューから「Open Terminal」を選択します。
- ラボのマシンで提供されるソース・コード・エディタは、vi(ターミナル・ウィンドウで
viと入力)とEmacs(ターミナル・ウィンドウでemacsと入力)です。
ラボの演習の概要
このハンズオン・ラボは、さまざまなOracle SolarisおよびApache Hadoopテクノロジーに関する以下の13の演習で構成されています。
- Hadoopのインストール
- Hadoop構成ファイルの編集
- Network Time Protocolの構成
- 仮想ネットワーク・インタフェース(VNIC)の作成
- ネームノードおよびセカンダリ・ネームノード・ゾーンの作成
- データノード・ゾーンのセットアップ
- ネームノードの構成
- SSHのセットアップ
- ネームノードからのHDFSのフォーマット
- Hadoopクラスタの起動
- MapReduceジョブの実行
- ZFS暗号化による保管データの保護
- Oracle Solaris DTraceによるパフォーマンス監視
Hadoopについて
Apache Hadoopソフトウェアは、シンプルなプログラミング・モデルによってコンピュータの複数のクラスタにわたる大規模データセットを分散処理することを可能にするフレームワークです。
データを格納するために、Hadoopでは、Hadoop分散ファイル・システム(HDFS)が使用されます。HDFSは、優れたスループットでのアプリケーション・データへのアクセスを実現するため、大規模なデータセットを持つアプリケーションに適しています。
HadoopおよびHDFSについて詳しくは、http://hadoop.apache.org/を参照してください。
Hadoopクラスタの構成要素は、以下のとおりです。
- ネームノード:HDFSの中核部分であり、ファイル・システム・メタデータが格納されます。スレーブ・データノード・デーモンに下位のI/Oタスクを実行するように命令します。また、JobTrackerプロセスを実行します。
- セカンダリ・ネームノード:ネームノード・トランザクション・ログの内部チェックを実行します。
- データノード:HDFSでデータを格納するノードです。スレーブとも呼ばれ、TaskTrackerプロセスを実行します。
このラボの例では、Hadoopクラスタのすべての構成要素が、Oracle Solaris Zones、ZFS、およびネットワーク仮想化テクノロジーによってインストールされます。図1は、そのアーキテクチャを示しています。
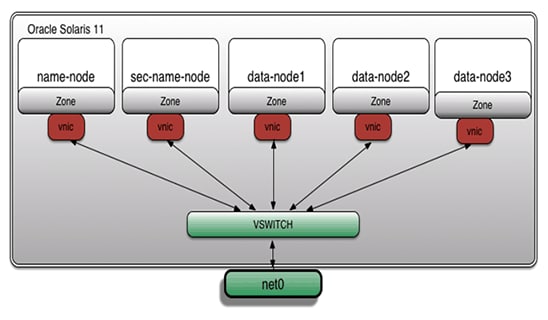
図1
演習1:Hadoopのインストール
- Oracle VM VirtualBoxで、ホストとゲストの間の双方向"共有クリップボード"を有効にして、このファイルからテキストをコピーして貼り付けることができるようにします。
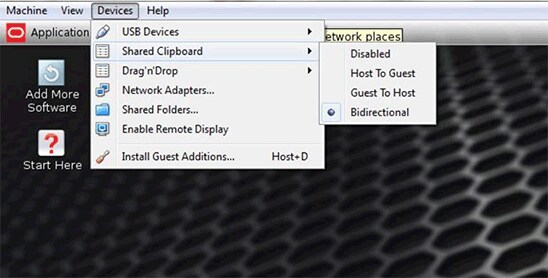
図2
- デスクトップで、背景の任意の場所を右クリックし、ポップアップ・メニューから「Open Terminal」を選択してターミナル・ウィンドウを開きます。
図3
- 次のコマンドを使用して
rootユーザーに切り替えます。
注:Oracle OpenWorldの参加者の場合は、rootパスワードがこのラボに関する要綱に記載されています。Oracle OpenWorld以外の場所でこのラボを実行している場合は、"システム要件"の項の手順で入力したrootパスワードを入力してください。
root@global_zone:~# su - Password: Oracle Corporation SunOS 5.11 11.1 September 2012
- 非大域ゾーンから大域ゾーンへのネットワーク・アクセスを可能にするために、仮想ネットワーク・インタフェース・カード(VNIC)をセットアップします。
注:Oracle OpenWorldの参加者は、この手順をスキップして(事前にロードされたOracle VM VirtualBoxイメージによって、構成済みのVNICが提供されるため)、手順16の"ラボの補助教材へのアクセス"に直接進むことができます。
root@global_zone:~# dladm create-vnic -l net0 vnic0 root@global_zone:~# ipadm create-ip vnic0 root@global_zone:~# ipadm create-addr -T static -a local=192.168.1.100/24 vnic0/addr
- VNICの作成を検証します。
root@global_zone:~# ipadm show-addr vnic0 ADDROBJ TYPE STATE ADDR vnic0/addr static ok 192.168.1.100/24
hadoopholディレクトリを作成します。このディレクトリは、このラボの補助教材(スクリプト、入力ファイルなど)を格納するために使用します。
root@global_zone:~# mkdir -p /usr/local/hadoophol
Binディレクトリを作成します。このディレクトリに、Hadoopバイナリ・ファイルを格納します。
root@global_zone:~# mkdir /usr/local/hadoophol/Bin
- このラボでは、Apache Hadoop "23-Jul-2013, 2013: Release 1.2.1"リリースを使用します。このHadoopバイナリ・ファイルは、Webブラウザを使用してダウンロードできます。デスクトップからFirefox Webブラウザを開き、ファイルをダウンロードしてください。
図4
- Hadoop tarballを
/usr/local/hadoophol/Binにコピーします。
root@global_zone:~# cp /export/home/oracle/Downloads/hadoop-1.2.1.tar.gz /usr/local/hadoophol/Bin/
注:デフォルトでは、このファイルは、ユーザーの
Downloadsディレクトリにダウンロードされます。 - 次に、ラボのスクリプトを作成する準備として、それらを格納するためのディレクトリを作成します。
root@global_zone:~# mkdir /usr/local/hadoophol/Scripts
- 任意のエディタを使用して、リスト1に示すように
createzoneスクリプトを作成します。このスクリプトは、Oracle Solaris Zonesをセットアップするために使用します。
root@global_zone:~# vi /usr/local/hadoophol/Scripts/createzone
リスト1#!/bin/ksh # FILENAME: createzone # Create a zone with a VNIC # Usage: # createzone <zone name> <VNIC> if [ $# != 2 ] then echo "Usage: createzone <zone name> <VNIC>" exit 1 fi ZONENAME=$1 VNICNAME=$2 zonecfg -z $ZONENAME > /dev/null 2>&1 << EOF create set autoboot=true set limitpriv=default,dtrace_proc,dtrace_user,sys_time set zonepath=/zones/$ZONENAME add fs set dir=/usr/local set special=/usr/local set type=lofs set options=[ro,nodevices] end add net set physical=$VNICNAME end verify exit EOF if [ $? == 0 ] ; then echo "Successfully created the $ZONENAME zone" else echo "Error: unable to create the $ZONENAME zone" exit 1 fi - 任意のエディタを使用して、リスト2に示すように
verifyclusterスクリプトを作成します。このスクリプトは、Hadoopクラスタのセットアップを検証するために使用します。
root@global_zone:~# vi /usr/local/hadoophol/Scripts/verifycluster
リスト2#!/bin/ksh # FILENAME: verifycluster # Verify the hadoop cluster configuration # Usage: # verifycluster RET=1 for transaction in _; do for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ls /usr/local > /dev/null 2>&1 " eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping name-node > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping sec-name-node > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node1 > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node2 > /dev/null 2>&1" eval $cmd || break 2 done for i in name-node sec-name-node data-node1 data-node2 data-node3 do cmd="zlogin $i ping data-node3 > /dev/null 2>&1" eval $cmd || break 2 done RET=0 done if [ $RET == 0 ] ; then echo "The cluster is verified" else echo "Error: unable to verify the cluster" fi exit $RET Docディレクトリを作成します。このディレクトリに、Hadoop入力ファイルを格納します。
root@global_zone:~# mkdir /usr/local/hadoophol/Doc
- Project Gutenbergから、Outline of Science、第1巻(J. Arthur Thomson著、全4巻)という電子書籍をUTF-8エンコーディングのプレーン・テキスト・ファイルとしてダウンロードします。
- ダウンロードしたファイル(
pg20417.txt)を/usr/local/hadoophol/Docディレクトリにコピーします。
root@global_zone:~# cp ~oracle/Downloads/pg20417.txt /usr/local/hadoophol/Doc/
- コマンドラインに次のコマンドを入力して、ラボの補助教材にアクセスします。
root@global_zone:~# cd /usr/local/hadoophol
- コマンドラインに
ls -lコマンドを入力して、ディレクトリの内容を表示します。
root@global_zone:~# ls -l total 9 drwxr-xr-x 2 root root 2 Jul 8 15:11 Bin drwxr-xr-x 2 root root 2 Jul 8 15:11 Doc drwxr-xr-x 2 root root 2 Jul 8 15:12 Scripts
以下のディレクトリ構造が表示されます。
Bin—Hadoopバイナリの格納場所Doc—Hadoop入力ファイルScripts—ラボのスクリプト
- このラボでは、Apache Hadoop "23-Jul-2013, 2013: Release 1.2.1"リリースを使用します。 Hadoop tarballを
/usr/localにコピーします。
root@global_zone:~# cp /usr/local/hadoophol/Bin/hadoop-1.2.1.tar.gz /usr/local
- tarballを解凍します。
root@global_zone:~# cd /usr/local root@global_zone:~# tar -xvfz /usr/local/hadoop-1.2.1.tar.gz
hadoopグループを作成します。
root@global_zone:~# groupadd hadoop
hadoopユーザーを追加します。
root@global_zone:~# useradd -m -g hadoop hadoop
- ユーザーのHadoopパスワードを設定します。任意のパスワードを使用できますが、パスワードを忘れないようにしてください。
root@global_zone:~# passwd hadoop
- Hadoopバイナリのシンボリック・リンクを作成します。
root@global_zone:~# ln -s /usr/local/hadoop-1.2.1 /usr/local/hadoop
hadoopユーザーに所有権を与えます。
root@global_zone:~# chown -R hadoop:hadoop /usr/local/hadoop*
- 権限を変更します。
root@global_zone:~# chmod -R 755 /usr/local/hadoop*
演習2:Hadoop構成ファイルの編集
この演習では、表1に示すHadoop構成ファイルを編集します。
表1:Hadoop構成ファイル| ファイル名 | 説明 |
|---|---|
hadoop-env.sh |
Hadoopが使用する環境変数設定を指定します。 |
core-site.xml |
すべてのHadoopデーモンおよびクライアントに関連するパラメータを指定します。 |
mapred-site.xml |
MapReduceデーモンおよびクライアントが使用するパラメータを指定します。 |
masters |
セカンダリ・ネームノードを実行するマシンのリストが含まれます。 |
slaves |
デーモンのデータノードとTaskTrackerのペアを実行するマシン名のリストが含まれます。 |
これらの構成ファイルによるHadoopフレームワークの制御方法について詳しくは、http://hadoop.apache.org/docs/r1.2.1/api/org/apache/hadoop/conf/Configuration.htmlを参照してください。
- 次のコマンドを実行して
confディレクトリに変更します。
root@global_zone:~# cd /usr/local/hadoop/conf
- 次のコマンドを実行して
hadoop-env.shスクリプトを変更します。
注:クラスタ構成は、複数のゾーンで、Hadoopディレクトリ構造(
/usr/local/hadoop)を読取り専用ファイル・システムとして共有します。すべてのHadoopクラスタ・ノードは、そのログを個別のディレクトリに書き込めるようにする必要があります。各Oracle Solaris Zoneについては、/var/log/hadoopディレクトリが最適です。root@global_zone:~# echo "export JAVA_HOME=/usr/java" >> hadoop-env.sh root@global_zone:~# echo "export HADOOP_LOG_DIR=/var/log/hadoop" >> hadoop-env.sh
mastersファイルを編集し、localhostエントリをリスト3に示す行で置き換えます。
root@global_zone:~# vi masters
リスト3sec-name-node
slavesファイルを編集し、localhostエントリをリスト4に示す行で置き換えます。
root@global_zone:~# vi slaves
リスト4data-node1 data-node2 data-node3
core-site.xmlファイルを、リスト5のように編集します。
root@global_zone:~# vi core-site.xml
注:
リスト5fs.default.nameは、そのクラスタのネームノード・アドレス(プロトコル指定子、ホスト名、ポート)を示すURIです。各データノード・インスタンスは、このネームノードに登録され、このネームノードを通じてデータを提供します。さらに、データノードはネームノードにハートビートを送信します。これにより、各データノードが動作していることと、それがホストするブロック・レプリカが使用可能であることが確認されます。<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://name-node</value> </property> </configuration>hdfs-site.xmlファイルを、リスト6のように編集します。
root@global_zone:~# vi hdfs-site.xml
注:
dfs.data.dirは、ローカル・ファイル・システム上の、データノード・インスタンスのデータが格納される場所のパスです。dfs.name.dirは、ネームノード・インスタンスのローカル・ファイル・システム上の、ネームノード・メタデータが格納される場所のパスです。これは、ネームノード・インスタンスによって、その情報を検出するためにのみ使用されます。dfs.replicationは、ファイル・システムのデータの各ブロックに関するデフォルトのレプリケーション因子です(本番クラスタの場合は、通常、デフォルト値の3のままにします)。
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.data.dir</name> <value>/hdfs/data/</value> </property> <property> <name>dfs.name.dir</name> <value>/hdfs/name/</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>mapred-site.xmlファイルを、リスト7のように編集します。
root@global_zone:~# vi mapred-site.xml
注:
リスト7mapred.job.trackerは、JobTrackerのRPCアドレスを指定する、ホスト:ポートという文字列です。<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.job.tracker</name> <value>name-node:8021</value> </property> </configuration>
演習3:Network Time Protocolの構成
Hadoopゾーンのシステム・クロックがNetwork Time Protocol(NTP)を使用して同期していることを確認する必要があります。
注:専用の時刻同期ソースとして使用できるNTPサーバーを選択することを推奨します。これにより、マシンを計画保守のために停止しても、他のサービスに悪影響を及ぼすことがなくなります。
以下の例では、大域ゾーンがNTPサーバーとして構成されます。
- NTPサーバーを構成します。
root@global_zone:~# cd /etc/inet root@global_zone:~# cp ntp.server ntp.conf root@global_zone:~# chmod +w /etc/inet/ntp.conf root@global_zone:~# touch /var/ntp/ntp.drift
- NTPサーバー構成ファイルを、リスト8のように編集します。
root@global_zone:~# vi /etc/inet/ntp.conf
リスト8server 127.127.1.0 prefer broadcast 224.0.1.1 ttl 4 enable auth monitor driftfile /var/ntp/ntp.drift statsdir /var/ntp/ntpstats/ filegen peerstats file peerstats type day enable filegen loopstats file loopstats type day enable filegen clockstats file clockstats type day enable keys /etc/inet/ntp.keys trustedkey 0 requestkey 0 controlkey 0
- NTPサーバー・サービスを有効にします。
root@global_zone:~# svcadm enable ntp
- 次のコマンドを使用して、NTPサーバーがオンラインになっていることを確認します。
root@global_zone:~# svcs -a | grep ntp online 16:04:15 svc:/network/ntp:default
演習4:仮想ネットワーク・インタフェースの作成
概念の説明:Oracle Solaris 11ネットワーク仮想化テクノロジー
Oracle Solarisは、データセンター導入に対するニーズの高まりに応じた、安全でスケーラブルな信頼性の高いインフラストラクチャを提供します。Project Crossbowとしても知られるOracle Solarisの強力なネットワーク・スタック・アーキテクチャによって、以下の機能が提供されます。
- 仮想NIC(VNIC)と仮想スイッチによるネットワーク仮想化
- Oracle Solaris ZonesとOracle Solaris 10 Zonesの緊密な統合
- 統合QoSを簡単に効率よく管理して、VNICおよびトラフィック・フローに帯域幅制限を適用できる、ネットワーク・リソース管理
- ネットワークの負荷レベルに対応する、最適化されたネットワーク・スタック
- "コンテナ型データセンター"の構築
同じシステム上のOracle Solaris Zonesでは、たとえば1Gbの物理ネットワーク接続を使用するシステムと比較しても、非常に待機時間の短い、非常に優れたネットワークI/Oスループット(最大4倍の速さ)によるメリットが得られます。Hadoopクラスタの場合は、これにより、データノードがHDFSブロックを極めて迅速にレプリケートできます。
ネットワーク仮想化のベンチマークについて詳しくは、"How to Control Your Application's Network Bandwidth"を参照してください。
- 各ゾーンに一連の仮想ネットワーク・インタフェース(VNIC)を作成します。
root@global_zone:~# dladm create-vnic -l net0 name_node1 root@global_zone:~# dladm create-vnic -l net0 secondary_name1 root@global_zone:~# dladm create-vnic -l net0 data_node1 root@global_zone:~# dladm create-vnic -l net0 data_node2 root@global_zone:~# dladm create-vnic -l net0 data_node3
- VNICの作成を検証します。
root@global_zone:~# dladm show-vnic LINK OVER SPEED MACADDRESS MACADDRTYPE VID name_node1 net0 1000 2:8:20:c6:3e:f1 random 0 secondary_name1 net0 1000 2:8:20:b9:80:45 random 0 data_node1 net0 1000 2:8:20:30:1c:3a random 0 data_node2 net0 1000 2:8:20:a8:b1:16 random 0 data_node3 net0 1000 2:8:20:df:89:81 random 0
ここでは、5つのVNICがあることを確認できます。図5に、アーキテクチャ・レイアウトを示します。
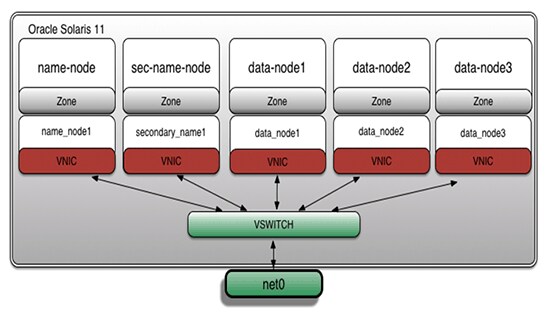
図5
演習5:ネームノードおよびセカンダリ・ネームノード・ゾーンの作成
概念の説明:Oracle Solaris Zones
Oracle Solaris Zonesを使用すると、同じOS上のアプリケーションを相互に分離して、隔離された環境を作成できます。この環境では、ユーザーは、Oracle Solaris Zoneにログインして、そのゾーン内で、ゾーンの外部に影響を与えずに作業を行うことができます。さらに、Oracle Solaris Zonesは、外部からの攻撃や内部の悪意のあるプログラムに対しても安全です。各Oracle Solaris Zoneには、CPU、メモリ、ネットワーク、ストレージなどのリソースを割り当てることができる完全なリソース制御環境が含まれます。
システムを所有する管理者であれば、すべてのOracle Solaris Zonesを厳格に管理することもできますし、特定のOracle Solaris Zonesに関する権限を別の管理者に割り当てることもできます。この柔軟性により、同じOS内で、アプリケーションごとに、そのニーズに合った完全なコンピューティング環境を用意できます。
Oracle Solaris Zonesについて詳しくは、"Oracle Solaris 10ゾーンのOracle Solaris 11への迅速な移行"を参照してください。
このラボ用のHadoopノードはすべて、Oracle Solaris Zonesを使用してインストールされます。
- まだネームノードおよびセカンダリ・ネームノード・ゾーン用のファイル・システムがない場合は、次のコマンドを実行します。
root@global_zone:~# zfs create -o mountpoint=/zones rpool/zones
- ZFSファイル・システムの作成を確認します。
root@global_zone:~# zfs list rpool/zones NAME USED AVAIL REFER MOUNTPOINT rpool/zones 31K 51.4G 31K /zones
name-nodeゾーンを作成します。
root@global_zone:~# zonecfg -z name-node Use 'create' to begin configuring a new zone. Zonecfg:name-node> create create: Using system default template 'SYSdefault' zonecfg:name-node> set autoboot=true zonecfg:name-node> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:name-node> set zonepath=/zones/name-node zonecfg:name-node> add fs zonecfg:name-node:fs> set dir=/usr/local zonecfg:name-node:fs> set special=/usr/local zonecfg:name-node:fs> set type=lofs zonecfg:name-node:fs> set options=[ro,nodevices] zonecfg:name-node:fs> end zonecfg:name-node> add net zonecfg:name-node:net> set physical=name_node1 zonecfg:name-node:net> end zonecfg:name-node> verify zonecfg:name-node> exit
(オプション)ゾーン構成ファイルを作成する次のスクリプトを使用して、
name-nodeゾーンを作成できます。このスクリプトでは、引数として、たとえばcreatezone <zone name> <VNIC name>のようにゾーン名とVNIC名を指定する必要があります。root@global_zone:~# /usr/local/hadoophol/Scripts/createzone name-node name_node1
sec-name-nodeゾーンを作成します。
root@global_zone:~# zonecfg -z sec-name-node Use 'create' to begin configuring a new zone. Zonecfg:sec-name-node> create create: Using system default template 'SYSdefault' zonecfg:sec-name-node> set autoboot=true zonecfg:sec-name-node> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:sec-name-node> set zonepath=/zones/sec-name-node zonecfg:sec-name-node> add fs zonecfg:sec-name-node:fs> set dir=/usr/local zonecfg:sec-name-node:fs> set special=/usr/local zonecfg:sec-name-node:fs> set type=lofs zonecfg:sec-name-node:fs> set options=[ro,nodevices] zonecfg:sec-name-node:fs> end zonecfg:sec-name-node> add net zonecfg:sec-name-node:net> set physical=secondary_name1 zonecfg:sec-name-node:net> end zonecfg:sec-name-node> verify zonecfg:sec-name-node> exit
(オプション)ゾーン構成ファイルを作成する次のスクリプトを使用して、
sec-name-nodeゾーンを作成できます。このスクリプトでは、引数として、たとえばcreatezone <zone name> <VNIC name>のようにゾーン名とVNIC名を指定する必要があります。root@global_zone:~: /usr/local/hadoophol/Scripts/createzone sec-name-node secondary_name1
演習6:データノード・ゾーンのセットアップ
この演習では、Oracle Solarisに組み込まれているOracle Solaris Zones仮想化テクノロジーとZFSファイル・システムの統合を活用します。
表2に、作成するHadoopゾーン構成の概要を示します。
表2:ゾーンの概要| 機能 | ゾーン名 | ZFSマウント・ポイント | VNIC名 | IPアドレス |
|---|---|---|---|---|
| ネームノード | name-node |
/zones/name-node |
name_node1 |
192.168.1.1 |
| セカンダリ・ネームノード | sec-name-node |
/zones/sec-name-node |
secondary_name1 |
192.168.1.2 |
| データノード | data-node1 |
/zones/data-node1 |
data_node1 |
192.168.1.3 |
| データノード | data-node2 |
/zones/data-node2 |
data_node2 |
192.168.1.4 |
| データノード | data-node3 |
/zones/data-node3 |
data_node3 |
192.168.1.5 |
data-node1ゾーンを作成します。
root@global_zone:~# zonecfg -z data-node1 Use 'create' to begin configuring a new zone. zonecfg:data-node1> create create: Using system default template 'SYSdefault' zonecfg:data-node1> set autoboot=true zonecfg:data-node1> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node1> set zonepath=/zones/data-node1 zonecfg:data-node1> add fs zonecfg:data-node1:fs> set dir=/usr/local zonecfg:data-node1:fs> set special=/usr/local zonecfg:data-node1:fs> set type=lofs zonecfg:data-node1:fs> set options=[ro,nodevices] zonecfg:data-node1:fs> end zonecfg:data-node1> add net zonecfg:data-node1:net> set physical=data_node1 zonecfg:data-node1:net> end zonecfg:data-node1> verify zonecfg:data-node1> commit zonecfg:data-node1> exit
(オプション)次のスクリプトを使用して、
data-node1ゾーンを作成できます。root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node1 data_node1
data-node2ゾーンを作成します。
root@global_zone:~# zonecfg -z data-node2 Use 'create' to begin configuring a new zone. zonecfg:data-node2> create create: Using system default template 'SYSdefault' zonecfg:data-node2> set autoboot=true zonecfg:data-node2> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node2> set zonepath=/zones/data-node2 zonecfg:data-node2> add fs zonecfg:data-node2:fs> set dir=/usr/local zonecfg:data-node2:fs> set special=/usr/local zonecfg:data-node2:fs> set type=lofs zonecfg:data-node2:fs> set options=[ro,nodevices] zonecfg:data-node2:fs> end zonecfg:data-node2> add net zonecfg:data-node2:net> set physical=data_node2 zonecfg:data-node2:net> end zonecfg:data-node2> verify zonecfg:data-node2> commit zonecfg:data-node2> exit
(オプション)次のスクリプトを使用して、
data-node2ゾーンを作成できます。root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node2 data_node2
data-node3ゾーンを作成します。
root@global_zone:~# zonecfg -z data-node3 Use 'create' to begin configuring a new zone. zonecfg:data-node3> create create: Using system default template 'SYSdefault' zonecfg:data-node3> set autoboot=true zonecfg:data-node3> set limitpriv=default,dtrace_proc,dtrace_user,sys_time zonecfg:data-node3> set zonepath=/zones/data-node3 zonecfg:data-node3> add fs zonecfg:data-node3:fs> set dir=/usr/local zonecfg:data-node3:fs> set special=/usr/local zonecfg:data-node3:fs> set type=lofs zonecfg:data-node3:fs> set options=[ro,nodevices] zonecfg:data-node3:fs> end zonecfg:data-node3> add net zonecfg:data-node3:net> set physical=data_node3 zonecfg:data-node3:net> end zonecfg:data-node3> verify zonecfg:data-node3> commit zonecfg:data-node3> exit
(オプション)次のスクリプトを使用して、
data-node3ゾーンを作成できます。root@global_zone:~# /usr/local/hadoophol/Scripts/createzone data-node3 data_node3
演習7:ネームノードの構成
- ここで、
name-nodeゾーンをインストールします。後で、このゾーンをクローン化することにより、ゾーン作成時間を短縮します。
root@global_zone:~# zoneadm -z name-node install The following ZFS file system(s) have been created: rpool/zones/name-node Progress being logged to /var/log/zones/zoneadm.20130106T134835Z.name-node.install Image: Preparing at /zones/name-node/root. name-nodeゾーンを起動します。
root@global_zone:~# zoneadm -z name-node boot
- 作成したゾーンのステータスを確認します。
root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 1 name-node running /zones/name-node solaris excl - sec-name-node configured /zones/sec-name-node solaris excl - data-node1 configured /zones/data-node1 solaris excl - data-node2 configured /zones/data-node2 solaris excl - data-node3 configured /zones/data-node3 solaris excl name-nodeゾーンにログインします。
root@global_zone:~# zlogin -C name-node
name-nodeゾーンに関する以下の構成を使用して、ゾーン・ホスト情報を提供します。
- ホスト名については、
name-nodeを使用します。 - 手動ネットワーク構成を選択します。
- ネットワーク・インタフェースの
name_node1のIPアドレスが192.168.1.1、ネットマスクが255.255.255.0であることを確認します。 - ネーム・サービスがネットワーク構成に基づいていることを確認します。このラボでは、名前解決に
/etc/hostsを使用します。このため、ホスト名解決用のDNSはセットアップしません。「Do not configure DNS」を選択します。 - 代替サービス名については、「None」を選択します。
- タイムゾーンの地域については、「Americas」を選択します。
- タイムゾーンの場所については、「United States」を選択します。
- タイムゾーンについては、「Pacific Time」を選択します。
- rootパスワードを入力します。
- ホスト名については、
- ゾーンのセットアップが完了すると、ログイン・プロンプトが表示されます。
rootユーザーとしてゾーンにログインします。
name-node console login: root Password:
- Hadoopの開発には、Javaプログラミング環境が必要です。次のコマンドを使用して、Java Development Kit(JDK)6をインストールできます。
root@name-node:~# pkg install jdk-6
- Javaのインストールを検証します。
root@name-node:~# which java /usr/bin/java root@name-node:~# java -version java version "1.6.0_35" Java(TM) SE Runtime Environment (build 1.6.0_35-b10) Java HotSpot(TM) Client VM (build 20.10-b01, mixed mode)
name-nodeゾーン内にHadoopユーザーを作成します。
root@name-node:~# groupadd hadoop root@name-node:~# useradd -m -g hadoop hadoop root@name-node:~# passwd hadoop
注:このパスワードは、演習1の手順22でユーザーのHadoopパスワードを設定したときに入力したものと同じである必要があります。
- Hadoopログ・ファイル用のディレクトリを作成します。
root@name-node:~# mkdir /var/log/hadoop root@name-node:~# chown hadoop:hadoop /var/log/hadoop
- 次の例のように、NTPクライアントを構成します。
- NTPパッケージをインストールします。
root@name-node:~# pkg install ntp
- NTPクライアント構成ファイルを作成します。
root@name-node:~# cd /etc/inet root@name-node:~# cp ntp.client ntp.conf root@name-node:~# chmod +w /etc/inet/ntp.conf root@name-node:~# touch /var/ntp/ntp.drift
- NTPクライアント構成ファイルを、リスト9のように編集します。
root@name-node:~# vi /etc/inet/ntp.conf
注:このラボでは、大域ゾーンをタイム・サーバーとして使用するので、その名前(
リスト9global-zoneなど)を/etc/inet/ntp.confに追加します。server global-zone prefer driftfile /var/ntp/ntp.drift statsdir /var/ntp/ntpstats/ filegen peerstats file peerstats type day enable filegen loopstats file loopstats type day enable
- NTPパッケージをインストールします。
- リスト10のように、Hadoopクラスタ・メンバーのホスト名とIPアドレスを
/etc/hostsに追加します。
root@name-node:~# vi /etc/hosts
リスト10::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3 192.168.1.100 global-zone
- NTPクライアント・サービスを有効にします。
root@name-node:~# svcadm enable ntp
- NTPクライアントのステータスを確認します。
root@name-node:~# svcs ntp STATE STIME FMRI online 11:15:59 svc:/network/ntp:default
- NTPクライアントがクロックをNTPサーバーと同期させることができるかどうかを確認します。
root@name-node:~# ntpq -p
演習8:SSHのセットアップ
- セカンダリ・データノードおよびデータノードへのパスワードなしのログインを有効にするために、
name_nodeゾーンでのHadoopユーザー用のSSH鍵ベース認証をセットアップします。
root@name-node:~# su - hadoop hadoop@name-node $ ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa hadoop@name-node $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$HOME/.profileを編集して、ファイルの最後に、リスト11に示す行を追加します。
hadoop@name-node $ vi $HOME/.profile
リスト11# Set JAVA_HOME export JAVA_HOME=/usr/java # Add Hadoop bin/ directory to PATH export PATH=$PATH:/usr/local/hadoop/bin
ここで、次のコマンドを実行します。
hadoop@name-node $ source $HOME/.profile
- 次のコマンドを実行して、Hadoopが動作していることを確認します。
hadoop@name-node:~$ hadoop version Hadoop 1.2.1 Subversion https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152 Compiled by mattf on Mon Jul 22 15:23:09 PDT 2013 From source with checksum 6923c86528809c4e7e6f493b6b413a9a
注:
~.を入力すると、name-nodeコンソールが終了して、大域ゾーンに戻ります。zonenameコマンドを使用すると、大域ゾーンに戻っていることを確認できます。root@global_zone:~# zonename global
- 大域ゾーンから、次のコマンドを実行して、
sec-name-nodeゾーンをname-nodeのクローンとして作成します。
root@global_zone:~# zoneadm -z name-node shutdown root@global_zone:~# zoneadm -z sec-name-node clone name-node
sec-name-nodeゾーンを起動します。
root@global_zone:~# zoneadm -z sec-name-node boot root@global_zone:~# zlogin -C sec-name-node
- 以前と同様に、システム構成ツールが起動するので(図6を参照)、以下のように
sec-name-nodeゾーンの最終的な構成を実行します。
注:すべてのゾーンで、タイムゾーン構成とrootパスワードが同じである必要があります。
図6
- ホスト名については、
sec-name-nodeを使用します。 - 手動ネットワーク構成を選択し、ネットワーク・インタフェースについて
secondary_name1を使用します。 - IPアドレスとして192.168.1.2、ネットマスクとして255.255.255.0を使用します。
- DNSネーム・サービス・ウィンドウで「Do not configure DNS」を選択します。
- 代替ネーム・サービスが「None」に設定されていることを確認します。
- タイムゾーンの地域については、「Americas」を選択します。
- タイムゾーンの場所については、「United States」を選択します。
- タイムゾーンについては、「Pacific Time」を選択します。
- rootパスワードを入力します。
注:
~.を入力すると、sec-name-nodeコンソールが終了して、大域ゾーンに戻ります。
- ホスト名については、
data-node1、data-node2、data-node3について、同様の手順を実行します。
data-node1については、以下のように構成します。
root@global_zone:~# zoneadm -z data-node1 clone name-node root@global_zone:~# zoneadm -z data-node1 boot root@global_zone:~# zlogin -C data-node1
- ホスト名については、
data-node1を使用します。 - 手動ネットワーク構成を選択し、ネットワーク・インタフェースについて
data_node1を使用します。 - IPアドレスとして192.168.1.3、ネットマスクとして255.255.255.0を使用します。
- DNSネーム・サービス・ウィンドウで「Do not configure DNS」を選択します。
- 代替ネーム・サービスが「None」に設定されていることを確認します。
- タイムゾーンの地域については、「Americas」を選択します。
- タイムゾーンの場所については、「United States」を選択します。
- タイムゾーンについては、「Pacific Time」を選択します。
- rootパスワードを入力します。
- ホスト名については、
data-node2については、以下のように構成します。
root@global_zone:~# zoneadm -z data-node2 clone name-node root@global_zone:~# zoneadm -z data-node2 boot root@global_zone:~# zlogin -C data-node2
- ホスト名については、
data-node2を使用します。 - ネットワーク・インタフェースについては、
data_node2を使用します。 - IPアドレスとして192.168.1.4、ネットマスクとして255.255.255.0を使用します。
- DNSネーム・サービス・ウィンドウで「Do not configure DNS」を選択します。
- 代替ネーム・サービスが「None」に設定されていることを確認します。
- タイムゾーンの地域については、「Americas」を選択します。
- タイムゾーンの場所については、「United States」を選択します。
- タイムゾーンについては、「Pacific Time」を選択します。
- rootパスワードを入力します。
- ホスト名については、
data-node3については、以下のように構成します。
root@global_zone:~# zoneadm -z data-node3 clone name-node root@global_zone:~# zoneadm -z data-node3 boot root@global_zone:~# zlogin -C data-node3
- ホスト名については、
data-node3を使用します。 - ネットワーク・インタフェースについては、
data_node3を使用します。 - IPアドレスとして192.168.1.5、ネットマスクとして255.255.255.0を使用します。
- DNSネーム・サービス・ウィンドウで「Do not configure DNS」を選択します。
- 代替ネーム・サービスが「None」に設定されていることを確認します。
- タイムゾーンの地域については、「Americas」を選択します。
- タイムゾーンの場所については、「United States」を選択します。
- タイムゾーンについては、「Pacific Time」を選択します。
- rootパスワードを入力します。
- ホスト名については、
name_nodeゾーンを起動します。
root@global_zone:~# zoneadm -z name-node boot
- すべてのゾーンが稼働中であることを確認します。
root@global_zone:~# zoneadm list -cv ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 10 sec-name-node running /zones/sec-name-node solaris excl 12 data-node1 running /zones/data-node1 solaris excl 14 data-node2 running /zones/data-node2 solaris excl 16 data-node3 running /zones/data-node3 solaris excl 17 name-node running /zones/name-node solaris excl
- Hadoopユーザーの、パスワードを使用しないSSHアクセスを検証するために、以下の手順を実行します。
name_nodeから、SSHを使用してname-node(つまり、それ自体)にログインします。
root@global_zone:~# zlogin name-node root@name-node:~# su - hadoop hadoop@name-node $ ssh name-node The authenticity of host 'name-node (192.168.1.1)' can't be established. RSA key fingerprint is 04:93:a9:e0:b7:8c:d7:8b:51:b8:42:d7:9f:e1:80:ca. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'name-node,192.168.1.1' (RSA) to the list of known hosts.
- ここで、
sec-name-nodeおよびデータノード(data-node1、data-node2、data-node3)へのログインを試みます。 - もう一度SSHを使用してホストへのログインを試みます。今度は、既知の鍵のリストへのホストの追加を求めるメッセージが表示されないはずです。
sec-name-nodeおよびデータノード内の/etc/hostsファイルを編集し、name-nodeエントリを追加します。
root@global_zone:~# zlogin sec-name-node 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node1 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node2 'echo "192.168.1.1 name-node" >> /etc/hosts' root@global_zone:~# zlogin data-node3 'echo "192.168.1.1 name-node" >> /etc/hosts'
- 名前解決を検証します。これには、大域ゾーンとすべてのHadoopゾーンの
/etc/hostsにリスト12のようなホスト・エントリがあることを確認します。
# cat /etc/hosts
リスト12::1 localhost 127.0.0.1 localhost loghost 192.168.1.1 name-node 192.168.1.2 sec-name-node 192.168.1.3 data-node1 192.168.1.4 data-node2 192.168.1.5 data-node3 192.168.1.100 global-zone
注:大域ゾーンをNTPサーバーとして使用している場合は、そのホスト名とIPアドレスも
/etc/hostsに追加する必要があります。 verifyclusterスクリプトを使用してクラスタを検証します。
root@global_zone:~# /usr/local/hadoophol/Scripts/verifycluster
クラスタが正常にセットアップされていれば、
cluster is verifiedというメッセージが表示されます。注:
verifyclusterスクリプトが失敗してエラー・メッセージが表示される場合は、手順12で説明したように各ゾーンの/etc/hostsファイルにすべてのゾーン名が含まれていることを確認してから、verifiabilityスクリプトを再実行してください。
演習9:ネームノードからのHDFSのフォーマット
概念の説明:Hadoop分散ファイル・システム(HDFS)
HDFSは、スケーラブルな分散ファイル・システムです。HDFSでは、メタデータがネームノードに格納されます。アプリケーション・データはデータノードに格納され、各データノードが、HDFS固有のブロック・プロトコルを使用してネットワーク経由でデータのブロックを提供します。このファイル・システムは、TCP/IPレイヤーを使用して通信します。クライアントは、リモート・プロシージャ・コール(RPC)を使用して相互に通信します。
データノードは、データを永続化させるためにRAIDなどのデータ保護メカニズムを使用しません。代わりに、ファイルの内容を複数のデータノードにレプリケートすることで、信頼性を向上させます。
hdfs-site.xmlファイルで設定されるレプリケーション値がデフォルトの3の場合、データが3つのノードに格納されます。データノードは、相互に通信して、データを再調整し、コピーを移動し、データのレプリケーションを高レベルに維持します。図7は、レプリケーション値に基づいて各データ・ブロックが3つのデータノードにレプリケートされることを示しています。
HDFSを使用するメリットは、JobTrackerとTaskTrackerの間でのデータ認識です。JobTrackerは、データのある場所を認識することで、TaskTrackerに対してMapまたはReduceジョブをスケジュール設定します。例として、データ(x、y、z)を含むノードAとデータ(a、b、c)を含むノードBがあるとします。JobTrackerは、(a、b、c)に関するMapまたはReduceタスクを実行するようにノードBをスケジュール設定し、(x、y、z)に関するMapまたはReduceタスクを実行するようにノードAをスケジュール設定します。これにより、ネットワーク経由で送信されるトラフィックの総量が削減され、不要なデータ転送が抑制されます。このデータ認識は、ジョブが完了するまでの時間に大きな影響を与える可能性があり、データを多用するジョブを実行する場合は、その影響が実証されています。
Hadoop HDFSについて詳しくは、https://en.wikipedia.org/wiki/Hadoopを参照してください。
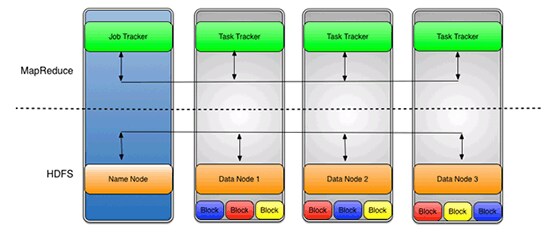
図7
- HDFSをフォーマットするには、以下のコマンドを実行し、プロンプトに対してYと応答します。
root@global_zone:~# zlogin name-node root@name-node:~# mkdir -p /hdfs/name root@name-node:~# chown -R hadoop:hadoop /hdfs root@name-node:~# su - hadoop hadoop@name-node:$ /usr/local/hadoop/bin/hadoop namenode -format 13/10/13 09:10:52 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = name-node/192.168.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.1 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013 STARTUP_MSG: java = 1.6.0_35 ************************************************************/ hadoop@name-node:$ Re-format filesystem in /hdfs/name ? (Y or N) Y
- すべてのデータノード(
data-node1、data-node2、data-node3)で、HDFSブロックを格納するためのHadoopデータ・ディレクトリを作成します。
root@global_zone:~# zlogin data-node1 root@data-node1:~# mkdir -p /hdfs/data root@data-node1:~# chown -R hadoop:hadoop /hdfs root@global_zone:~# zlogin data-node2 root@data-node2:~# mkdir -p /hdfs/data root@data-node2:~# chown -R hadoop:hadoop /hdfs root@global_zone:~# zlogin data-node3 root@data-node3:~# mkdir -p /hdfs/data root@data-node3:~# chown -R hadoop:hadoop /hdfs
演習10:Hadoopクラスタの起動
表3で、起動スクリプトについて説明します。
表3:起動スクリプト| ファイル名 | 説明 |
|---|---|
start-dfs.sh |
HDFSデーモン、ネームノード、およびデータノードを起動します。これは、start-mapred.shの前に使用します。 |
stop-dfs.sh |
Hadoop DFSデーモンを停止します。 |
start-mapred.sh |
Hadoop MapReduceデーモン、JobTracker、およびTaskTrackerを起動します。 |
stop-mapred.sh |
Hadoop MapReduceデーモンを停止します。 |
name-nodeゾーンから、次のコマンドを使用して、Hadoop DFSデーモン、ネームノード、およびデータノードを起動します。
root@global_zone:~# zlogin name-node root@name-node:~# su - hadoop hadoop@name-node:$ start-dfs.sh starting namenode, logging to /var/log/hadoop/hadoop--namenode-name-node.out data-node2: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node2.out data-node1: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node1.out data-node3: starting datanode, logging to /var/log/hadoop/hadoop-hadoop-datanode-data-node3.out sec-name-node: starting secondarynamenode, logging to /var/log/hadoop/hadoop-hadoop-secondarynamenode-sec-name-node.out
- 次のコマンドを使用して、Hadoop Map/Reduceデーモン、JobTracker、およびTaskTrackerを起動します。
hadoop@name-node:$ start-mapred.sh starting jobtracker, logging to /var/log/hadoop/hadoop--jobtracker-name-node.out data-node1: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node1.out data-node3: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node3.out data-node2: starting tasktracker, logging to /var/log/hadoop/hadoop-hadoop-tasktracker-data-node2.out
- 包括的なステータス・レポートを表示するために、次のコマンドを実行してクラスタのステータスを調べます。このコマンドにより、クラスタの状態に関する基本統計情報(ネームノードの詳細情報、各データノードのステータス、総ディスク容量など)が出力されます。
hadoop@name-node:$ hadoop dfsadmin -report Configured Capacity: 171455269888 (159.68 GB) Present Capacity: 169711053357 (158.06 GB) DFS Remaining: 169711028736 (158.06 GB) DFS Used: 24621 (24.04 KB) DFS Used%: 0% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead) ...
3つのデータノードが利用可能であることが示されるはずです。
注:同じ情報を、ネームノードのWebステータス・ページ(
http://<NameNode IP address>:50070/dfshealth.jsp)でも確認できます(図8を参照)。ネームノードのIPアドレスは、192.168.1.1です。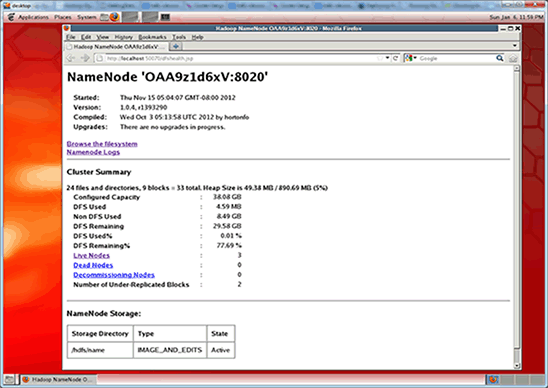
図8
演習11:MapReduceジョブの実行
概念の説明:MapReduce
MapReduceは、コンピュータのクラスタを使用して膨大なデータセットの全体にわたるパラレル化問題に対処するためのフレームワークです。
MapReduceの基本的な考え方は、2つの関数を使用してソースからデータを取得するというものです。Map()関数を使用してから、Reduce()関数を使用してコンピュータのクラスタ全体にわたるデータを処理します。具体的には、Map()がデータセットのすべてのメンバーに関数を適用し、結果セットを通知します。Reduce()は、この結果セットを照合して解決します。
Map()とReduce()は、複数のシステムで並行して実行できます。
MapReduceについて詳しくは、http://en.wikipedia.org/wiki/MapReduceを参照してください。
このラボでは、例として、テキスト・ファイルを読み取って単語の出現回数をカウントするWordCountを使用します。入力と出力はテキスト・ファイルで構成され、テキスト・ファイルの各行には、単語とその単語の出現回数がタブで区切って示されます。WordCountについて詳しくは、http://wiki.apache.org/hadoop/WordCountを参照してください。
- 入力データ・ディレクトリを作成します。このディレクトリに、入力ファイルを格納します。
hadoop@name-node:$ hadoop fs -mkdir /input-data
- ディレクトリの作成を検証します。
hadoop@name-node:$ hadoop dfs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2013-10-13 23:45 /input-data
- 次のコマンドを使用して、以前にダウンロードした
pg20417.txtファイルをHDFSにコピーします。
注:Oracle OpenWorld参加者の場合は、
pg20417.txtファイルを/usr/local/hadoophol/Docディレクトリから入手できます。hadoop@name-node:$ hadoop dfs -copyFromLocal /usr/local/hadoophol/Doc/pg20417.txt /input-data
- ファイルがHDFS上にあることを確認します。
hadoop@name-node:$ hadoop dfs -ls /input-data Found 1 items -rw-r--r-- 3 hadoop supergroup 674570 2013-10-13 10:20 /input-data/pg20417.txt
- 出力ディレクトリを作成します。このディレクトリに、MapReduceジョブの出力が格納されます。
hadoop@name-node:$ hadoop fs -mkdir /output-data
- 次のコマンドを使用して、MapReduceジョブを起動します。
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output1 13/10/13 10:23:08 INFO input.FileInputFormat: Total input paths to process : 1 13/10/13 10:23:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 13/10/13 10:23:08 WARN snappy.LoadSnappy: Snappy native library not loaded 13/10/13 10:23:09 INFO mapred.JobClient: Running job: job_201310130918_0010 13/10/13 10:23:10 INFO mapred.JobClient: map 0% reduce 0% 13/10/13 10:23:19 INFO mapred.JobClient: map 100% reduce 0% 13/10/13 10:23:29 INFO mapred.JobClient: map 100% reduce 33% 13/10/13 10:23:31 INFO mapred.JobClient: map 100% reduce 100% 13/10/13 10:23:34 INFO mapred.JobClient: Job complete: job_201310130918_0010 13/10/13 10:23:34 INFO mapred.JobClient: Counters: 26
このプログラムをクラスタで実行すると、完了するまで約60秒かかります。
入力ディレクトリ(上記のコマンドラインの
input-data)にあるすべてのファイルが読み取られ、入力の単語の出現回数が出力ディレクトリ(output-data/output1と呼ばれる)に書き込まれます。 - 出力データを確認します。
hadoop@name-node:$ hadoop dfs -ls /output-data/output1 Found 3 items -rw-r--r-- 3 hadoop supergroup 0 2013-10-13 10:30 /output-data/output1/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2013-10-13 10:30 /output-data/output1/_logs -rw-r--r-- 3 hadoop supergroup 196192 2013-10-13 10:30 /output-data/output1/part-r-00000
演習12:ZFS暗号化の使用
概念の説明:ZFS暗号化
Oracle Solaris 11によって、透過的な暗号化機能がZFSに追加されます。すべてのデータおよびファイル・システム・メタデータ(所有権、アクセス制御リスト、割当て制限情報など)が、ZFSプールに永続的に格納されるときに暗号化されます。
ZFSプールは、暗号化されたZFSデータセットと暗号化されていないZFSデータセット(ファイル・システムおよびZVOL)の混在をサポートできます。このデータ暗号化は、アプリケーションや他のOracle Solarisファイル・サービス(NFS、CIFSなど)に対しては完全に透過的です。暗号化はZFSの最上位機能であるため、圧縮、暗号化、および重複排除を同時にサポートできます。暗号化されたデータセットの暗号鍵の管理は、ユーザーとOracle Solaris Zonesのいずれかまたは両方に委任できます。Oracle SolarisとZFS暗号化により、保管データを保護するための非常に柔軟なシステムが実現されます。また、これには、アプリケーションの変更や動作確認も不要です。
ZFS暗号化について詳しくは、"How to Manage ZFS Data Encryption"を参照してください。
出力データには機密情報が含まれる場合があるため、ZFS暗号化を使用して出力データを保護します。
- 暗号化されたZFSデータセットを作成します。
注:8文字以上のパスフレーズを指定する必要があります。
root@name-node:~# zfs create -o encryption=on rpool/export/output Enter passphrase for 'rpool/export/output': Enter again:
- ZFSデータセットが暗号化されていることを確認します。
root@name-node:~# zfs get all rpool/export/output | grep encry rpool/export/output encryption on local
- 所有権を変更します。
root@name-node:~# chown hadoop:hadoop /export/output
- 出力ファイルをHDFSからZFSにコピーします。
root@name-node:~# su - hadoop Oracle Corporation SunOS 5.11 11.1 September 2012 hadoop@name-node:$ hadoop dfs -getmerge /output-data/output1 /export/output
- 出力テキスト・ファイルを分析します。各行には、単語とその単語の出現回数がタブで区切って示されます。
hadoop@name-node:$ head /export/output/output1 "A 2 "Alpha 1 "Alpha," 1 "An 2 "And 1 "BOILING" 2 "Batesian" 1 "Beta 2
- ZFSデータセットをアンマウントすることによって出力テキスト・ファイルを保護し、次のコマンドを使用して、暗号化されたデータセットのラッピング鍵をアンロードします。
root@name-node:~# zfs key -u rpool/export/output
コマンドが正常に実行されると、データセットにアクセスできなくなり、データセットがアンマウントされます。
- このZFSファイル・システムをマウントする場合は、パスフレーズを入力する必要があります。
root@name-node:~# zfs mount rpool/export/output Enter passphrase for 'rpool/export/output':
パスフレーズを使用することにより、パスフレーズを知っているユーザーだけが出力ファイルを参照できるという状態を確保できます。
演習13:Oracle Solaris DTraceによるパフォーマンス監視
概念の説明:Oracle Solaris DTrace
Oracle Solaris DTraceは、体系的な問題をリアルタイムでトラブルシューティングするための、包括的で高度なトレース・ツールです。管理者、インテグレーター、および開発者は、アプリケーションとオペレーティング・システム自体の両方を含め、DTraceを使って稼働中の本番システムでパフォーマンスの問題を動的かつ安全に監視できます。
DTraceを使用すると、システムを調査してその動作を把握し、多数のソフトウェア・レイヤーにまたがる問題を突き止めて、異常な動作の原因を特定できます。DTraceによって以下のことが可能になり、メモリ使用量やCPU時間などの全体的な概要情報であれ、実行された特定の関数コールなどの詳細情報であれ、運用状況を把握できるようになります。これは、データセンターでは実現されていなかったものです。
- オペレーティング・システムのすべてのファセットで80,000を超えるプローブ・ポイントを挿入する。
- ユーザーおよびシステム・レベルのソフトウェアを計測する。
- 強力で使いやすいスクリプト言語とコマンドライン・インタフェースを使用する。
DTraceについて詳しくは、http://www.oracle.com/technetwork/server-storage/solaris11/technologies/dtrace-1930301.htmlを参照してください。
- 別のターミナル・ウィンドウを開き、
hadoopユーザーとしてname-nodeにログインします。 - 次のMapReduceジョブを実行します。
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output2
- Hadoopジョブの実行時に、ネームノードで実行されたプロセスを確認します。
ターミナル・ウィンドウで、次のDTraceコマンドを実行します。
root@global-zone:~# dtrace -n 'proc:::exec-success/strstr(zonename,"name-node")>0/ { trace(curpsinfo->pr_psargs); }' dtrace: description 'proc:::exec-success' matched 1 probe CPU ID FUNCTION:NAME 0 4473 exec_common:exec-success /usr/bin/env bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-exa 0 4473 exec_common:exec-success bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-examples-1.1.2.j 0 4473 exec_common:exec-success dirname /usr/local/hadoop-1.1.2/libexec/-- 0 4473 exec_common:exec-success dirname /usr/local/hadoop-1.1.2/libexec/-- 0 4473 exec_common:exec-success sed -e s/ /_/g 1 4473 exec_common:exec-success dirname /usr/local/hadoop/bin/hadoop 1 4473 exec_common:exec-success dirname -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 1 4473 exec_common:exec-success basename -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 1 4473 exec_common:exec-success basename /usr/local/hadoop-1.1.2/libexec/-- 1 4473 exec_common:exec-success uname 1 4473 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 1 4473 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 0 4473 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado 0 4473 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado ^C
注:DTrace出力を表示するには、[Ctrl]+[c]キーを押します。
- Hadoopジョブの実行時に、ネームノードに書き込まれたファイルを確認します。
注:MapReduceジョブが完了したら、異なる出力ディレクトリ(
/output-data/output3など)を使用して別のジョブを実行できます。例:
hadoop@name-node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.1.jar wordcount /input-data/pg20417.txt /output-data/output3
root@global-zone:~# dtrace -n 'syscall::write:entry/strstr(zonename,"name-node")>0/ {@write[fds[arg0].fi_pathname]=count();}' dtrace: description 'syscall::write:entry' matched 1 probe ^C /zones/name-node/root/tmp/hadoop-hadoop/mapred/local/jobTracker/.job_201307181457_0007.xml.crc 1 /zones/name-node/root/var/log/hadoop/history/.job_201307181457_0007_conf.xml.crc 1 /zones/name-node/root/dev/pts/3 5 /zones/name-node/root/var/log/hadoop/job_201307181457_0007_conf.xml 6 /zones/name-node/root/tmp/hadoop-hadoop/mapred/local/jobTracker/job_201307181457_0007.xml 8 /zones/name-node/root/var/log/hadoop/history/job_201307181457_0007_conf.xml 11 /zones/name-node/root/var/log/hadoop/hadoop--jobtracker-name-node.log 13 /zones/name-node/root/hdfs/name/current/edits.new 25 /zones/name-node/root/var/log/hadoop/hadoop--namenode-name-node.log 45 /zones/name-node/root/dev/poll 207 <unknown> 3131655
注:DTrace出力を表示するには、[Ctrl]+[c]キーを押します。
- Hadoopジョブの実行時に、データノードで実行されたプロセスを確認します。
root@global-zone:~# dtrace -n 'proc:::exec-success/strstr(zonename,"data-node1")>0/ { trace(curpsinfo->pr_psargs); }' dtrace: description 'proc:::exec-success' matched 1 probe CPU ID FUNCTION:NAME 0 8833 exec_common:exec-success dirname /usr/local/hadoop/bin/hadoop 0 8833 exec_common:exec-success dirname /usr/local/hadoop/libexec/-- 0 8833 exec_common:exec-success sed -e s/ /_/g 1 8833 exec_common:exec-success dirname -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 2 8833 exec_common:exec-success basename /usr/local/hadoop/libexec/-- 2 8833 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 2 8833 exec_common:exec-success /usr/java/bin/java -Xmx32m org.apache.hadoop.util.PlatformName 3 8833 exec_common:exec-success /usr/bin/env bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-exa 3 8833 exec_common:exec-success bash /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-examples-1.0.4.j 3 8833 exec_common:exec-success basename -- /usr/local/hadoop/bin/../libexec/hadoop-config.sh 3 8833 exec_common:exec-success dirname /usr/local/hadoop/libexec/-- 3 8833 exec_common:exec-success uname 3 8833 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado 3 8833 exec_common:exec-success /usr/java/bin/java -Dproc_jar -Xmx1000m -Dhadoop.log.dir=/var/log/hadoop -Dhado ^C - Hadoopジョブの実行時に、データノードに書き込まれたファイルを確認します。
(出力は222行でしたが、見やすくするために行を減らしています。)
root@global-zone:~# dtrace -n 'syscall::write:entry/strstr(zonename,"data-node1")>0/ {@write[fds[arg0].fi_pathname]=count();}' dtrace: description 'syscall::write:entry' matched 1 probe ^C /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-5404946161781239203 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-5404946161781239203_1103.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-6136035696057459536 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-6136035696057459536_1102.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-8420966433041064066 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_-8420966433041064066_1105.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_1792925233420187481 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_1792925233420187481_1101.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_4108435250688953064 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_4108435250688953064_1106.meta 1 /zones/data-node1/root/hdfs/data/blocksBeingWritten/blk_8503732348705847964 - データノード用に書き込まれたHDFSデータの総容量を確認します。
root@global-zone:~# dtrace -n 'syscall::write:entry / ( strstr(zonename,"data-node1")!=0 || strstr(zonename,"data-node2")!=0 || strstr(zonename,"data-node3")!=0 ) && strstr(fds[arg0].fi_pathname,"hdfs")!=0 && strstr(fds[arg0].fi_pathname,"blocksBeingWritten")>0/ { @write[fds[arg0].fi_pathname]=sum(arg2); }' ^C
まとめ
このハンズオン・ラボでは、Oracle Solaris Zones、ZFS、ネットワーク仮想化、DTraceなどのOracle Solaris 11のテクノロジーを使用してHadoopクラスタをセットアップする方法について学習しました。
参考資料
- HadoopおよびHDFS
- Hadoopフレームワーク
- "How to Control Your Application's Network Bandwidth"
- "How to Get Started Creating Oracle Solaris Zones in Oracle Solaris 11"
- "How to Set Up a Hadoop Cluster Using Oracle Solaris Zones"
- "How to Build Native Hadoop Libraries for Oracle Solaris 11"
- MapReduce
- WordCount
- "How to Manage ZFS Data Encryption"
- DTrace
著者について
Orgad Kimchiは、Oracle(以前はSun Microsystems)のISVエンジニアリング・チームのPrincipal Software Engineerです。6年間にわたり、仮想化、ビッグ・データ、およびクラウド・コンピューティング・テクノロジーを専門としてきました。
| リビジョン1.0、2013年10月21日 |
false